Applied Mathematics
Vol.5 No.8(2014), Article ID:45711,9 pages DOI:10.4236/am.2014.58119
A Fixed Suppressed Rate Selection Method for Suppressed Fuzzy C-Means Clustering Algorithm
Jiulun Fan1, Jing Li1,2
1School of Communication and Information Engineering, Xi’an University of Posts and Telecommunications, Xi’an, China
2School of Electronic Engineering, Xidian University, Xi’an, China
Email: jiulunf@163.com, lijing5384126@163.com
Copyright © 2014 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


Received 9 March 2014; revised 9 April 2014; accepted 16 April 2014
ABSTRACT
Suppressed fuzzy c-means (S-FCM) clustering algorithm with the intention of combining the higher speed of hard c-means clustering algorithm and the better classification performance of fuzzy c-means clustering algorithm had been studied by many researchers and applied in many fields. In the algorithm, how to select the suppressed rate is a key step. In this paper, we give a method to select the fixed suppressed rate by the structure of the data itself. The experimental results show that the proposed method is a suitable way to select the suppressed rate in suppressed fuzzy c-means clustering algorithm.
Keywords
Hard C-Means Clustering Algorithm, Fuzzy C-Means Clustering Algorithm, Suppressed Fuzzy C-Means Clustering Algorithm, Suppressed Rate

1. Introduction
With the development of computer and network technology, the world has entered the age of big data. As the basic data analysis method, cluster analysis method groups the data unsupervised with the similar characteristics. Since fuzzy set theory was successfully introduced to clustering analysis, it took several important steps until Bezdek reached the alternating optimization (AO) solution of fuzzy clustering, named fuzzy c-means (FCM) clustering algorithm [1] -[3] , which improved the partition performance of the previously existing hard c-means clustering (HCM) algorithm, by extending the membership degree from 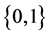 to
to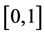 . FCM outperformed HCM in the terms of partition quality, at the cost of a slower convergence. In spite of this drawback, FCM is one of the most popular clustering algorithms. Many researchers have studied the convergence speed and parameter selection of FCM and elaborated various solutions to reduce the execution time [4] -[8] .
. FCM outperformed HCM in the terms of partition quality, at the cost of a slower convergence. In spite of this drawback, FCM is one of the most popular clustering algorithms. Many researchers have studied the convergence speed and parameter selection of FCM and elaborated various solutions to reduce the execution time [4] -[8] .
As another way to speed up the FCM calculations, we proposed an algorithm, named as suppressed fuzzy c-means clustering (S-FCM) algorithm [9] , to reduce the execution time of FCM by improving the convergence speed, while preserving its good classification accuracy. S-FCM established a relationship between the HCM and FCM with the suppressed rate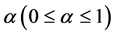 : S-FCM becomes HCM when
: S-FCM becomes HCM when ![]() and FCM when
and FCM when![]() . The S-FCM algorithm is not optimal from a rigorous mathematical point of view, as it does not minimize the objective function. In order to study this problem, Szilágyi et al. defined a new objective function with parameter
. The S-FCM algorithm is not optimal from a rigorous mathematical point of view, as it does not minimize the objective function. In order to study this problem, Szilágyi et al. defined a new objective function with parameter 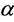 and named it optimally suppressed fuzzy c-means (Os-FCM) clustering algorithm [10] -[12] . Os-FCM clustering algorithm is converged. By numerical tests, they claimed: we cannot take for granted the optimality or nonoptimality of S-FCM, but we can assert that it behaves very similar to an optimal clustering model (Os-FCM).
and named it optimally suppressed fuzzy c-means (Os-FCM) clustering algorithm [10] -[12] . Os-FCM clustering algorithm is converged. By numerical tests, they claimed: we cannot take for granted the optimality or nonoptimality of S-FCM, but we can assert that it behaves very similar to an optimal clustering model (Os-FCM).
The problem of selecting a suitable parameter 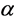 in S-FCM constitutes an important part of implementing the S-FCM algorithm for real applications. The implementation performance of S-FCM may be significantly degraded if the parameter
in S-FCM constitutes an important part of implementing the S-FCM algorithm for real applications. The implementation performance of S-FCM may be significantly degraded if the parameter 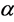 is not properly selected. It is therefore important to select a suitable parameter
is not properly selected. It is therefore important to select a suitable parameter 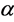 such that the S-FCM algorithm can take on the advantages of the fast convergence speed of the HCM as well as the superior partition performance of the FCM. Huang et al. proposed a modified S-FCM, named as MS-FCM, to determine the parameter
such that the S-FCM algorithm can take on the advantages of the fast convergence speed of the HCM as well as the superior partition performance of the FCM. Huang et al. proposed a modified S-FCM, named as MS-FCM, to determine the parameter 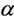 with type-driven learning.
with type-driven learning. 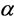 is updated each iteration and successful used in MRI segmentation [13] . And then there are many researchers pay close attention to parameter selection, just like Huang et al. gave Cauchy formula [14] , Nyma et al. gave exponent formula [15] , Li et al. gave fuzzy deviation exponent formula [16] , and Saad et al. gave the clarity formula [17] . However, these selection strategy made the parameter
is updated each iteration and successful used in MRI segmentation [13] . And then there are many researchers pay close attention to parameter selection, just like Huang et al. gave Cauchy formula [14] , Nyma et al. gave exponent formula [15] , Li et al. gave fuzzy deviation exponent formula [16] , and Saad et al. gave the clarity formula [17] . However, these selection strategy made the parameter 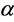 is changed in each iteration. For the fixed selection case, we simple set
is changed in each iteration. For the fixed selection case, we simple set ![]() in the original paper. In this paper, we are further interesting on the fixed selection of
in the original paper. In this paper, we are further interesting on the fixed selection of 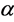 based on the data structure.
based on the data structure.
The remainder of the paper is organized as follows: Section 2 and Section 3 introduce FCM clustering algorithm and S-FCM clustering algorithm respectively. In Section 4, a method to select the parameter 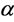 based on the data structure is stated. Section 5 reports experimental analysis on the performances of the new selection method with some related algorithms and the conclusions are presented in Section 6.
based on the data structure is stated. Section 5 reports experimental analysis on the performances of the new selection method with some related algorithms and the conclusions are presented in Section 6.
2. Fuzzy C-Means Clustering Algorithm
FCM is one of the most widely used fuzzy clustering algorithms. It can be presented by the following mathematics programming.
The traditional FCM partitions a set of object data into a number of c clusters based on the minimization of a quadratic objective function. The objective function to be minimized is:
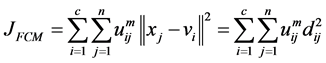 (1)
(1)
where ![]() represents the input data
represents the input data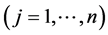 ,
, 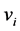 represents the prototype of center value or representative element of cluster
represents the prototype of center value or representative element of cluster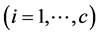 ,
, 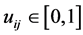 is the fuzzy membership function showing the degree to which vector
is the fuzzy membership function showing the degree to which vector ![]() belongs to cluster i,
belongs to cluster i, ![]() is the fuzzy factor parameter, and
is the fuzzy factor parameter, and ![]() represents the distance between vector
represents the distance between vector ![]() and cluster prototype
and cluster prototype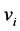 . According to the definition of fuzzy sets, the fuzzy memberships of any input vector
. According to the definition of fuzzy sets, the fuzzy memberships of any input vector ![]() satisfy the probability constraint
satisfy the probability constraint
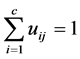 (2)
(2)
The minimization of the objective function 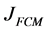 is achieved by alternately applying the optimization of
is achieved by alternately applying the optimization of 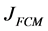 over
over ![]() with
with 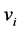 fixed
fixed 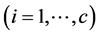 and the optimization of
and the optimization of 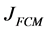 over
over ![]() with
with ![]() fixed
fixed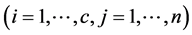 . During each cycle, the optimal values are deduced from the zero gradient conditions, and obtained as follows:
. During each cycle, the optimal values are deduced from the zero gradient conditions, and obtained as follows:
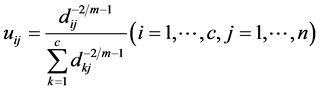 (3)
(3)
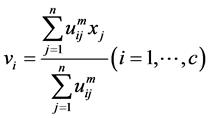 (4)
(4)
According to the AO scheme of the FCM clustering algorithm, Equations (3) and (4) are alternately applied, until cluster prototypes stabilize. This stopping criterion compares the sum of norms of the variations of the prototype vectors 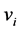 within the latest iteration T, with a predefined small threshold value
within the latest iteration T, with a predefined small threshold value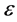 .
.
FCM clustering algorithm:
Sept 1. Fix![]() ,
, ![]() and initialize the c cluster centers
and initialize the c cluster centers 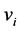 randomly.
randomly.
REPEAT.
Sept 2. Update ![]() by Equation (3).
by Equation (3).
Sept 3. Update 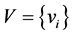 by Equation (4).
by Equation (4).
UNTIL (cluster centers stablized).
3. Suppressed Fuzzy C-Means Clustering Algorithm
The suppressed fuzzy c-means algorithm was introduced in [9] , having the declared goal of improving the convergence speed of FCM, while keeping its good classification accuracy. The algorithm modified the AO scheme of FCM, by inserting an extra computational step between the application of formulae (3) and (4). Considering![]() , if the degree of membership of
, if the degree of membership of ![]() belongs to pth cluster is the biggest of all the clusters, the value is noted as
belongs to pth cluster is the biggest of all the clusters, the value is noted as![]() . After modified, the memberships are:
. After modified, the memberships are:
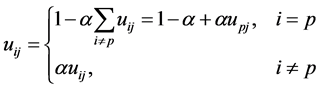 (5)
(5)
The fuzzy memberships are then modified such a way that all nonwinner values are decreased via multiplying by a so-called suppression rate 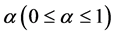 ; and the winner membership is increased accordingly, so that the probability constraint given in Equation (5) is fulfilled by the modified memberships.
; and the winner membership is increased accordingly, so that the probability constraint given in Equation (5) is fulfilled by the modified memberships.
S-FCM clustering algorithm:
Sept 1. Fix![]() ,
, ![]() ,
, ![]() and initialize the c cluster centers
and initialize the c cluster centers 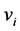 randomly.
randomly.
REPEAT.
Sept 2. Update ![]() by Equation (3).
by Equation (3).
Sept 3. Modify ![]() by Equation (5).
by Equation (5).
Sept 4. Update 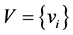 by Equation (4).
by Equation (4).
UNTIL (cluster centers stablized).
4. The Fixed Selection of Suppression Rate α
In the original S-FCM, the suppression rate 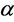 is set the middle of interval, i.e.,
is set the middle of interval, i.e.,![]() , it can be consider a compromise with FCM and HCM. So we think that the better method to select
, it can be consider a compromise with FCM and HCM. So we think that the better method to select 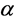 is based on the data distribution structure.
is based on the data distribution structure.
For the data set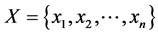 , think of
, think of 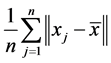 (where
(where 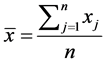 reflects the average distance of all the data points to the mean of data,
reflects the average distance of all the data points to the mean of data, 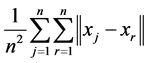 reflects the average distance of all the data points. We have
reflects the average distance of all the data points. We have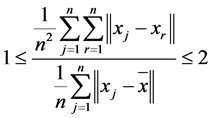 , so we can set
, so we can set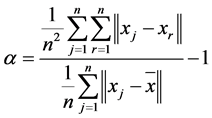 , this makes
, this makes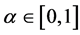 , the proof is written in Appendix.
, the proof is written in Appendix.
5. Experimental Studies
We make experimental studies in this section to show the performances of the new fixed selection method for
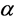 . The S-FCM with
. The S-FCM with 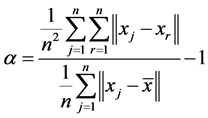 is noted as S-FCM*. We make a comparison of the new approach with some algorithms: FCM, S-FCM. We work with Matlab version 8.0, a computer with 2 processors Genuine Intel of 3.0 GHz frequency, memory 1.0 G and hard disk of 500 G capacity. The parameters we used for these algorithms are: maximal number of iterations T = 200,
is noted as S-FCM*. We make a comparison of the new approach with some algorithms: FCM, S-FCM. We work with Matlab version 8.0, a computer with 2 processors Genuine Intel of 3.0 GHz frequency, memory 1.0 G and hard disk of 500 G capacity. The parameters we used for these algorithms are: maximal number of iterations T = 200, ![]() .
.
5.1. Synthetic Datasets
In this section, we perform some experiments to compare the performances of these algorithms with synthetic datasets. In order to examine and compare the performance of FCM, S-FCM, S-FCM*, the following criterias are used. These are the number of iterations, iteration time until convergence and classification rate. These algorithms are started with the same initial values and stopped under the same condition.
The three artificial datas involves three clusters each with 100 points under multivariate normal distribution are named as data 1, data 2 and data 3 respectively. The parameters used for generating data 1 is: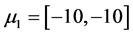 ,
,
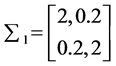 ;
;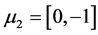 ,
, 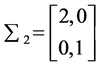 and
and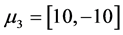 ,
, 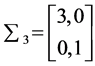 , and is showed in Figure 1. And then, we move the three cluster’s center closer by
, and is showed in Figure 1. And then, we move the three cluster’s center closer by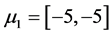 ,
, 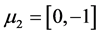 and
and 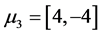 to obtain the data 2 and is showed in Figure 2. Further, we set the three cluster’s center more closer to each others by
to obtain the data 2 and is showed in Figure 2. Further, we set the three cluster’s center more closer to each others by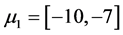 ,
,  and
and 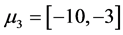 to obtain the data 3 and is showed in Figure 3.
to obtain the data 3 and is showed in Figure 3.
We get the value of ![]() for data 1, the value of
for data 1, the value of ![]() for data 2 and the value of
for data 2 and the value of ![]() for data 3 used for S-FCM*.
for data 3 used for S-FCM*.
In cluster analysis, three important criterions to test the performances of clustering algorithm are iteration number, iteration times (s) and classification rate. For the data 1, three clusters are well-separated, thus a small value of  is hoped, we get the value of
is hoped, we get the value of ![]() for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of FCM, S-FCM and S-FCM* are all 100%. For data 2, we move the clusters closer slightly, thus a slightly larger value of
for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of FCM, S-FCM and S-FCM* are all 100%. For data 2, we move the clusters closer slightly, thus a slightly larger value of  is hoped, we get the value of
is hoped, we get the value of ![]() for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of FCM, S-FCM and S-FCM* are all 97.67%. For data 3, we move the
for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of FCM, S-FCM and S-FCM* are all 97.67%. For data 3, we move the
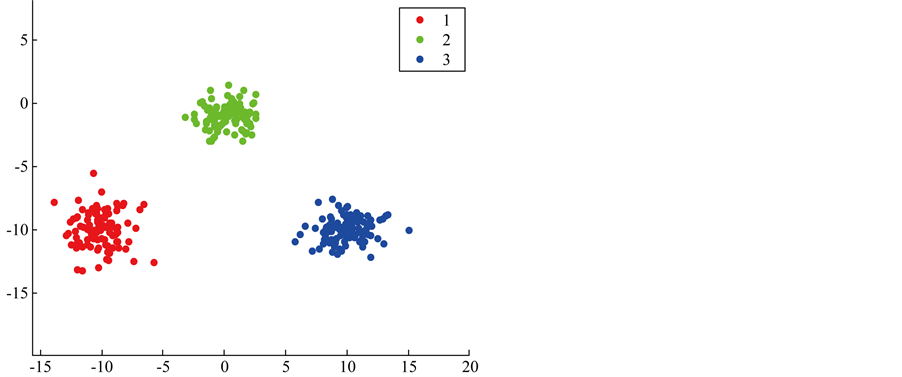
Figure 1. The plot of data 1.
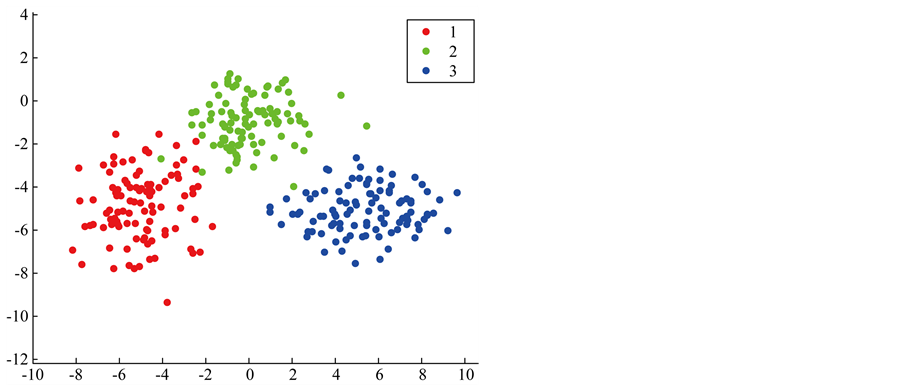
Figure 2. The plot of data 2.
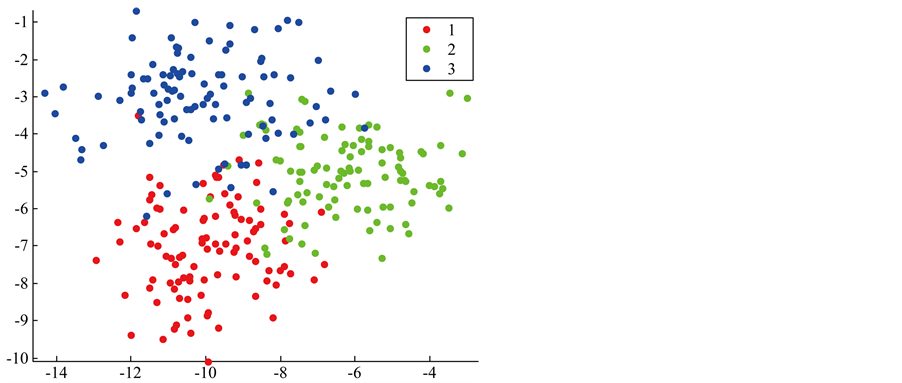
Figure 3. The plot of data 3.
clusters more closer each other, thus a larger value of 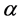 is hoped, we get the value of
is hoped, we get the value of ![]() for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of S-FCM and S-FCM* are all 89%, which is better than the classification rate of FCM with 88.33%. The fuzzy factor m = 2 and m = 10 are used to compare the results.
for S-FCM*. It had shown in Table 1 that S-FCM* has minimum iteration number and iteration times (s), and the classification rate of S-FCM and S-FCM* are all 89%, which is better than the classification rate of FCM with 88.33%. The fuzzy factor m = 2 and m = 10 are used to compare the results.
As supported by the experiments, it indicates that S-FCM* improves the convergence speed while preserving its good classification accuracy compared with S-FCM.
5.2. UCI Machine Learning Datasets
In this section, we perform experiments on a number of UCI Machine Learning data sets [18] , which is Iris, Wine, Ionosphere, Sonar, GCM_efg and Leukemia. Iris plants data is the best-known data sets to be found in pattern recognition literature. The iris consists of 150 label vectors of four dimensions. Wine data consists of 178 label vectors of 13 dimensions. Ionosphere data consists of 351 vectors of 34 dimensions. Sonar data consists of 208 vectors of 60 dimensions. GCM_efg and the Leukemia are high-dimensional data sets. GCM_efg data consists of 43 vectors of 16,063 dimensiona and Leukemia data consists of 72 vectors of 7129 dimensions. We test the performances hundred times, average result (iteration number, iteration times and classification rate) are given in Table 2.
To compute the suppressed rate of S-FCM*, we get the value of ![]() for the Iris data;
for the Iris data; ![]() for the
for the

Table 1. Computational performances of FCM, S-FCM and S-FCM*.
Wine data; ![]() for the Ionosphere data;
for the Ionosphere data; ![]() for the Sonar data;
for the Sonar data; ![]() for the GCM_efg data and
for the GCM_efg data and ![]() for the Leukemia data.
for the Leukemia data.
For Iris data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of S-FCM and S-FCM* are all 88.67%, which is better than the classification rate of FCM with 88%. For Wine data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of S-FCM and S-FCM* are all 69.54%, which is better than the classification rate of FCM with 68.54%. For Ionosphere data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of S-FCM and S-FCM* are all 70.66%, which is better than the classification rate of FCM with 69.8%. For GCM_efg data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of S-FCM and S-FCM* are all 74.42%, which is better than the classification rate of FCM with 69.77%. For Leukemia data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of S-FCM and S-FCM* are all 87.5%, which is better than the classification rate of FCM with 69.44%. For Sonar data, we can seen that that S-FCM* has minimum iteration number and iteration times (s) on average means, and the classification rate of FCM and S-FCM* are all 55.77%, which is better than the classification rate of S-FCM with 55.29%, this means that set ![]() don’t always a good selection. The fuzzy factor m = 2 and m = 10 are used to compare the results.
don’t always a good selection. The fuzzy factor m = 2 and m = 10 are used to compare the results.
6. Conclusion
In this paper we propose a fixed suppressed rate selection method for suppressed fuzzy c-means clustering
Table 2. The average number of computational performances of FCM, S-FCM, S-FCM* with 100 runs.
algorithm called S-FCM*, the method to select the fixed suppressed rate by the structure of the data itself. The experimental results show that the proposed method is a better way to select the suppressed rate in suppressed fuzzy c-means clustering algorithm. The S-FCM* improves the convergence speed, while preserving its good classification accuracy on average sense.
Acknowledgements
This work is supported by the National Science Foundation of China (Grant No. 61340040).
References
- Bezdek, J.C. (1981) Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum Press, New York. http://dx.doi.org/10.1007/978-1-4757-0450-1
- Yu, J. and Yang, M.-S. (2005) Optimality Test for Generalized FCM and Its Application to Parameter Selection. IEEE Transactions on Fuzzy Systems, 13, 164-176. http://dx.doi.org/10.1109/TFUZZ.2004.836065
- Cannon, R.L., Dave, J.V. and Bezdek, J.C. (1986) Efficient Implementation of the Fuzzy c-Means Clustering Algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 8, 248-255. http://dx.doi.org/10.1109/TPAMI.1986.4767778
- Hathaway, R.J. and Bezdek, J.C. (1995) Optimization of Clustering Criteria by Reformulation. IEEE Transactions on Fuzzy Systems, 3, 241-245. http://dx.doi.org/10.1109/91.388178
- Kolen, J.F. and Hutcheson, T. (2002) Reducing the Time Complexity of the Fuzzy c-Means Algorithm. IEEE Transactions on Fuzzy Systems, 10, 263-267. http://dx.doi.org/10.1109/91.995126
- Kwok, T., Smith, K., Lozano, S. and Taniar, D. (2002) Parallel Fuzzy c-Means Clustering for Large Data Sets. EuroPar 2002 Parallel Processing, Springer, Berlin, 365-374. http://dx.doi.org/10.1007/3-540-45706-2_48
- Lázaro, J., Arias, J., Martín, J., Cuadrado, C. and Astarloa, A. (2005) Implementation of a Modified Fuzzy c-Means Clustering Algorithm for Real-Time Applications. Microprocessors and Microsystems, 29, 375-380. http://dx.doi.org/10.1016/j.micpro.2004.09.002
- Cheng, T.W., Goldgof, D.B. and Hall, L.O. (1998) Fast Fuzzy Clustering. Fuzzy Sets and Systems, 93, 49-56. http://dx.doi.org/10.1016/S0165-0114(96)00232-1
- Fan, J., Zhen, W. and Xie, W. (2003) Suppressed Fuzzy C-Means Clustering Algorithm. Pattern Recognition Letters, 24, 1607-1612. http://dx.doi.org/10.1016/S0167-8655(02)00401-4
- Szilágyi, L., Szilágyi, S.M. and Benyo, Z. (2010) Analytical and Numerical Evaluation of the Suppressed Fuzzy c-Means Algorithm: A Study on the Competition in c-Means Clustering Models. Soft Computing, 14, 495-505. http://dx.doi.org/10.1007/s00500-009-0452-y
- Szilágyi, L., Szilágyi, S.M. and Benyo, Z. (2008) Analytical and Numerical Evaluation of the Suppressed Fuzzy c-Means Algorithm. Lecture Notes in Computer Science, 5285, 146-157. http://dx.doi.org/10.1007/978-3-540-88269-5_14
- Szilágyi, L., Szilágyi, S.M. and Benyo, Z. (2008) A Thorough Analysis of the Suppressed Fuzzy C-Means Algorithm, Progress in Pattern Recognition, Image Analysis and Applications. Lecture Notes in Computer Science, 5197, 203-210. http://dx.doi.org/10.1007/978-3-540-85920-8_25
- Hung, W.L., Yang, M.S. and Chen, D.H. (2006) Parameter Selection for Suppressed Fuzzy C-Means with an Application to MRI Segmentation. Pattern Recognition Letters, 27, 424-438. http://dx.doi.org/10.1016/j.patrec.2005.09.005
- Hung, W.-L. and Chang, Y.-C. (2006) A Modified Fuzzy C-Means Algorithm for Differentiation in MRI of Ophthalmology, Modeling Decisions for Artificial Intelligence. Lecture Notes in Computer Science, 3885, 340-350. http://dx.doi.org/10.1007/11681960_33
- Nyma, A., Kang, M., Kwon, Y.-K., Kim, C.-H. and Kim, J.-M. (2012) A Hybrid Technique for Medical Image Segmentation. Journal of Biomedicine and Biotechnology, 2012, Article ID: 830252. http://dx.doi.org/10.1155/2012/830252
- Li, Y. and Li, G. (2010) Fast Fuzzy c-Means Clustering Algorithm with Spatial Constraints for Image Segmentation, Advances in Neural Network Research and Applications. Lecture Notes in Electrical Engineering, 67, 431-438. http://dx.doi.org/10.1007/978-3-642-12990-2_49
- Saad, M.F. and Alimi, A.M. (2010) Improved Modified Suppressed Fuzzy C-Means. 2nd International Conference on Image Processing Theory, Tools and Applications (IPTA), Paris, 7-10 July 2010, 313-318.
- http://www.ics.uci.edu/
Appendix
Theorem: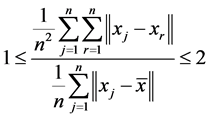 .
.
Proof: For the data set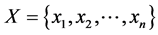 , we have
, we have![]() , where
, where 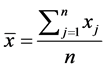 . Thus
. Thus
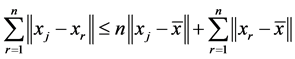
and
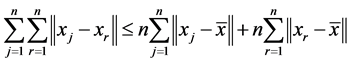 .
.
That is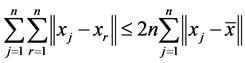 .
.
This means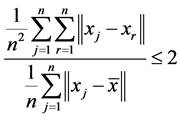 .
.
In other side,
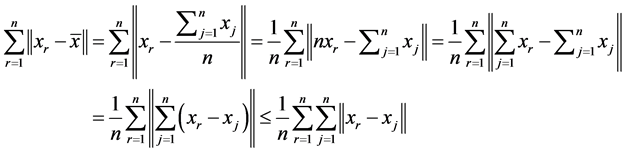
This means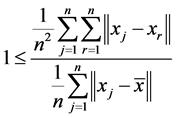 .
.