Research on the Geological Sourcing of Raohe Honey by Inductively Coupled Plasma Mass Spectrometry with Primary Composite Analysis and Forecasting Models ()
1. Introduction
Raohe linden honey is collected from the flowers of chaff lindens and purple lindens by northeastern black bees introduced from the east of Wusuli River in the early 20th century. Since 1997, Raohe County has established the national nature reserve for northeastern black bees, which are pure in species. Chaff linden honey and purple linden honey are high in Baume. Northeastern black bees have a good immunity and are almost out of the need of antibiotics; accordingly the problem of veterinary drug residue is fundamentally resolved.
In recent years, Raohe honey has won quite a number of prizes in the domestic and foreign expos for its good quality and hence become preferred by consumers. Meanwhile, however, some traders and producers counterfeit Raohe honeys by packing non-Raohe honey with the packages of Raohe honey; these counterfeited products have not only deceived consumers but also greatly affected the local apiculture. Therefore, geographical origin sourcing and identification technologies are urgently needed for Raohe honey.
The first review about the researches of honey sourcing was a paper about the detection methods of geological and botanical sourcing of honey published in 1998 by Anklam et al. [1] . This paper summarized the methods in terms of the contents of amino acids, carbohydrates, enzymes, volatile compounds, and elements. In 2004, Bogdanov et al. [2] summarized the methods of detecting the physical and chemical parameters of monofloral honey. Later, Arvanitoyannis et al. [3] summarized the analytical techniques and multivariable analytical methods applied in the adulteration detection of honey in terms of the detection of amino acids, physical and chemical parameters, sugars, and elements. In 2007, Cuevas-Glory et al. [4] detailed the methods of the pretreatment and detection of volatile compounds on the basis of systematical research on the detection methods for botanical sourcing of honey. And in 2009, Pohl et al. [5] conducted a comprehensive research on the application of atomic absorption and emission spectrometer on the detection of element contents in honey, discussing the applicability of element contents for the research of botanical and geological sourcing of honey. It can be seen from earlier references that analyzing the element contents in honey followed by sourcing had been an important method in the area of food safety; and isotope analysis had been widely considered one of the most effective techniques [6] . At present, the researches of food origin sourcing technologies are mainly concentrated on two areas: 1) exploring valid parameters for food origin sourcing and providing theoretical and methodological foundations for establishing mineral element sourcing databases or mineral element maps; 2) investigating the variations of the contents of mineral elements in consideration of the factors such as land shapes, climates and geological features.
Sr locates in row 5 and group IIA of the periodic table of elements, having four isotopes: 84Sr, 86Sr, 87Sr and 88Sr, in nature. Though the ratios of Sr isotopes change during the processes of absorption and metabolism in plants and animals just like S, C, H, O and N isotopes do, the content of 87Sr can be used as a target for geological sourcing. The ratio 87Sr/86Sr in plants and animals is affected by the amount of Sr absorbed by living bodies from the ground [7] . The ratios of Sr isotopes are useful indicators for the identification of origins and authenticity of plants and animals. When the contents of d18O and dD are equal in living bodies, which means that the climate variation is insignificant, the effect of Sr isotope ratios identification is satisfactory [8] .
B isotopes present fractionation effects owing to geochemical processes and hence result in variations among the ratios of 11B/10B in rocks, marine sediments and natural waters. Another important mechanism of the
natural fractionation of B isotopes is that the element exchange among boric acid, borate ions and 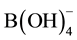
along with the variation of the pH value lead to the concentration of 11B in boric acid. These natural processes might give rises to the d11B value of 9%. Except for natural factors, the spread of chemical fertilizer with boron may also affect the ratio 11B/10B, resulting in great differences in the ratios of 11B/10B among different pieces of ground [9] .
There are four natural isotopes of Pb:204Pb, 206Pb, 207Pb and 208Pb. 204Pb has a half-life of 1.4 × 1017 years which is long enough for it to be regarded as a stable reference isotope; while 206Pb, 207Pb and 208Pb, which always vary in natural abundances, are respectively the end products of the radioactive decay processes of 238U, 235U and 232Th. Because of the differences of periods and contents of U, Th and original Pb, different kinds of natural matter have different compositions of Pb isotopes, becoming their characteristics which are constant in chemical and physical changes. Therefore, the abundance ratios of Pb isotopes can be regarded as the “finger prints” for identifying the origin of Pb, with the advantages of being able to show the possible origin and passing route of Pb and consuming a little amount of sample. Meanwhile, the abundance ratios of Pb isotopes in different areas differ from each other on account of different geological structures, geological ages, mineral contents and precipitations. The metal elements in living bodies mainly come from soil and ground water; therefore, the abundance ratios of Pb isotopes are able to indicate the origin area [10] .
In consideration of the pertinence of the isotopes of the three elements above, this research detected the contents of Sr, B and Pb isotopes in honey and then conducted primary composite analysis with the data analysis software, Agilent Mass Profiler Professional (MPP), on the foundation of the isotope abundance ratios and forecasting models built afterwards. MPP is a powerful chemometric platform aimed at exploring and utilizing massive data information from mass spectroscopy and applying to any differential analysis based on mass spectroscopy for the purpose of determining the relationship between two or more sample groups and variables. The system also provides the functions of automatic sample classifying and forecasting, which have brought about revolutions in the qualitative analysis of unknown samples based on mass spectroscopy among many analytical applications. The MPP software was specially designed for mass spectroscopy specialists and statisticians, with introductory advanced working procedures. It provides broad statistical tools, including ANOVA, PCA, volcano plot, hierarchy tree, SOM, QT cluster analysis and 5 different classifying forecasting methods. Latorre et al. [11] detected the contents of Li, Rb, Na, K, Mg, Zn, Cu, Fe, and Mn in 42 honey samples from Spain (divided into samples from Galicia and the other areas of Spain) with atomic absorption spectrum, and built the judge model of Galicia and non-Galicia honey with the element contents as variables on the foundation of the chemometric methods of cluster analysis (CA), primary composite analysis (PCA), partial least squares regression (PLSR), artificial neural network (ANN), etc. As the result illustrates, the ANN and PLSR methods appear to be better than the others in the classification and forecasting of honey’s geological origins, and the element contents in honey are able to provide enough information for honey’s geological sourcing. In this research, there were five models, i.e. the Decision Tree, Naïve Bayers, Neural Network, Partial Least Square Discriminate and Support Vector Machine models, built on the basis of the isotope abundance ratios detected, after which the models were discussed about and the feasibilities were validated.
2. Materials and Methods
2.1. Apparatus and Reagents
Inductively coupled plasma mass spectrometry (ICP-MS, Agilent, USA) with glass concentric nebulizer and Nickel sampler, with Ar and He as collision gases; MARS Xpress (CEM, USA), Milli-Q Water Purification System.
Sr isotope reference material: NIST987; Pb isotope reference material: NIST981; B isotope reference material: NIST951.
2.2. Samples
166 Raohe honey samples were collected from 7 producers: Heifengyuan (HFY), Raofeng (RF), Dadingshan (DDS), Dajiahe (DJH), Laoyinggou (LYG), Yongxing (YX), and Hongqiling (HQL); 31 non-Raohe honey samples were purchased from different supermarkets.
2.3. Methods
Sample preparation: an appropriate amount of honey was weighted in a centrifuge tube, when conducting ultrasonic process in 50˚C water for at least 30 min until the honey turn into lucid liquid.
Microwave digestion: for each sample pretreated, 0.1 g lucid liquid was weighted, to an accuracy of 0.0001 g, and put into a PTFE digestion tank, which had been cleaned by acid boiling, together with 5 mL concentrated nitric acid and 3 mL hydrogen peroxide. After that, the liquid was digested with heat following a pre-defined procedure. Next, it was cooled to ambient temperature, followed by opening the digestion tank, washing the inside and the cap for 3 to 4 times with small amounts of ultrapure water, and collecting the washing liquids to a 50 mL volumetric flask. At last, the liquid was made up to the volume with water and mixed.
ICP-MS was used to detect the concentrations of 84Sr, 86Sr, 87Sr, 88Sr, 10B, 11B, 204Pb, 206Pb, 207Pb, and 208Pb in the samples, with He as collision gas to reduce the interference of isobars, while performing mass calibration with reference materials [12] . The working parameters were provided by the apparatus after automatic tuning optimization, meeting the requirements of sensitivity, background, oxide, double charge and stability etc. in the instrument installation standard. The isotopic abundance ratios were then acquired for conducting dada analysis and building models with the Agilent MPP software.
3. Results and Discussion
3.1. Primary Composite Analysis
There were 13 sets of abundance ratio data between Raohe and nonlocal (non-Raohe) honey: 84/86Sr, 84/87Sr, 84/88Sr, 86/87Sr, 86/88Sr, 87/88Sr, 10/11B, 204/206Pb, 204/207Pb, 204/208Pb, 206/207Pb, 206/208Pb, and 207/208Pb. To conduct primary composite analysis, the large amount of data needed dimension reduction which could transform the former variables into new variables, which were the linear combinations of the former variables, and should represent the characteristics of the former variables as much as possible without information loss, thereby eliminating the overlaps in coexisting information. The selection of main factors might also affect the quality of models built afterwards: short of main factors might cause the exclusion of some useful information, which was called “under-fitting”. The more main factors were selected, the fewer discrete residual factors acceptable for the model would be, however, too many main factors might also cause “over-fitting”. As is proved, it was the optimal case to select 4 main factors.
Table 1 reveals that the cumulative of the four primary composites reached 91.17%, and thus the four primary composites could represent most of the information provided by original variables. The three-dimensional plot of original data from ICP-MS is shown as Figure 1.
To make the data of each sample more intuitive in primary composite analysis, the data were shown in the form of interaction diagrams which could show the distribution areas of the samples in the 2D plots of each primary composite directly. The results of interactive dimension building between each two among the primary composites are displayed as the following plots:
As Figure 2 indicates, the cumulative of Component 1 was 49.52%, and that of Component 2 was 20.97%; the sum of the two factors was greater than 65%, and this conformed to the statistical principle.
As seen in Figure 3, the cumulative of Component 1 was 49.52%, while that of Component 3 was 12.94%, and the sum of the two factors is 62.46%. Though the data points of the honey samples from the two regions distributed more dispersedly than those in Figure 1, they respectively concentrated on two regions of the plot.
As Figure 4 demonstrates, the cumulative of Component 1 was 49.52%, while that of Component 4 was 7.74%, and the sum of the two factors was 57.26%. The data points of Raohe and nonlocal honey samples were scattered and could not be zoned accurately.
![]()
Table 1. The cumulatives of the four primary composites.
![]()
Figure 1. The three-dimensional plot of original data from ICP-MS.
![]()
Figure 2. Interaction diagram between Component 1 and Component 2.
![]()
Figure 3. Interaction diagram between Component 1 and Component 3.
![]()
Figure 4. Interaction diagram between Component 1 and Component 4.
3.2. Building Models
Five models, i.e. the Decision Tree, Naive Bayes, Neural Network, Partial Least Square Discriminate, and Support Vector Machine, were built with the Agilent MPP software by the method of PCA with four primary composites as new variables. The validation of the five models was performed by randomly selecting 11 samples of Raohe honey and 5 of nonlocal honey, and the results of forecasting were shown in Table 2.
As Table 2 shows, the Decision Tree model had a high classification accuracy and a good noise reducing function; the Confident Measurer was 1.0, which meant a high credibility. There was only one misjudgment, nonlocal 1; the total forecasting accuracy reached 93.75%.
As Table 3 indicates, the Naive Bayes model had a lower Confident Measurer than the Decision Tree, for Naïve Bayes was determined by the dependences among the eigenvalues and there might be weaker dependences among the Sr, Pb and B isotopes. As reflected in the result of the model, two samples, HFY4 and RF11, were misjudged; the total forecasting accuracy was 87.5%.
![]()
Table 2. Forecasting results of the decision tree model.
![]()
Table 3. Forecasting results of the Naive Bayes model.
As presented in Table 4, the Neural Network model might fall into local extremum, resulting in lower credibility of some samples. Two samples, RF11 and nonlocal 1, were misjudged in this model; the total forecasting accuracy was 87.5%.
As Table 5 reveals, as the Partial Least Squares Discrimination model was built with primary composites analysis as its main body and was based on multivariate linear regression analysis and canonical correlation
![]()
Table 4. Forecasting results of the neural network model.
![]()
Table 5. Forecasting results of the partial least squares discrimination model.
analysis, the Confident Measurer of the model reached 1.0. As the model merely preliminarily conducted multivariate regression analysis on the primary composites, there were four misjudgments: nonlocal 1, HFY2, HFY20, and HFY21; and the total forecasting accuracy, 75%, was lower than those of the other models.
As Table 6 illustrates, the Confident Measurer of the Support Vector Machine model was lower than those of the other models, since some support vector samples were added to or deleted from the Support Vector Machine model, making it insensitive at the selection of cores. However, this did not affect the forecasting result of the model, because it eliminated a large number of redundant samples, leaving several support vectors to determine the final result, which enabled us to seize the key sample. There was only one misjudged sample, nonlocal 1, in this model, of which the total forecasting accuracy was 93.75%.
In observation of the forecasting results provided by the five models (Tables 2-6 and Figures 5-10), the Decision Tree, Neural Network, Partial Least Square Discriminate and Support Vector Machine misjudged the
![]()
Figure 5. Interaction diagram between Component 1 and Component 2 in the decision tree model of nonlocal sample 1.
![]()
Figure 6. Interaction diagram between Component 1 and Component 2 in the Naive Bayes model of RF1.
![]()
Figure 7. Interaction diagram between Component 1 and Component 2 in the Naive Bayes model of HFY4.
![]()
Figure 8. Interaction diagram between Component 1 and Component 2 in the neural network model of nonlocal 1.
![]()
Figure 10. Interaction diagram between Component 1 and Component 2 in the support vector machine model of the nonlocal 1.
![]()
Table 6. Forecasting results of the support vector machine model.
nonlocal sample 1. According to the labels, the sample was linden honey from Guangxi. However, since Guangxi linden honey was mainly from the northeastern of China, the sample might be Raohe honey. Therefore, the accurate rates of the forecasting of Decision Tree and Support Vector Machine could reach 100%. As the interaction diagram between Component 1 and Component 2 in the Naive Bayes model of HFY4 (Figure 7) reflects, the output points of HFY 4 were farther from the input points than other samples. It can be revealed that the abundances of Sr isotopes in the sample were much lower than those of the other samples of HFY after sourcing the data. The errors might be caused by human factors while processing the samples. The misjudgments in the Partial Least Squares Discrimination model of HFY2, HFY20, and HFY21 indicate that the forecasting results were not always accurate even though the Confident Measurer was 1.0. Since the Confident Measurer value is a parameter which merely estimates the credibility of the model by forecasting according to the data within, it can just be used for reference. Considering that the Partial Least Squares Discrimination model just played multivariate linear analysis on the primary composites and was low in accurate rate (75%), it could be used as the preliminary forecasting model for the geological sourcing of Raohe honey.
Seeing that the Component 3 and Component 4 had lower contribution rates and were not clearly distinguished in interaction diagrams, the interaction diagrams among the Component 1, Component 2, Component 3, and Component 4 were omitted.
4. Conclusion
The geological sourcing of Raohe honey was feasible with the method of ICP-MS in combination with PCA and forecasting models. The decision Tree and Support Vector Machine models could accurately distinguish non-Raohe honey from Raohe honey. For the Naive Bayes model, the accurate rate of forecasting could be raised by independent modeling on the Sr, Pb or B isotope. The accurate rate of the forecasting of Neural Network could be improved by changing the number of primary composites and the ranges of the parameters. And the preliminary forecasting on samples could be accomplished on the foundation of the Partial Least Squares Discrimination model.
Acknowledgements
My deepest gratitude goes first and foremost to Mr. MA Zhanfeng, the project leader, for his patient and careful guidance. And I would also like to express my heartfelt gratitude to Mr. XU Yao for his great efforts.