Morpho-Syntactic Tagging of Text in “Baoule” Language Based on Hidden Markov Models (HMM) ()
1. Introduction
Each language has its own syntax. That of language “Baoule” is not that of the French and vice versa. In this article we are trying to answer the following question: How to bring out the structure of a given sentence to recognize and understand its contents? Indeed a sentence has meaning only when it is syntactically and semantically correct. The sentence will therefore be considered recognized. The syntactic analysis puts additional strain on the recognition system so that the studied paths correspond to words in the lexicon “Baoule” (lexical decoding), and for which, words are in proper sequence as specified by a sentence pattern. Such a model of sentence may again be represented by a deterministic finite network, or by a statistical grammar [1] . For some tasks (command, control processes), one word of a finite set must be recognized and so the grammar is either trivial or useless [2] . For other applications (e.g., sequences of numbers), very simple grammars are often sufficient (for example, a figure can be discussed and followed by a number) [3] . Finally, there are tasks that the grammar is a dominant factor. It significantly improves the performance of recognition. The Semantic Analysis adds additional stress to all the recognition search path. One of the ways the semantic constraints are used is carried out by means of a dynamic model [4] . Depending on the condition of recognition, some syntactically correct input channels are eliminated from consideration.
This again serves to make easier the recognition task and leads to a better system performance. In Côte d’Ivoire, the French as official language is not always spoken by the entire population. Some local languages like the “Bambara” (Malinké) and especially “Baoule” language emerge, but fail to address the concerns of people who today have to do with the evolution of digital technologies without always under- standing or speaking the conveying languages. Our research work offer goes beyond what is currently available and will allow a person speaking only “Baoule” language to receive and understand “Baoule” language communication expressed in French.
2. Research Question
What is the probability that a sentence in “Baoulé” language is recognized correctly? The linguistic model we propose to build in this section will help us answer this question.
2.1. System Overview
Syntactic categories
Consider the following labels representing the syntactic categories in language “Baoule”: N = name; V = Word; P = preposition; ADV = adverb; ADJ = adjective; D = Determinant; etc.
We want to build a system that will input a sequence of words 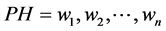 and will output a sequence of labels
and will output a sequence of labels 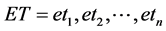 (Figure 1).
(Figure 1).
Input is: S = “le professeur parle”
Output is: D N V (le/D professeur/N parle/V)
Some elements of “Baoule” grammar
The semantic categories of time and appearance match in the conjugation of “Baoulé” to different morphological phenomena. The grammatical expression mode only involves the tone. Expression of aspectuality involves affixes, as time has no direct expression in the context of the combination (see [1] for more detail on the elements of grammar).
![]()
Figure 1. System using the linguistic model.
2.2. The Part-of-Speech Tagging
A label corpus is a corpus in which are associated to text segments (usually words) other information of any kind be it morphological, syntactic, semantic, prosodic, critical, etc. [2] [3] . In particular, in the community of automatic natural language processing, when talking of tag corpus it is most often referred to a document in which each word has a morphosyntactic tag and a single. The automatic labeling morphosyntactic is a process that is usually done in three stages [4] [5] : the segmentation of text into tokens, the a priori labeling disambiguation which assigns to each lexical unit and depending on its context, relevant morphosyntactic tag. The size of the label set and the size of the training corpus are important factors for good performance of the labeling system [6] [7] . In general, there are two methods for part-of-speech tagging: rule-based method [7] [8] and the probabilistic method. In this article we have used the second approach.
3. Methodology
The choice of the most likely label at a given point is in relation to the history of the last labels which have just been assigned. In general this history is limited to one or two previous labels. This method assumes that we have a training corpus which must be of sufficient size to allow a reliable estimate of probabilities [9] .
3.1. Hidden Markov Model (HMM) Taggers
We have an input sentence  (
(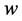 is the i’th word in the sentence).
is the i’th word in the sentence).
We have a tag sequence 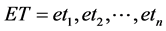 (
is the i’th tag in the sentence).
(
is the i’th tag in the sentence).
We’ll use an HMM to define 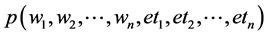 for any sentence
for any sentence 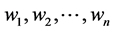 and tag sequence
and tag sequence  of same length.
of same length.
Then the most likely tag sequence for ET is
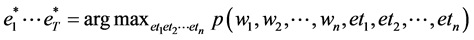
3.2. Trigram Hidden Markov Models (Trigram HMMs)
Basic definition
For any sentence  (where
(where 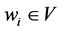 for
for 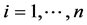 ) and any tag sequence
) and any tag sequence
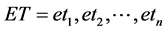
(where 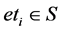 for
for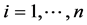 ) and
) and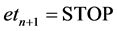 , the joint probability of the sentence and tag sequence is:
, the joint probability of the sentence and tag sequence is:
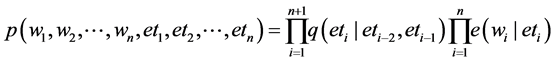
where we have assumed that ![]()
Parameters of the model:
![]() for any
for any ![]() (Trigram)
(Trigram)
![]() for any
for any ![]() (Emission Parameter)
(Emission Parameter)
Example:
If we have![]() ,
, ![]() equal to the sentence “le professeur parle”, and
equal to the sentence “le professeur parle”, and ![]() equal to the tag sequence DNV STOP, then
equal to the tag sequence DNV STOP, then
![]()
STOP is a special tag the t terminates the sequence.
We take![]() , where
, where ![]() is a special “padding” symbol.
is a special “padding” symbol.
Why the Nane “HIDDEN MARKOV MODEL”
![]()
![]() →Markov chain
→Markov chain
![]() →Are observed
→Are observed
Parameter estimation
Learning is a necessary operation to a pattern recognition system (in particular the labeling system); it can estimate the parameters of the model. Improper or inadequate learning decreases the performance of the labeling system. To prepare the training corpus, we proceed by successive approximations. A first training corpus, relatively short, makes it possible to label a much larger corpus. This is corrected, allowing to re- estimate the probabilities, and thus serves to second learning, and so on. In general there are three estimation methods of these parameters:
The estimation by maximum likelihood (Maximum Likelihood Estimation), it is carried by the Baum-Welch algorithm [10] or the Viterbi algorithm [11] .
The maximum estimate by post [12] .
The estimate by maximum of mutual information [13] [14] .
In our case we have used the maximum likelihood estimate because it is the most used and easiest to compute.
![]()
![]() and for all i,
and for all i, ![]()
![]()
![]() (Trigram)
(Trigram)
![]() (Bigram)
(Bigram)
![]() (Unigram)
(Unigram)
![]() for all y if x is never seen in the training data.
for all y if x is never seen in the training data.
3.3. The Viterbi Algorithm
Problem: For an input ![]() find
find
![]()
where the arg max in taken over all sequences ![]() such that
such that ![]() for
for ![]() and
and ![]()
We assume that p again takes the form
![]()
Recall that we have assumed in this definition that ![]() and
and ![]()
Algorithm:
Define n to be the length of the sentence ![]()
Define ![]() for
for ![]() to be the set of possible tag at position k:
to be the set of possible tag at position k:
![]() ;
; ![]() for
for ![]() (for example
(for example![]() )
)
Define
![]()
Define a dynamic programming table ![]() = maximum probability of a tag sequence ending in tag u, v at position k that is:
= maximum probability of a tag sequence ending in tag u, v at position k that is:
![]()
Example
![]()
![]()
A Recursive Definition
Base case ![]()
Recursive Definition
For any ![]() ; for any
; for any ![]() and
and![]() :
:
![]()
4. Experimentation
Learning Data
The experimental work was carried out in three steps:
Setting the label set and learning corpus construction.
Estimate the parameters of the hidden Markov model.
Automatic labeling and re-estimation of parameters of the hidden Markov model.
The definition of the set of morphosyntactic tags is particularly delicate; this phase is carried out in collaboration with linguists. This set of labels consists of several morpho- syntactic labels. The training corpus consists of a set of sentences representing the major morphological and syntactic rules used in “Baoule” language in general.
Results
The error rate is measured on two sets (Table 1):
Set 1 consists of the same phrases in the training set but without labels,
Set 2 consists of phrases (without labels) different from the training set.
Note that in the case of unvowelized texts the error rate increases in relation with vowelized texts, because of the increase in ambiguity (a word can take several labels). For the remaining errors, they are due to lack of training data (there are words and transitions between labels that are not represented in the training corpus).
5. Conclusions
In analyzing the results, we noticed that the majority of labeling errors are mainly due to lack of learning problem or insufficient data. In our case there are two types of problems of lack of data:
one or more words, part of the sentence to be labeled by this system, do not exist in the lexicon, i.e. we do not have an estimate observation probabilities of the words in all states.
one or more tags have no predecessors in the sentence to be labeled automatically, i.e. we do not have an estimate of the transition probabilities of these labels to all other system labels.
In the continuation of our work, we shall proceed to two solutions to address these two problems.
The first is to introduce a kind of morphological analysis based on morphological forms of words to be able to identify the labels of unknown words. The second is to in-
![]()
Table 1. The automatic labeling error rate.
troduce basic syntactic rules that define the possible transitions between different labels.
That said, and given that nowhere exists to date, tagged corpus of the “Baoulé” language, it was for us, through this research to fill this gap.
Annexe
The Viterbi Algorithm
Input:![]() , parameters
, parameters ![]() and
and ![]()
Initialisation: Set ![]()
Definition: ![]() for
for ![]()
Algorithm:
BEGIN
FOR k = 1 to n DO
FOR ![]() DO
DO
![]()
END
END
RETURN ![]()
END
The Viterbi Algorithm with Backpointers
Input: a sentence![]() , parameters
, parameters ![]() and
and ![]()
Initialisation: Set ![]()
Definition: ![]() for
for ![]()
Algorithm:
BEGIN
FOR k = 1 TO n DO
FOR ![]() DO
DO
![]()
![]()
END
END
Set ![]()
FOR ![]() TO 1 DO
TO 1 DO
![]()
END
RETURN The tag sequence ![]()
END