Data Integrity Checking Protocol with Data Dynamics in Cloud Computing ()
1. Introduction
Recently, many works focus on providing remote data integrity checking protocols. Because storing data in the cloud has become a trend and an increasing number of clients store their important data in remote servers in the cloud, without leaving a copy in their local computers. Sometimes the data stored in the cloud is so important that the clients must ensure it is not lost or corrupted. Using a remote data integrity checking protocol, the client might be able to periodically verify that whether the data stored on the server side is complete. Any corruption will be noticed by the data owner who will be able to take immediate action.
Remote data integrity checking protocols have been proposed in the last few years and two recent results [1] Provable Data Possession (PDP) [2]-[14] and Proofs of Retrievability (POR) [15] have highlighted the importance of the problem and suggested two very different approaches. Ateniese et al. [2] first defined the notion of PDP, which allows a client to verify the integrity of its data stored at an un-trusted server without retrieving the entire file. Their scheme is designed for static data and used public key-based homomorphic tags for auditing the data file. Nevertheless, the pre-computation of the tags imposes heavy computation overhead that can be expensive for entire file. Subsequently, Ateniese et al. [3] constructed scalable and efficient schemes using symmetric keys in order to improve the efficiency of verification. This results in lower overhead than their previous scheme. The scheme partially supports dynamic data operations; however, it is not publicly verifiable and is limited in number of verification requests. Thereafter, several works were done following the models given in [2] [3]. Wang et al. [4] combined a BLS-based homomorphic authenticator with a Merkle hash tree to achieve a public auditing protocol with fully dynamic data. Recently, Mao Jian et al. [5] proposed the detection data of dynamic cloud using Merkle tree, the results show that this method is very effective. Erway et al. [6] proposed a fully dynamic PDP scheme based on rank-based authenticated dictionary. Unfortunately, their system is very inefficient. Hao Zhuo’s protocols [7] support data dynamics and public verifiability, but the calculation of this protocol and the number of blocks have a direct relationship, the amount of computation is still relatively large. After that Wei Xu et al. [8] proposed a remote storage integrity checking protocol based on homomorphic hash function, but the disadvantage of this protocol is losing feature of public verifiability. Zhu et al. [9] created a dynamic audit service based on fragment structure, random sampling and index-hash table that supports timely anomaly detection. Recently, Chun- ming Tang et al. [10] propose a new publicly verifiable method based on linearly homomorphic cryptography.
As a summary of the outstanding protocols: a protocol which satisfies the following requirements ought to be called a perfect protocol: [11] [12]
1) The amount of communication, Storage and computation required by the protocol should be low.
2) It ought to be possible to run the verification an unlimited number of times.
3) It supports dynamic operations include modification, deletion, insertion and append.
4) It supports privacy protection.
5) It supports public verifiability.
6) The changed data can be recovered.
7) It is suitable for large data integrity detection.
Current protocols can not meet all the above requirements. In this paper, the proposed protocol satisfies the above mentioned (1, 2, 3, 4, 5, 7). We have the following main contributions:
1) We propose a remote data integrity checking protocol for cloud storage, and the proposed protocol inherits the support of data dynamics from [3].
2) We give a security analysis of the proposed protocol which shows that it is secure against the un-trusted server
3) We have theoretically examined the performance and the results demonstrate that our protocol is efficient.
The rest of this paper is organized as follows: The new data possession checking protocol is described in Section2. Security analysis of the proposed protocol is presented in Section3. In section 4 we describe the support of data dynamics of the proposed protocol. Analysis of the proposed protocol is presented in Section5. Section 6 is a conclusion.
2. The New Data Integrity Checking Protocol
We consider a cloud storage system in which there is a client and an un-trusted server. The client stores her data in the server without keeping a local copy. Hence, it is of critical importance that the client should be able to verify the integrity of the data stored in the remote un-trusted server. If the server modifies any part of the client’s data, the client should be able to detect it; furthermore, any third-party verifier should also be able to detect it. In case a third-party verifier verifies the integrity of the client’s data, the data should be kept private against the third-party verifier.
In this scheme, we add the agreement stage between the client and the server, thus the use of probability select detection data reduces the computation both of the server and the verifier. The proposed protocol consists of five phases: Setup, Giggen, Agreement, Challenge and Verification.
Notice:
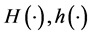 ―cryptographic hash function. In practice, we use standard hash functions.
―cryptographic hash function. In practice, we use standard hash functions.
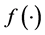 ―pseudo-random function.
―pseudo-random function.
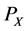 ―the probability that can ensure the detection of the changed data blocks.
―the probability that can ensure the detection of the changed data blocks.
t―assume that the number of data blocks that have been changed.
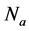 ―random number.
―random number.
Setup: Firstly, given the security parameter k, client run the key generation algorithm and returns a pair of matching public key pk and the secret key sk. pk is public to everyone, while sk is kept secret by the client. Then, the client selects random number generation function 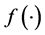 and a authentication index r. The m denote the file that will be stored in the un-trusted server, which is divided into n blocks of equal lengths:
and a authentication index r. The m denote the file that will be stored in the un-trusted server, which is divided into n blocks of equal lengths: 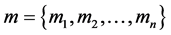
SigGen: The client computes the verification tag for each block: 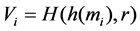 ,
, 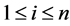 , then using the secret key
, then using the secret key 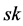 to encrypt the tag
to encrypt the tag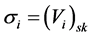 ,
, 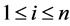
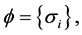 represents a collection of all tags and sends
represents a collection of all tags and sends 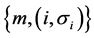 to the server.
to the server.
Agreement: The client sends the probability information of the data blocks to be detected to the verifier: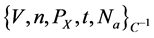 . The verifier receives the information and then uses the public key of the client to decrypt information and calculate to be detected for a data block c after decryption, then sends
. The verifier receives the information and then uses the public key of the client to decrypt information and calculate to be detected for a data block c after decryption, then sends 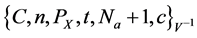 to the client. The client received the message and decried it, so he can ensure that the verifier had received the message from him.
to the client. The client received the message and decried it, so he can ensure that the verifier had received the message from him.
Challenge: The verifier selects c data blocks to be detected, and at the same time, the random challenge nonce 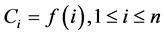 is calculated for each data block. Then the verifier sends
is calculated for each data block. Then the verifier sends 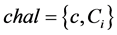 to the server.
to the server.
Verification: Having received the message from verifier, server computes 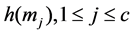 and
and
![]()
The server then retrieves ![]() and returns
and returns ![]() to verifier who, in turn, decrypt
to verifier who, in turn, decrypt ![]() where
where![]() , then compute
, then compute ![]() and
and![]() . The verifier checks whether
. The verifier checks whether![]() . If the check succeeds, the function outputs “success”, otherwise the function outputs “failure”.
. If the check succeeds, the function outputs “success”, otherwise the function outputs “failure”.
The following is the protocol flow Chart 1.
3. Security Analysis
Security means that the protocol is secure against the un-trusted server and is private against third-party verifiers. Client should not be able to pass verification unless it has access to complete unaltered version of m. Firstly, we think the remote server is not trusted; he can intentionally or unintentionally change the client’s data.
Lemma 1. This probability is negligible for a secure hash function, the attacker X is able to successfully find m' which with known file m has a function of the same value and is different from m:
![]()
Chart 1. Protocol flow chart.
![]()
Theorem 1. The proposed protocol uses secure hash functions![]() ,
, ![]() and secure private key encryption scheme, according to the lemma 1, it is known that the attacker X can tamper with the data and the probability of success is negligible.
and secure private key encryption scheme, according to the lemma 1, it is known that the attacker X can tamper with the data and the probability of success is negligible.
Proof. Assume that the un-trusted server has taken the ![]() tampering with
tampering with ![]() in the query results, then he computes
in the query results, then he computes![]() ,
, ![]() , according to the above lemma
, according to the above lemma![]() . So it is the same as
. So it is the same as ![]() by the nature of the hash function. Therefore, the attacker can tamper with the data and the probability of success is negligible.
by the nature of the hash function. Therefore, the attacker can tamper with the data and the probability of success is negligible.
It is important to note that in the verification phase of the verifier decrypts![]() , the probability of obtaining the message
, the probability of obtaining the message ![]() is negligible, thus this protocol support third-party security verification
is negligible, thus this protocol support third-party security verification
Then for the security of the agreement phase, the message is sent through the private key signature and the probability of the adversary’s forgery signature is very small. Furthermore the message does not involve secret information. Agreement stage is only to ensure that the certification is received by the main body of the test will, so as to carry out data integrity testing.
4. Data Dynamics
Now we show how our scheme explicitly and efficiently handle fully dynamic data operations including data modification (M), data insertion (I), data deletion (D) and data append (A) for cloud data storage. Note that in the following descriptions for the protocol design of dynamic operation, we assume that the file ![]() and the signature
and the signature ![]() have already been generated and properly stored at server. The update operation is illustrated in Algorithm 1.
have already been generated and properly stored at server. The update operation is illustrated in Algorithm 1.
![]()
4.1. Data Modification
We start from data modification, which is one of the most frequently used operations in cloud data storage. A basic data modification operation refers to the replacement of specified blocks with new ones.
Suppose the client wants to modify the i-th block ![]() to
to![]() , first the client generates the corresponding signature
, first the client generates the corresponding signature![]() .Step completely in accordance with the above update algorithm, the update request message here is “
.Step completely in accordance with the above update algorithm, the update request message here is “![]() ” and sends it to the server, where M denotes the modification operation.
” and sends it to the server, where M denotes the modification operation.
Upon receiving the request, the server runs
![]() . Specifically, the server replaces the block
. Specifically, the server replaces the block ![]() with
with ![]() and
and ![]() with
with![]() , then computes
, then computes![]() . Finally, the server responses the client with a proof for this operation
. Finally, the server responses the client with a proof for this operation![]() . After receiving the proof for modification operation from server, the client first decrypts
. After receiving the proof for modification operation from server, the client first decrypts![]() , then checks whether
, then checks whether
![]() . If it is not true, output FALSE, otherwise output TRUE.
. If it is not true, output FALSE, otherwise output TRUE.
4.2. Data Insertion
Data is inserted into the existing block in the operation are exactly the same with data modification. For the insertion of a single data block, this paper considers that the data files in a data block can be assigned to one or more existing data blocks and also can perform data modification operations.
4.3. Data Deletion
Data deletion is just the opposite operation of data insertion. Suppose the server receives the update request for deleting block mi, it will replace the block mi with DBlock, which DBlock is a fixed special block that represents deleted blocks. The details of the protocol procedures are similar to that of data modification and insertion, which are thus omitted here.
4.4. Data Append
Compared to data modification, data append does not change steps. The difference of additional data and data update is that you need to add new data blocks we call it ![]() where
where![]() , so the corresponding update request message is “
, so the corresponding update request message is “![]() ”, where A denotes the modification operation. Then the verification process behind the validation process and the data modification operation is exactly the same, so here it is no longer duplicated.
”, where A denotes the modification operation. Then the verification process behind the validation process and the data modification operation is exactly the same, so here it is no longer duplicated.
5. Analysis of the Proposed Protocol
Our scheme is based entirely on un-symmetric key cryptography. In this section we list the features of our proposed scheme and make a comparison of our scheme and state-of-the-art. It is worth noting that we denote pseudo random number generation and addition in the corresponding fields as prng and add.
5.1. Computational Cost
Server side. During verification, the server computes c hash integers![]() . Then, it computes the value
. Then, it computes the value![]() . The computation of each
. The computation of each ![]() corresponds to the product of two integers being t and h bits long. So we obtain the upper bound on the server’s computation time:
corresponds to the product of two integers being t and h bits long. So we obtain the upper bound on the server’s computation time:
![]()
Verifier side. Except for additional pseudorandom num-ber generations corresponding to the challenge, the cost analysis of computing ![]() is similar to that on the client side. Therefore, the verifier computation time is upper bounded by
is similar to that on the client side. Therefore, the verifier computation time is upper bounded by
![]()
The computation cost for server and verifier, though slightly higher, is still very reasonable. This does not include the time for the verifier of the data blocks to be detected, since the computation of the c requires only a very small mathematical calculation.
5.2. Storage Cost
Notice that each token is the output of a cryptographic hash function, so its size is small.
Server side. In line with the purpose of the protocol, the server has to store the complete data m and![]() , whose bitlength is
, whose bitlength is ![]() bits
bits
Verifier side. The storage requirements for the verifier are only a pk, which was used in the verification phase.
5.3. Communication Cost
The communication cost consists of the challenge sent by the verifier to the server, with constant bitlength ![]() bits, and the response sent by the server to the verifier, with constant bitlength
bits, and the response sent by the server to the verifier, with constant bitlength ![]() bits. It is critical to notice that the communication consumption which is ignored here in the agreement phase is very small.
bits. It is critical to notice that the communication consumption which is ignored here in the agreement phase is very small.
5.4. Comparison with Selected Previous Protocols
We now compare our scheme with some existing schemes in terms of communication cost, computation cost on ser- ver side, computation cost on verifier side and storage cost on verifier side. For simplicity, here we denote them as Comm.cost, Comp.cost(S), Comp.cost(V), Storage.cost(V), respectively. Data dynamics and public verifiability are also listed in the table. Table 1 indicates that the proposed protocol is really minimal overhead. You should note that n denotes all the blocks.
6. Conclusion
In this paper, we propose a new remote data integrity checking protocol for cloud storage. We extend the PDP model [3] by changing the generation method of the signature. The proposed protocol supports data level dynamics and public verifiability. Meanwhile, it is desirable to minimize the file block accesses, the
![]()
Table 1. Comparisons between the proposed protocol and previous protocols.
computation on the server and the client-server communication. We expect that the salient features of our scheme make it attractive for realistic applications.
Acknowledgements
This work was supported by the Natural Science Foundation of China (61163001).