LPM Density Functions for the Computation of the SD Efficient Set ()
Received 22 October 2015; accepted 23 February 2016; published 26 February 2016

1. Introduction
Stochastic dominance (SD) is a very powerful risk analysis tool. It converts the probability distribution of an investment into a cumulative probability curve. Next, math analysis of the cumulative probability curve is used to determine if one investment is superior to another investment. Stochastic dominance has two major advantages: It works for all probability distributions and it includes all possible risk averse utility assumptions. Its major disadvantage is that an optimization algorithm for selecting stochastically dominant efficient portfolios has never been developed limiting it to a two-step process where 1) the SD analysis is run and 2) the resulting securities are run through a portfolio optimization process. This actually is not too great of an issue because in practice, stochastic dominance can be run on thousands of securities and portfolio optimization algorithms are limited to about 150 securities due to singularity errors.1 In this paper, we propose using a stochastic dominance algorithm using lower partial moments for step (1) and then using mean-semivariance or UPM/LPM algorithm for step (2).2
The use of semivariance or lower partial moment analysis to approximate stochastic dominance has already been suggested. Bey [5] proposes a mean-semivariance algorithm to approximate the second degree stochastic dominance efficient portfolio sets. More importantly, Bawa [1] and Fishburn [2] provide proofs for the equivalence of LPM degrees greater than one to second degree stochastic dominance and for LPM degrees greater than two to third degree stochastic dominance.3
Since stochastic dominance is an analysis of cumulative distribution functions; only below target deviations are considered over the interval [−∞, target] with the target encompassing all values of X. This “for all X” target condition is directly responsible for the generalization to all possible risk averse utility assumptions.
This paper proposes an integration of stochastic dominance analysis and lower partial moment analysis by defining a stochastic dominance (SD) test via the Lower Partial Moments (LPM) of the investment’s probability distribution. From this SD-LPM test, we can quickly and efficiently determine the SD efficient set and generate optimal portfolios from that reduced universe of securities for any objective function (Mean/Variance, UPM/ LPM, etc.). Equation (1) represents the LPM of an investment,
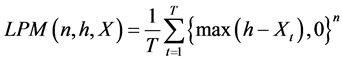 (1)
(1)
where 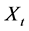 is the observation of variable X at time t; h is the target from which to compute the lower deviation; and n is the loss aversion weight assigned to the lower deviation. The next section explains the equivalence between LPM and SD for First Degree Stochastic Dominance (FSD), Second Degree Stochastic Dominance (SSD) and Third Degree Stochastic Dominance (TSD). In Section 3 we discuss the methodology of the SD routines and the SD efficient set algorithm. The appendices contain R code, commentary on the R code and working examples. In these examples we note the effects of SD on the odd moments of the distributions, consistent with Hadar and Russell [1969] original conclusions.
is the observation of variable X at time t; h is the target from which to compute the lower deviation; and n is the loss aversion weight assigned to the lower deviation. The next section explains the equivalence between LPM and SD for First Degree Stochastic Dominance (FSD), Second Degree Stochastic Dominance (SSD) and Third Degree Stochastic Dominance (TSD). In Section 3 we discuss the methodology of the SD routines and the SD efficient set algorithm. The appendices contain R code, commentary on the R code and working examples. In these examples we note the effects of SD on the odd moments of the distributions, consistent with Hadar and Russell [1969] original conclusions.
2. Historical Partial Moment Equivalence & Tests
Bawa [1] provides a proof that the LPM measure is mathematically related to stochastic dominance for risk tolerance values (n) of 0, 1, and 2. Fishburn [2] demonstrates the equivalence of the LPM measure to stochastic dominance for all values of n > 0. He provides the general case via:
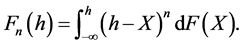 (2)
(2)
Fishburn [2] also shows that the n value includes all types of investor behavior. Furthermore, Porter [10] illustrates that except for cases of identical means and semivariances, if X dominates Y by second degree stochastic dominance then X dominates Y by the mean-target semivariance model. Building from the general case, let 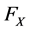 denote the cumulative distribution function of variable X such that:
denote the cumulative distribution function of variable X such that:
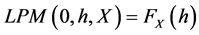 (3)
(3)
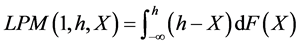 (4)
(4)
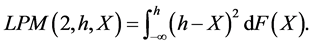 (5)
(5)
Therefore, Equation (3) will be the statistic used for FSD testing, Equation (4) will be the statistic used for SSD testing, and Equation (5) will be the statistic used for TSD testing. We note that Equation (3) is a probability whereby the target deviation is taken to the 0th degree. The LPM degree 0 is simply the empirical cumulative distribution function (CDF) of the distribution. When considering how far a deviation is from its target, increasing the degree per Equation (4) will give a linear weighting. This is the area of the distribution to the left of the target, h. Finally, if an investor is more sensitive to below target observations, increasing the degree further will compensate this behavior. The LPM Degree 2 used in Equation (5) is equivalent to the semivariance statistic. These equations must be used from every target in the return distribution to generalize for all risk-averse investor types.
In a bid to infer SD from aggregate statistics (and skip the every target “for all h” inconvenience), others have suggested various CDF tests to approximate SD results. For example, Klecan et al. [11] proposes a difference in CDFs, per the Kolmogorov-Smirnoff (KS) test, further bolstered by Monte Carlo simulation for robustness. However, the KS test used does not prove FSD or SSD. The test statistic, 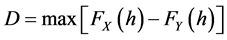 is deficient because it does not satisfy the “for all h” previously alluded to. FSD is a very stringent qualification, whereby one observation in which
is deficient because it does not satisfy the “for all h” previously alluded to. FSD is a very stringent qualification, whereby one observation in which 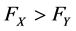 nullifies X FSD Y. What you have is a statistically significant difference in CDFs, which unfortunately does not tell us anything about stochastic dominance. Of course Klecan et al. [11] realize this and alter their hypothesis to test for a variable that is not stochastically maximal, i.e. weak stochastic dominance holds for some pair of prospects within their observed set.
nullifies X FSD Y. What you have is a statistically significant difference in CDFs, which unfortunately does not tell us anything about stochastic dominance. Of course Klecan et al. [11] realize this and alter their hypothesis to test for a variable that is not stochastically maximal, i.e. weak stochastic dominance holds for some pair of prospects within their observed set.
“The set A is first-degree [resp., second-degree] maximal if no prospect in A is weakly stochastically dominated by another prospect in A. First-degree dominance implies second-degree dominance, and second- degree maximality implies first degree maximality.” Klecan et al. [11] .
Developing an efficient routine to determine SD was originally hampered by computing power coupled with arcane techniques. Computing power has increased dramatically since the 1970s, thus enabling portfolio sizes unattainable back then. Furthermore, the use of partial moments are a computationally efficient method of determining CDFs flexible enough for the entire distribution and extending themselves to area analysis required for the higher SD degrees.
“Finally, in order to conduct tests of SSD efficiency, all the calculations required for the FSD test must be made regardless of whether one is interested in FSD results; for TSD experiments, all the calculations required for FSD and SSD tests must be made.” Porter, Wart and Ferguson [12] .
The use of LPMs in the SD test eliminates the calculation redundancy Porter et al. [12] noted above. In fact, TSD takes less time to run than FSD per our routines, the explanation of which follows.
2.1. SD Routines
A complete presentation of the R code and commentary on the modules is presented in the Appendix A and Appendix C of this paper. Here, we are providing a general overview of how each SD routine performs its task on individual securities or aggregate portfolios.
2.1.1. FSD
To determine FSD between two variables we combine the observations into a single vector. Next we rank the observations in ascending order. This is the target vector. Using the combined sorted observations we compare CDFs from each target using Equation (3).
If the 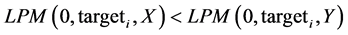 then we store the instance with a binary indicator into an output vector. If at any target the relationship fails, the routine is stopped and the result of “No FSD Exists” is returned. This has the benefit of avoiding all of the observations as soon as a violation is detected. Otherwise we continue through the rest of the target vector until all observations are exhausted, thus affirming “XFSD Y” existence.
then we store the instance with a binary indicator into an output vector. If at any target the relationship fails, the routine is stopped and the result of “No FSD Exists” is returned. This has the benefit of avoiding all of the observations as soon as a violation is detected. Otherwise we continue through the rest of the target vector until all observations are exhausted, thus affirming “XFSD Y” existence.
In an added bid of efficiency we incorporate an additional output vector for Y such that it can be checked simultaneously for “Y FSD X”.
2.1.2. SSD
To determine SSD the same initial combining and ranking procedure is performed on the variables. However, we are no longer comparing CDFs rather areas of the functions up to that specific target point. These areas are compared using Equation (4) which is the degree 1 LPM.
If the 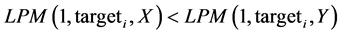 then we store the instance with a binary indicator into an output vector. All of the benefits from the FSD routine are preserved.
then we store the instance with a binary indicator into an output vector. All of the benefits from the FSD routine are preserved.
2.1.3. TSD
Again, using the identical combined sorted observation vector (yet another efficiency since it does not have to be generated for each degree tested) the two variables of interest are compared with their squared areas below a target, or simply their semivariance. Equation (5) represents this consideration.
If the 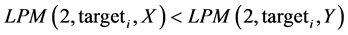 then we store the instance with a binary indicator into an output vector for that specific target. All of the benefits from the FSD and SSD routines are preserved.
then we store the instance with a binary indicator into an output vector for that specific target. All of the benefits from the FSD and SSD routines are preserved.
2.2. SD Efficient Set
Our first step is to rank the securities or portfolios in ascending order by their LPM from the maximum observation across all variables. Using the terms “Base” and “Challenger” from Porter et al. [12] , our first ranked variable is our “Base”. The next ranked variable is the “Challenger”. We test whether “Base” SD “Challenger”. If “Base” SD “Challenger”, then “Challenger” is placed in a “Dominated Set” which is an output vector. If “Base” does not SD “Challenger” then “Challenger” is added to the “Base” vector. The next “Challenger” must be tested against all members of the current “Base” vector. If it fails but one, it is immediately placed in the “Dominated Set” and the next “Challenger” is selected. When all “Challengers” are exhausted, the final SD Efficient Set is simply the original data frame less the “Dominated Set”.
2.3. SD Algorithm Empirical Results
The resulting SD Efficient data frame can then be easily implemented (within the same command line) into an optimization routine. We verify the output from our method versus the DOMIN1 routine originally presented in Porter et al. [12] with the third degree SD correction suggested by Bey, Burgess, and Kearns [13] . We obtained a monthly total return dataset of 67 stocks from the CRSP dataset for the period 2010 to 2014. Summary statistics are provided in Appendix B. We then used the DOMIN1 routine and our R code routine to generate the FSD, SSD, and TSD efficient sets. Indeed the same securities are selected from a 67 security universe. The results for the SSD and TSD analysis are presented in Table 1.
One potential question is whether a simple reward to semivariability (R/SV) ratio ranking would be equivalent to the LPM SD algorithm. Table 1 results indicate the answer is no. We ranked all 67 companies by R/SV ratio with the last column in Table 1 indicating the company’s rank among the 67 companies. For the SSD results, there are 12 undominated companies and only 7 companies are ranked in the top 12 of the R/SV rankings (5 companies are ranked out of the top 12). For the TSD results, there are 9 undominated companies and only 6 companies are ranked in the top 9 of the R/SV rankings (3 are ranked out of the top 12).
3. Discussion
While stochastic dominance implies mean/Semivariance or LPM dominance, LPM dominance does not imply stochastic dominance because of the nature of aggregate statistics versus individual observations. This is analogous to the common phrase: “While dependence implies correlation, correlation does not imply dependence.” The stringent criterion of stochastic dominance defies implication from aggregate distributional statistics.
We have also provided an algorithm for efficiently determining SD efficient portfolios. The use of lower partial moments is consistent with the procedure originally proposed by Porter et al. [12] for rankings by means and
(a) ![]() (b)
(b) ![]()
Table 1. Second and third degree undominated assets from 67 stocks, monthly data from January 2010 to December 2014 using DOMIN1 and our R code. The mean return is a monthly return relative and the Semi Deviation is a monthly percent change. (a) Second degree (SSD) undominated assets; (b) Third degree (TSD) undominated assets.
The Bey-Kearns-Burgess [13] TSD Correction in DOMIN1 Has Been Activated. The Number of Check Points = 6; ITEST = 1; JTEST = 3.
variances. This is verified with a 67 security universe example providing identical outputs for SSD and TSD.
One potential weakness of any empirical risk analysis approach is estimation error. Both SD and LPM are nonparametric and do not require knowledge of the underlying probability function. In simulation tests that we have conducted, the LPM measures are less sensitive to estimation error than either the mean or variance no matter which distribution is assumed.
In order to generalize further, one would have to expand the analysis into an Upper Partial Moment/Lower Partial Moment (UPM/LPM) framework, capable of incorporating the often observed four-fold pattern of risk behavior identified in prospect theory and expected utility theory such as the UPM/LPM optimization model described by Viole and Nawrocki [21] [22] and Cumova and Nawrocki [23] .
4. Conclusions
The close relationship between lower partial moments and stochastic dominance has been known since Porter [10] , Bawa [1] , Fishburn [2] , and Bey [5] . This paper uses the known cumulative density function properties and utility function properties of lower partial moments to generate stochastic dominant efficient sets. We hope that this paper demonstrates how powerful LPM analysis potentially is for statistical/financial analysis (and by extension UPM/LPM analysis). An efficient algorithm to generate SD efficient sets is proposed and tested alongside with the Porter et al. [12] . DOMIN1 algorithm which includes the third degree SD correction is suggested by Bey et al. [13] . Both algorithms provided the same efficient sets for SSD and TSD for a sample 67 security universe. A description of the LPM SD algorithm is provided in Appendix A and the R-code for the algorithm is included in Appendix C.
Future research should extend the analysis to the use of UPM/LPM models which are superior to SD and LPM models for incorporating the full range of utility functions available with expected utility theory and prospect theory.
Appendix A
A.1. R Code Commentary
This section of the paper will provide the R code commentary for the stochastic dominance test using lower partial moments. The code can be found in Appendix C.
1) Module 1: Lower Partial Moment Function (LPM)
The LPM function is a fairly straightforward interpretation of Equation (1) whereby only below target observations are summed and raised to the loss aversion degree (n), and then divided by the number of observations.
2) Module 2: First Degree Stochastic Dominance (FSD)
Section A: Sort the variables in ascending order. Combine the vectors and sort the combined vector. Create output vectors for areas used in plots.
B: Create an output vector to store the instances of CDF inequality.
C: Uses the sorted X and Y variables as the LPM target under n = 0. Thus all observations are used in the stringent “for all h” qualification. If 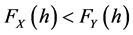 for that observation target h, no instance is recorded into the output vector (output_x[i] < −0). Conversely, if
for that observation target h, no instance is recorded into the output vector (output_x[i] < −0). Conversely, if ![]() for that observation target h, the loop is stopped.
for that observation target h, the loop is stopped.
D: Uses the same logic as (C) above, only tests the inverse CDF relationship![]() .
.
E: Plots the CDFs of each variable.
F: Reads the output vectors. If the output vector has 0 instances of![]() , then X FSD Y.
, then X FSD Y.
G: Test case.
Figure A1 plots the cumulative distributions for all observations of X and Y. The combined sorted vector doubles the length of observations, and thus distorts the image compared to the familiar CDF as plotted in Figure A2 for each variable.
We can see in Figure A1 & Figure A2 the multiple crossing of the CDFs (around the 300th observation and −1 value respectively), thus negating any first degree stochastic dominance between variables. Clearly though, on balance we can see ![]() is more desirable than
is more desirable than![]() .
.
For three h values (−0.99, −0.98, and −0.97)![]() . Outside of those values,
. Outside of those values,![]() . This is where second degree stochastic dominance may offer some insight…
. This is where second degree stochastic dominance may offer some insight…
3) Module 3: Second Degree Stochastic Dominance (SSD)
Section A: Sort the variables in ascending order. Combine the vectors and sort the combined vector. Create output vectors for areas used in plots.
B: Create an output vector to store the instances of area inequality.
C: Uses the sorted X and Y variables as the LPM target under n = 1. Thus all observations are used in the
![]()
Figure A1. Plot of ![]() using all observations of X and Y as targets (h).
using all observations of X and Y as targets (h).
![]()
Figure A2. Typical CDF plot for variables X and Y.
stringent “for all h” qualification. If ![]() for that observation target h, no
for that observation target h, no
instance is recorded into the output vector (output_x[i] < −0). Conversely, if
![]() for that observation target h, the loop is stopped.
for that observation target h, the loop is stopped.
D: Uses the same logic as (C) above, only tests the inverse area relationships
![]() .
.
E: Plots the cumulative areas of each variable.
F: Reads the output vectors. If the output vector has 0 instances of![]() ,
,
then X SSD Y.
G: Test case.
Figure A3 shows the cumulative distribution areas for X and Y. The lower area and thus dominance is quite clear. Alternatively viewed as a histogram, Figure A4 illustrates ![]() for all
for all
positive values (a good thing), while simultaneously ![]() for all negative
for all negative
values (also a good thing). This is evident when examining the skewness between both variables.
Skew(X) Skew(Y)
0.06529391 0.04430945
Nawrocki [4] also finds excess positive skewness for the risk averse investor’s portfolio compared to the maximum mean/variance portfolio. This in turn was expected, due to Hadar and Russell [3] original conclusions:
“For instance, we have indicated in the paper that FSD implies a certain relationship between the odd moments (and sometimes also between the even moments) of the prospects under consideration. Consequently, given that P is preferred to P’ for all monotonic utility functions, we can immediately say that all the odd moments around zero of P are larger than the respective moments of P’.”
Even when dominance interruptions occur in the histogram, the cumulative area to that point is not enough to negate the dominance of X over Y. Revisiting the LPMs from the FSD interval of question tells a different story when areas are compared:
The areas in Table A1 never even really come close to intersecting like the CDFs did in Table A2. This result loosely supports the maximal hypothesis from Klecan et al. [11] ―that the areas would have to be very volatile and crossing in order to negate SSD4, and if that were true, it would of course reflect on the underlying CDFs
![]()
Figure A3. Plot of ![]() using all observations of X and Y as targets (h).
using all observations of X and Y as targets (h).
![]()
Figure A4. Histogram of ![]() using all observations of X and Y as targets (h).
using all observations of X and Y as targets (h).
![]()
Table A1. Areas of variables X, Y over the interval [−1, −0.95].
![]()
Table A2. CDF values for different targets for variables X and Y.
used in FSD.
4) Module 4: Third Degree Stochastic Dominance (TSD)
Section A: Sort the variables in ascending order. Combine the vectors and sort the combined vector. Create output vectors for areas used in plots.
B: Create an output vector to store the instances of (area of the cumulative distribution)2 inequality.
C: Uses the sorted X and Y variables as the LPM target under n = 2. Thus all observations are used in the stringent “for all h” qualification. If ![]() for that observation target h, no
for that observation target h, no
instance is recorded into the output vector (output_x[i] < −0). Conversely, if
![]() for that observation target h, the loop is stopped.
for that observation target h, the loop is stopped.
D: Uses the same logic as (C) above, only tests the inverse area relationships
![]() .
.
E: Plots the cumulative areas squared for each variable.
F: Reads the output vectors. If the output vector has 0 instances of![]() ,
,
then X TSD Y.
G: Test case.
Figure A5 shows the TSD cumulative distribution areas for X and Y. The lower area and thus dominance is
quite clear. Alternatively viewed as a histogram, Figure A6 illustrates ![]() for all positive values (a good thing), while simultaneously
for all positive values (a good thing), while simultaneously ![]() for all negative values (also a good thing).
for all negative values (also a good thing).
A.2. Generalized Stochastic Dominance Efficient Sets
By testing for SD using the final ranks for that SD degree, we can derive the SD efficient sets. If a portfolio is dominated by a higher final ranked one, it is out of the efficient set. Example in Row 5 Column 4:
・ The highest final ranked portfolio is the “Base”. Test the “Base” portfolio against the next highest ranked, the “Challenger”. 4 v 2. No SD exists. 2 joins the “Current Base” vector to run unidirectional5 SD tests from.
・ Test the new “Base” against the next “Challenger”. 2 v 3.2 SD 3. 3 is placed in the “Dominated Set”.
・ Test the new “Base” against the next “Challenger”. 2 is the last entry in the “Current Base”. 2 v 1. No SD
![]()
Figure A5. Plot of ![]() using all observations of X and Y as targets (h). Note the effects of the higher loss aversion (n) on the distribution versus SSD cumulative plot in Figure A3.
using all observations of X and Y as targets (h). Note the effects of the higher loss aversion (n) on the distribution versus SSD cumulative plot in Figure A3.
![]()
Figure A6. Plot of ![]() using all observations of X and Y as targets (h). Note the effects of the higher loss aversion (n) on the distribution versus the SSD histogram in Figure A4.
using all observations of X and Y as targets (h). Note the effects of the higher loss aversion (n) on the distribution versus the SSD histogram in Figure A4.
exists. Test the remaining “Current Base” vector against 1. 4 v 1. No SD exists, 1 joins the “Current Base”.
・ There are no more “Challengers”. Stop the procedure. The SD efficient set is the final ranked set less the “Dominated Set” {4,2,1}.
・ #1 (the largest minimum value) can never be dominated, thus it is in every efficient set.
This procedure is different than that proposed by Porter, Wart and Ferguson [12] in several regards. One difference is that we do not check multiple SD degrees simultaneously6. Our second difference is we determine the final ranking by ordering the LPMs from the maximum of all observations. We substitute the degree 1 LPM final ranking for Porter et al.’s use of means and variances in ranking the securities. Finally, our third difference is the integration of the “Tricks” Porter et al. [12] identified to reduce the computational burden. We use the minimum value check as an “if” condition (“Trick 1”); and {break} commands at the end of each observation if a “Base” falls behind the “Challenger”.
![]()
Figure A7. SD efficient sets (in red), versus ranked securities or portfolios in ascending order by their LPM from the maximum observation across all variables.
Appendix B. Security Listing (Return, StdDev and SemiDev Are in Monthly Percent)
![]()
![]()
Appendix C
R CODE
This section of the paper will provide the R code for the stochastic dominance test using lower partial moments.
1) Module 1: Lower Partial Moment Function (LPM)
![]()
2) Module 2: First Degree Stochastic Dominance (FSD) [Bi-directional]
![]()
3) Module 3: Second Degree Stochastic Dominance (SSD) [Bi-directional]
![]()
4) Module 4: Third Degree Stochastic Dominance (TSD) [Bi-directional]
![]()
5) Module 5: Stochastic Dominance Efficient Set (SDES) & Uni-directional SD Tests
![]()
![]()
![]()
![]()
![]()
NOTES
![]()
1Private correspondence with Harry Markowitz on the limits to the critical line algorithm. Markowitz [6] also recommends geometric mean- semivariance as the appropriate MPT approach.
2See Nawrocki [7] for a review of lower partial moment (LPM) risk measures.
3Although Tehranian [8] and Helms, Jean, and Tehranian [9] suggested stochastic dominance degrees greater than three and the fact is that LPM exists for degrees greater than two, there doesn’t seem to be strong support in the literature for SD degrees greater than three. If we extend the Fishburn [2] and Tehranian [8] analysis, then SD degree four is equivalent to LPM degrees greater than three.
![]()
4Namely that this occurrence is less likely for larger differences in distribution CDFs.
![]()
5The earlier discussed tests were bi-directional, which involves more calculations between variables. Since the efficient sets are determined from unidirectional tests, a significant reduction in steps is realized. The attached code for determining SD efficient sets contains the unidirectional tests returning (1) for SD and (0) otherwise.
![]()
6A simple “for (i in 1:3)…” loop can be implemented to run all three SD tests with degree “i”.