Profile Generation Methods for Reinforcing Robustness of Keystroke Authentication in Free Text Typing ()
1. Introduction
Keystroke data contain each user’s fixed typing pattern, and a biometrics technology using such data is called keystroke authentication [1] -[3] . Comparing with other biometrics technology, keystroke authentication has two different features. First, keystroke data can be measured using only a keyboard; any special equipment, such as fingerprint and retinal scanners, is not required. Second, this biometric measuring system has possible app- lications other than access authorization, such as continuous observations of users on a computer system even after log-in process.
Most previous research on keystroke dynamics have focused on user authentication at the time of log-in, using not only information about a series of input characters for password recognition, but also keystroke authentication as a part of the authentication process [4] [5] . On the other hand, we considered the use of an analytic method that captures individual characteristics through the input of completely different phrases, rather than using repeated input of a short word for password verification. By using sentences of a certain length, it is possible to obtain sufficient information for deriving keystroke dynamics statistically. Little research has been performed on the keystroke authentication with such long-text input, and this has recently become the subject of academic discussion [6] -[13] . It can be used to detect spoofing after log-in process by observing keystroke data when using a system.
Using the WED + AD identification method which integrates the Weighted Euclidean Distance (WED) method proposed by Samura and Nishimura [10] -[13] and the Array Disorder (AD) method proposed by Gunetti and Picardi [7] [8] , we could attain about 99% recognition accuracy for 127 high typing skill examinees who can type 700 or more letters per 5 minutes [11] . However, there remain some factors decreasing the recognition accuracy. In particular, long period passage after registration and existence of low typing skill users were found as significant factors through several experiments in our previous research [10] -[14] . Passage of time after re- gistering each user’s profile documents decreases the recognition accuracy, and lower typing skill examinees who can type only about 500 - 600 letters per 5 minutes can also deteriorate it.
Most approaches in the previous research on keystroke authentication have focused on how to treat feature extraction and identification methods, but hardly addressed issues on profile generation methods. In this paper, we propose new profile generation methods, profile-updating and profile-combining methods, in order to over- come the above mentioned degradation factors of the recognition accuracy. With the introduction of these methods, the effectiveness is demonstrated through three examinations with experimental data, by considering the findings that recognition accuracy is influenced by the number of registered profile documents, the number of kinds of letters and intervals between registration of profile documents, obtained in our works [14] -[16] . Implementation of the profile generation methods is expected to improve the recognition accuracy and reinforce the robustness of keystroke authentication system.
In Section 2, we briefly introduce the keystroke data and the feature extraction we have dealt with so far. Next, we present three methods for keystroke identification in free text typing in Section 3. In Section 4, new profile generation methods are proposed and examined with subjects’ experimental data. Results and conclusion are given in Sections 5 and 6 respectively.
2. Keystroke Data and Feature Extraction
This section describes keystroke data collection system and how to extract features from keystroke data. In this study, we use a web-based system, and it has typing support software that is familiar to the participants, thereby lowering effects related to unfamiliarity and nervousness. Figure 1 shows a screenshot of the software interface used in this study. The document display screen allows participants who are skilled typists to input text while viewing the Japanese text displayed in the upper row. Less skilled typists can type while viewing the Latin alphabet text displayed in the middle row. Latin alphabet text is removed from the screen as it is typed, allowing confirmation of mistyped characters. The top row displays the number of keystrokes, the number of errors and the amount of time remaining. Since this experiment focuses only on Latin alphabet input keystroke, conversion into Japanese kanji characters is not designed. Participants input a different text each time for 5 minutes. For each entry, typed key, key pressed time and key released time are recorded as raw data. Figure 2 shows an example of collected keystroke data. The first, second and third fields show typed key, whether the key was pressed (p) or released (r) and UNIX time of the event.
Next, we describe feature extraction from keystroke data. The notation 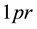 in Figure 3 indicates the time from press to release of a single key and is referred to below as key press duration. The notation
in Figure 3 indicates the time from press to release of a single key and is referred to below as key press duration. The notation 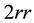 indicates the time from the release of one key to the release of the following key when typing a consonant-vowel pair. The time from release of the first key to the time of pressing the following key (
indicates the time from the release of one key to the release of the following key when typing a consonant-vowel pair. The time from release of the first key to the time of pressing the following key (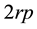 ) and the time from pressing the first key to pressing the second key (
) and the time from pressing the first key to pressing the second key (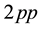 ) are also considered. Furthermore,
) are also considered. Furthermore, 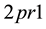 indicates the time from pressing the first key to releasing the next key,
indicates the time from pressing the first key to releasing the next key,  indicates the key press duration when typing the second (vowel) key, and
indicates the key press duration when typing the second (vowel) key, and  indicates the key press duration when typing the first (consonant) key.
indicates the key press duration when typing the first (consonant) key.
The average and standard deviation of each of the seven measures described above are used as the feature
![]()
Figure 1. Snapshot of keystroke data collection system.
![]()
Figure 2. Example of collected keystroke data (typed key, pressed (p) or released (r), and UNIX time in order from the left).
![]()
Figure 3. Keystroke measurements of single letter (left) and letter pair (right).
indices for identification of individuals. For these feature indices, standardization is performed according to the following equation:
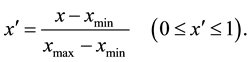 (1)
(1)
Here, 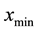 and
and 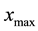 respectively refer to the minimum and maximum values obtained from the feature indices of all subjects. It has been confirmed in our previous works [10] -[13] that the standard deviations for six letter pairs (2**) in feature indices have little contribution to improve recognition accuracy. Therefore, we do not adopt them in this study.
respectively refer to the minimum and maximum values obtained from the feature indices of all subjects. It has been confirmed in our previous works [10] -[13] that the standard deviations for six letter pairs (2**) in feature indices have little contribution to improve recognition accuracy. Therefore, we do not adopt them in this study.
3. Identification Methods
This section describes identification methods: the Weighted Euclidean Distance (WED) method proposed by Samura and Nishimura [10] -[13] , the Array Disorder (AD) method proposed by Gunetti and Picardi [7] [8] and WED + AD method proposed by Samura and Nishimura [13] .
3.1. Weighted Euclidean Distance (WED) Method
Taking the first profiling document of Typist A as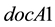 , the profile document of each participant can be represented as
, the profile document of each participant can be represented as 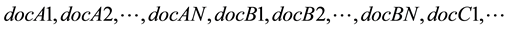 An unknown document is repre- sented as
An unknown document is repre- sented as . The square root of WED used as the identification function is given by the following equation:
. The square root of WED used as the identification function is given by the following equation:
![]() (2)
(2)
The index of the feature indices ![]() is then
is then![]() ,
, ![]() ,
,![]() . Furthermore, m is the number of contributing feature indices,
. Furthermore, m is the number of contributing feature indices, ![]() indicates the feature index
indicates the feature index ![]() for the i-th character (single letter or letter pair), and
for the i-th character (single letter or letter pair), and ![]() is the number of characters therein.
is the number of characters therein. ![]() will vary greatly with respect to the number of kinds of letters compared when, for example, taking the keystroke feature indices for single letters and those for two- letter combinations.
will vary greatly with respect to the number of kinds of letters compared when, for example, taking the keystroke feature indices for single letters and those for two- letter combinations. ![]() is the
is the ![]() feature index standardized according to Equation (1) for a profile do- cument (e.g.,
feature index standardized according to Equation (1) for a profile do- cument (e.g.,![]() ), and
), and ![]() is that for
is that for ![]() of an unknown document
of an unknown document![]() . The WED is norma-
. The WED is norma-
lized to the range 0 - 1 using the weightings ![]() and
and![]() .
.
Identification is performed using the nearest-neighbor rule. In other words, comparisons are performed be- tween the unknown document and each of the profile documents, and the typist of the profile document that gives the lowest value is taken to be the typist of the unknown document. For example, given five profile documents (A1-A5) for a given subjects (Typist A), we can expect that if Typist A also typed the unknown do- cument then its value will be close to one of the five states of Typist A A1-A5. In the case where the typist of the candidate profile document is matched with the typist of the test document, the identification is classified as a success; otherwise, the identification is classified as a failure. Such validation is performed in turn on each do- cument used in this study, and the recognition accuracy is calculated by (number of successful identifications)/ (number of test documents) × 100%.
3.2. Array Disorder (AD) Method
The AD method, which is called the R-measure in refs. [7] [8] , but referred to as the Array Disorder in the present study, ranks characters according to their feature index values, and evaluates the disorder of the rankings. Standardized feature indices are sorted in increasing order, the difference in rankings of each is taken, and the totals of each are taken as the distance.
![]() (3)
(3)
![]() (4)
(4)
When ![]() characters are used to compare a feature index
characters are used to compare a feature index![]() , if
, if ![]() is even then the distance is divided by
is even then the distance is divided by![]() ; if
; if ![]() is odd then the distance is divided by
is odd then the distance is divided by![]() . Finally, the value is normalized to the range 0 - 1 by dividing the value by the number of contributing feature indices m.
. Finally, the value is normalized to the range 0 - 1 by dividing the value by the number of contributing feature indices m.
3.3. WED + AD Method
In contrast to the WED method, which evaluates the magnitude of differences in feature index values between documents, the AD method focuses on differences between documents in ranking patterns of the feature indices. The WED + AD method complementarity incorporates the features of the WED and AD methods. The distance of the WED + AD method is given by the following equation:
![]() (5)
(5)
In this method, neither WED nor AD dominates because they are normalized to the range 0 - 1. Detailed explanations for the above methods are given in ref. [13] .
4. Profile Generation Methods and Examinations
4.1. Examination Using Profile-Updating Method
Since long period passage after registering profile documents decreases recognition accuracy [14] , it is desired to prevent it from decreasing by removing an old profile document and adding a new profile document in order to operate a system sustainably. The profile-updating method removes the oldest profile document of all and registers a test document as a new profile document for the target user when the identification is succeeded. We show the effectiveness of this method through the following examination.
We choose 15 documents for each subject. Each document was collected almost every other week and sorted in time-series order. There are two cases of investigation: no-updating and updating profile documents. In the first case, five documents in order from the oldest are fixed as profile ones, and other 10 documents are used as test ones (no-update case). Figure 4(left) shows an example that there are 15 documents (profile documents: doc1-doc5, test documents: doc6-doc15). Identification is performed with sliding test document, ![]() ,
, ![]() ,
, ![]() , in order from the oldest. Other subjects’ test documents are also used in the same way.
, in order from the oldest. Other subjects’ test documents are also used in the same way.
In the second case, we use the profile-updating method (update case). If the typist of the test document is the same with the typist of the nearest profile document with the test document, the test document is added as a new profile document to typist’s profile documents, and the oldest one of them is removed. The test document is, however, not added and profile documents are not updated if the identification is failed. Figure 4(right) shows an example of using the profile-updating method. At first, doc1-doc5 are profile documents, and ![]() is the first test document and compared with profile documents. If identification of
is the first test document and compared with profile documents. If identification of ![]() is succeeded,
is succeeded, ![]() is registered as a new profile document and
is registered as a new profile document and ![]() is removed from profile documents. Second,
is removed from profile documents. Second, ![]() is com-
is com-
![]()
Figure 4. Identification processes in no-update (left) and update (right) cases.
pared with new profile documents. In this case, not only test documents but also profile documents are slidden if the identification is succeeded. Other subjects’ documents are also used in the same way. In this examination, we take 100 subjects who have 15 or more documents, each of which contains 500 or more input letters. We evaluate recognition accuracy in both no-update and update cases.
4.2. Examination Using Profile-Combining Method
As for keystroke authentication in free text typing, high recognition accuracy is given if each document contain sufficient amounts of kinds of letters. In practice, it is desired to verify the user in a short time although it needs a long time to type such amount of letters. Therefore, we combine original profile documents (original docs) and generate new combined profile documents (combined docs). Figure 5 shows an example of combining two profile documents for 5 original docs and generating 10 combined docs. Combining profile documents increases the number of input letters in each combined one. The more input letters, the more number of kinds of letters increases, and the sufficient number of kinds of letters improves the recognition accuracy [15] .
In this examination, we prepare 5 or 10 profile documents (original docs) at random for each subject, and new profile documents (combined docs) are generated by combining two documents of them. Figure 5 and Figure 6 show the generation of new profile documents from 5 and 10 profile documents respectively. 10 (=![]() ) com- bined docs are made by 5 original docs for each subject as in Figure 5, and 45 (=
) com- bined docs are made by 5 original docs for each subject as in Figure 5, and 45 (=![]() ) combined docs are made by 10 original docs as in Figure 6. Recognition accuracy is calculated by using the leave-one-out cross vali- dation method. We choose a document as a test document from all documents, and calculate distances between the test document and the combined ones with each identification method. This is performed for all of docu- ments. We do not compare a test document with a combined profile document if the combined profile document contains the test document. We take 250 subjects who have 10 or more documents, each of which contains 500 or more input letters. Among them, 68 subjects are the lower typing skill users who can type only less than 600 letters.
) combined docs are made by 10 original docs as in Figure 6. Recognition accuracy is calculated by using the leave-one-out cross vali- dation method. We choose a document as a test document from all documents, and calculate distances between the test document and the combined ones with each identification method. This is performed for all of docu- ments. We do not compare a test document with a combined profile document if the combined profile document contains the test document. We take 250 subjects who have 10 or more documents, each of which contains 500 or more input letters. Among them, 68 subjects are the lower typing skill users who can type only less than 600 letters.
5. Results
As the WED + AD method gives the highest recognition accuracy among three identification methods [11] [13] , we show only results with the WED + AD method in the following. Figure 7 shows the recognition accuracy in both no-update and update cases explained in Subsection 4.1. Updating profile documents prevents the recognition accuracy from decreasing. Long period passage after registering profile documents decreases the recognition accuracy [14] , and this is caused by the change of subjects’ typing patterns change over time. In fact, Figure 8 shows the increment of the average number of input letters for 100 subjects in each-week documents, and it indicates that their typing patterns changed as time passed. Updating profile documents keeps the period after registration short and enables the system to adapt the changes of typing patterns in their test documents
Figure 9 shows the recognition accuracy for combined profile documents constructed by the method in Subsection 4.2. The recognition accuracy in 10-document case is about 4% - 5% higher than that in 5-document case. This is owing to statistical precision enhancement by the rise in the number of documents. In addition,
![]()
Figure 5. Generation of new combined profile documents from 5 original profile documents.
![]()
Figure 6. Generation of new combined profile documents from 10 original profile documents.
![]()
Figure 7. Recognition accuracy in no-update and update cases.
![]()
Figure 8. Increment of average number of input letters for 100 subjects in each-week document.
![]()
Figure 9. Comparison of recognition accuracy between original profile documents and combined ones (left: 5-document case, right: 10-document case).
comparing with the results of original documents, combining profile documents is found to improve the recognition accuracy even for the case of including lower typing skill subjects who can type only about 500 - 600 letters per 5 minutes (68 subjects). And then, both in the 5-document and 10-document cases, their values of recognition accuracy increase a few percent comparably by combining profile documents.
Figure 10 shows the comparison of the number of kinds of letters, ![]() , in Equations (2), (3) and (4) per one profile document corresponding to each in Figure 9. There is little difference in the number of kinds of single letters between the original and combined profile documents because it is rich even in the original profile documents, but the number of kinds of letter pairs increases by combining profile documents. This means a dimensional extension in the contributing feature indices which leads to a better recognition accuracy.
, in Equations (2), (3) and (4) per one profile document corresponding to each in Figure 9. There is little difference in the number of kinds of single letters between the original and combined profile documents because it is rich even in the original profile documents, but the number of kinds of letter pairs increases by combining profile documents. This means a dimensional extension in the contributing feature indices which leads to a better recognition accuracy.
In the case in Figure 9, two profile documents are used to generate one combined profile document, but it is possible to use more than two ones as constituent documents for that. Figure 11 shows the recognition accuracy obtained in each case using different number of constituent profile documents for a combined profile document in 250 subjects with 5 original profile documents. When the number of constituent profile documents is two, it provides the highest recognition accuracy.
![]()
Figure 10. Change of the number of kinds of letters per one profile do- cument.
![]()
Figure 11. Dependence of recognition accuracy on the number of con- stituent profile documents for combining.
Figure 12 shows the change of the number of kinds of letters ![]() corresponding to each in Figure 11. The number of kinds of single letters attains its maximum even at the stage of one original profile documents, and the number of kinds of letter pairs increases and reaches near the plateau at the stage of four constituent profile documents. On the other hand, the number of newly produced combined profile documents from 5 original pro- file documents becomes 6 (=
corresponding to each in Figure 11. The number of kinds of single letters attains its maximum even at the stage of one original profile documents, and the number of kinds of letter pairs increases and reaches near the plateau at the stage of four constituent profile documents. On the other hand, the number of newly produced combined profile documents from 5 original pro- file documents becomes 6 (=![]() ) for two constituents, 4 (=
) for two constituents, 4 (=![]() ) for three constituents, and 1 (=
) for three constituents, and 1 (=![]() ) for four constituents. Note that when we use the leave-one-out cross validation for a test document to be checked, combined profile documents which contain the exact test document should be removed from the group of them. Based on the above results, both the numbers of kinds of letters and valid combined profile documents increase only in the case of combining two constituent profile documents and this enhances the recognition accuracy as shown in Figure 11. In other cases, the recognition accuracy has a deteriorative tendency due to the trade-off relationship between the two factors.
) for four constituents. Note that when we use the leave-one-out cross validation for a test document to be checked, combined profile documents which contain the exact test document should be removed from the group of them. Based on the above results, both the numbers of kinds of letters and valid combined profile documents increase only in the case of combining two constituent profile documents and this enhances the recognition accuracy as shown in Figure 11. In other cases, the recognition accuracy has a deteriorative tendency due to the trade-off relationship between the two factors.
Through the examinations in this paper, it has been demonstrated that the profile-updating method prevents the recognition accuracy from decreasing, and the profile-combining method improves it. By adopting both methods together as shown in Figure 13, we can expect the system to sustain higher performance. Figure 14 shows the recognition accuracy for the same 100 subjects in examination in Subsection 4.1. By applying the profile updating and combining methods simultaneously (update + combine), the recognition accuracy is found to keep the higher value around 98% in comparison with the result using only the profile-updating method.
![]()
Figure 12. Dependence of the number of kinds of letters on the number of constituent profile documents for combining.
![]()
Figure 13. Identification process adopting both profile up- dating and combining methods for 5 original profile docu- ments (update + combine case).
![]()
Figure 14. Recognition accuracy in update + combine case compared with the result in no-update and update cases in Figure 7.
6. Conclusions
In this paper, we have proposed two new profile generation methods to reinforce the robustness of keystroke authentication system for free text typing and shown the effectiveness of them through the examinations with subjects’ practical data. The profile-updating method kept the period after registration short and enabled the system to adapt the changes of users’ typing patterns, and thus prevented the recognition accuracy from de- creasing. In addition, the profile-combining method increased both the numbers of kinds of letters and combined profile documents and owing to their synergistic effect, improved the recognition accuracy even in the case of including lower typing skill subjects. Furthermore, adopting both methods together sustained the high recognition accuracy and reinforced the robustness of keystroke authentication in free text typing.
In general, these profile generation methods are independent of feature extraction scheme in Section 2 and identification methods in Section 3 and thus can be widely applied to other keystroke authentication approaches. Although we have investigated on Japanese text input in this study, the feature indices and authentication model used here can be applied to other language text input.
Acknowledgments
This work was supported by the Grant in Aid for Scientific Research (C24500101) from JSPS.