1. Introduction
Everywhere around us are signals that can be analyzed. Signals are time-varying quantities which carry a lot of information. They may be audio signals, images or video signals, sonar signals or ultrasound, biological signals such as the electrical pulses from the heart, communications signals, or many other types. Audio signals carry an enormous amount about you.
In the last several years, several numbers of security systems based on fingerprints, voice, iris, face images, the pattern of the hands, and the pattern of motion of the arms have been presented. The security system based on iris or fingerprint is not convenient in practice since it imposes stringent requirements on interaction with the user; the users of modern fingerprint become anxious about the hygiene of the process, and the users of modern iris face stringent requirements on movements and visibility of the eyes [1] . So there is a strong motivation to work in security system based on voice.
The security systems based on voice have been increased rapidly because of its non-contact characteristic [2] , and no two individuals sound identical since their vocal tract shapes, larynx sizes, and other parts of their voice production organs are different [3] . So the Voice Recognition System (VRS) became one of the most useful and popular biometric recognition systems in the world especially in the areas in which security was a major concern. It can be used for authentication, surveillance, forensic speaker recognition and a number of related activities.
Voice Recognition (VR) which also called Speaker Recognition (SR) is the process of automatically recognizing who is speaking depending on the basis of individual information included in his/her voice signal. SR can be classified into Speaker Identification (SI) and Speaker Verification (SV). Speaker Identification is the process of determining which registered speaker provides a given utterance (one-to-many matching), on the other hand, SV is the process of accepting or rejecting the identity claim of a speaker (one-to-one matching), and this decision depends on the degree of similarity between the claimed speaker and the enrolled speaker.
In VRS, two basic operations are carried out: feature extraction and classification. In feature extraction, we capture the vital characteristic which enables us to distinguish a speaker from the other. Some of techniques were used for extracting features were Fourier Transforms (FTs), and Short-Time Fourier Transforms (STFTs). But these techniques aren’t suitable for representing non stationary signals such as voice signals. By using (FTs), the input signal was transformed from the time domain into the frequency domain so we could know the frequencies that contained in the signal but not when, and STFTs tried to handle the problem by using a local window to display the frequency and time relation but its accuracy depended on the used window. Wavelet Transforms (WTs) have handled some of these problems. Classification is executed at two steps: enrollment and matching which often referred to them as training and testing respectively. In enrollment step, the speaker is introduced to the system by using the extracted features from the training data, and the testing step is activated when a vector of data from unknown speaker is entered to the system. It matches the vector data to a model corresponding to a known speaker. Classifications techniques have been used in VRS include Hidden Markov Models (HMMs) and Artificial Neural Networks (ANNs).
Several studies based on WTs as well as ANNs have been presented to design a SI system [2] [4] . A text-in- dependent speaker identification system based on the Zak transform [5] has been presented where the speech database was drawn from the ELSDSR database [6] . In this study, we have tried to enhance the efficiency of the SI System which has already existed [5] . This enhancement can be summarized as: Wavelet Packet Transform (WPT) has been applied at the stage of feature extraction but these data were not suitable for classification as the performance of ANNs is depended on the size of the training data. The critical choice of subset of features from a larger set is very important to improve the performance of speaker recognition [7] . In our study, the energy corresponding to WP nodes have been captured as features vectors. These features vectors have been fed to Feed Forward Back-propagation Neural Network (FFBPNN) to train it. Finally, we have tested the trained FFBPNN with a single test file for each speaker.
The rest of the paper is organized as follows: Section 2 gives in brief an overview on the structure of a general VRS. Section 3 introduces the proposed VRS. In Section 4 the results and discussions were presented. Finally, Section 5 presented a conclusion and the future work.
2. Generic Voice Recognition System
Each VRS includes two phases: training and testing phases as graphed in Figure 1. In the training phase the speaker’s voice print is set up from the features vector. These voice prints are stored in a reference database. While in the testing phase, features are extracted from unknown speaker’s voice, then a pattern matching algorithm computes the similarity score between the unknown speaker’s features vector and that stored in the refer-
![]()
Figure 1. Typical voice recognition system.
ence database. Both the training and the testing phases include feature extraction so it is often called the front- end of the system.
2.1. Feature Extraction
Here we extract amount of features from the voice signal. The extracted features should be capable of separating the speakers from each other in its space. In traditional techniques speech features are extracted by FTs and (STFTs) [2] . But these techniques are not suitable for representing voice because they accept stationary signals within a given time frame therefore lack the ability of these techniques to analyze the non-stationary signals or signals in transient state [8] . One of the features obtained via FTs and used in the recognition task was the Mel Frequency Cepstral Coefficient (MFCC). But the recent researches showed that the identification rate with MFCCs can be as high as 99.5% for the noise free TIMIT database [9] . However, the identification accuracy reduced to 60% for the same data set that was transmitted over telephone channels. In 1984, The wavelet theory was proposed, Goupillaud et al. introduced a new transformation for the frequency analysis of the discretized signals. The transform is known as Wavelet Transform (WT) [10] [11] . It gives us the ability for decomposing any signal (analog or digital) of any field (medical, biometric, etc.) into different resolution levels and displays two important variables (frequency & time)synchronously. Wavelets can be applied to many types of problems such as signal de-noising, compression and feature extraction.
The analysis by the Wavelet Transforms is performed by using a single wave is called a mother wavelet (often called window) Ψ(t) which can be considered as a band pass filter, has a limited duration of zero average, has irregular form, and often non-symmetrical unlike sinusoidal waves which extends from minus to plus infinity, and has a symmetrical form. The wavelet transform is defined as the inner product of a signal x(t) with the mother wavelet Ψ(t).
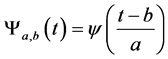
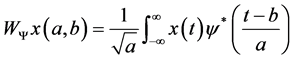
where a, b are the scale and translation parameters.
Depending on the scale factor a, the Wavelet Transforms have a large freedom degree to vary window size. This varying window size is wide for slow frequencies because the low frequency component completes a cycle in a large time interval, and it is narrow for the other high frequencies as the high frequency component completes a cycle in a much shorter interval [12] . Thus, an optimal time-frequency resolution is obtained in all frequency ranges.
2.2. Classification
After the features are extracted and saved for each speaker, these values are considered the threshold to enter the second operation of recognition, classification, which means identification of the identity of unknown speaker by comparing the extracted features from his/her voice with the saved features (Reference Voiceprint Database), the reference which produces a maximum score of similarity is selected to yield a prediction for the speaker’s identity. There are many classification tools such as Hidden Makrov Models (HMMs), Gaussian mixture model (GMM), and ANNs which has an increasing interests in classification and used in this study. The advantages of ANNs for solving speech/speaker recognition problems are their error tolerance and non-linear property [13] .
The ANNs is a mathematical model composed of a large number of simple processing units called neurons. The strategy of its work is inspired from the biological nervous system. Neurons are very lower than silicon logic gates, so the brain overcomes the relatively slow rate of operation by having a staggering number of neurons with massive interconnection between them. Neurons are connected to each other via synapses, and the strength of it is determined by the weight value it possess, each neuron as graphed in Figure 2 has an adder for summing the weighted input signal, and the output of the neuron is limited by the neuron’s activation function which the total input of it is controlled by an externally applied bias.
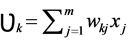
where 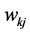 is the synaptic weight directed from neuron j to neuron k, j is the number of inputs.
is the synaptic weight directed from neuron j to neuron k, j is the number of inputs.
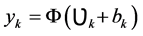
where Ф is the chosen activation function of the neuron, bk is the bias.
These neurons are arranged in layers one after the other, and the network architecture lies in one of three different classes; single-layer networks where we have an input layer of source nodes that projects onto an output layer of neurons, multilayer networks where there is one or more hidden layer, and the third class is the recurrent networks where there is at least one feedback loop.
Applications of ANNs included; pattern association, pattern recognition, function approximation, fitting, and beam forming. Our study belongs to pattern recognition task.
3. The Proposed Voice Recognition System
The proposed system has been presented here is characterized by existing an operation before the feature extraction operation which included in any general VRS. This operation is called pre-processing, the purpose of it is to prevent the error estimation caused by speakers’ volume changes, as see in Figure 3.
3.1. Database Used in This Study
The performance of the VRS which based on a standard speech database is comparable. There are 36 databases among free license such as the database which used here and proprietary bases that have been used in speaker recognition studies. The speech signals have been used in this study are drawn from the standard ELSDSR database. It is non-native speakers’ database. It has been designed to provide speech data for the development and
![]()
Figure 3. The proposed voice recognition system.
evaluation of automatic VRS. It has been designed by the Ph. D students and Master students from department of Informatics and Mathematical Modeling (IMM) at Technical University of Denmark. The speech language is English, and spoken by 21 Dane, one Islander and one Canadian. It contains voice messages from 23 speakers (13M/10F), and the age covered from 24 to 63. No a priori control of the speaker distribution by nationality and age has been done, except for the gender. Since the speakers were selected only in IMM, the speaker group exhibits relatively small variation in profession and educational background. The subjects of this database were from different countries and different places of one country, the dialect of reading English language in this database can probably be used as accent recognition. Part of the text, which is suggested as training subdivision, was made with the attempt to capture all the possible pronunciation of English language, which includes the vowels, consonants and diphthongs. With the suggested training and test subdivision, seven paragraphs of text are constructed and collected for training, which includes 11 sentences; and 46 sentences were collected for test text. In other word, for the training set, 161 (7 *23) utterances were recorded; and for test set, 46 (2 *23) utterances were provided. On average, the duration for reading the training data is: 78.6 s for male; 88.3 s for female; and 83 s for all. The duration for reading test data, on average, is: 16.1 s (male); 19.6 s (female); and 17.6 s (for all) [6] .
3.2. Pre-Processing of the Speech Signals
Signal pre-process have been carried out by performing normalization on the entered speech signals before feature extraction operation is carried to prevent the error estimation caused by speakers’ volume changes. In other words, normalization makes the signals comparable regardless of differences in magnitude [2] . In this study, the signals are normalized by using the following equation [14] :
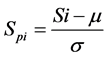
where 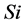 is the ith element of the signal S, µ and
is the ith element of the signal S, µ and 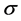 are the mean and standard deviation of the vector S, respectively; SPi is the ith element of the signal series SP after normalization.
are the mean and standard deviation of the vector S, respectively; SPi is the ith element of the signal series SP after normalization.
3.3. Feature Extraction by Wavelet Transforms
In FTs, the signal has been converted from the Time-domain into the Frequency-domain. In feature extraction we need to analysis the signal several times by using variable filters to extract a vital feature. As there are several languages, it is hard to choose a feature which carries a lot of information about each speaker but we investigated to extract a vital feature. This can be done by using STFT which contribute to calculate the MFCCs which is the familiar parameter in the speech recognition task. But MFCCs failed in the in the background noise as mentioned before. The wavelet transforms proved that it is an effective signal processing technique for a variety of signal processing problems. Here we decomposing the signal by using a suitable wavelet transform version and then calculate the energy enclosed in each signal as a distinguished feature for each speaker.
3.3.1. The Discrete Wavelet Transform
In Discrete Wavelet Transform (DWT), the signal is decomposed into Detail “D” and Approximation “A” coefficients in a dyadic form. This can be considered Multi-Resolution Analysis (MRA). In DWT, the scale and translation parameters are given by
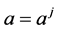
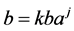
where k and j are integers. The function family becomes
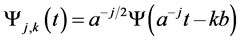
We can imagine that signals transformed by DWT as putting data into a series of high-pass and low-pass filters g(n), h(n) respectively. The high frequency content of speech signals which passed through the g(n) filter is called “details”, and the low frequency content which passed through the h(n) filter is called “approximations”, and only the approximation coefficients can be decomposed further as the decomposition level grows. The wavelet decomposition of the signal S analyzed at level j has the following structure [cAj, cD1, cDj]. DWT has been used at VRS but with limited success because of its left recursive nature [2] [7] .
3.3.2. The Wavelet Packet Transform
In DWT, the high frequency components are removed, the voice will sound different but the speech can still be understood [2] . Wavelet packet analysis is an extension of the DWT [15] . Unlike the DWT, Wave PT decomposes both the high and low frequency bands at each iteration. A pair of low pass and high pass filters is used to generate two sub-bands with different frequencies and this considered one level of decomposition. These sub-bands are then down-sampled dyadically. This process can be repeated to partition the frequency spectrum into smaller frequency bands for resolving different features while localizing the temporal information. The complete binary tree for 3-level decomposition is produced and shown in the Figure 4.
In this study we have used WPT at level 7 with Daubechies 20-tap (db20), so we have divided the original signal into 128 sub-band signal. The Daubechies wavelet is a family of orthogonal wavelets, has a maximum number of vanishing moments, and conserves the energy of the signal and redistributed in a more compact form. The db20 is a member of the Daubechies family and is an estimation of the continuous form. It is asymmetric as shown in Figure 5.
As mentioned above due to conservation of energy the energy corresponding to each WP node is calculated according to the following equation
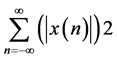
to form the feature vector of size(1 *128) which then used as input to the used Artificial Neural Network (ANN).
![]()
Figure 4. 3-level wavelet packet decomposition tree.
3.4. Classification by Artificial Neural Networks
In the design of the Speaker Recognition System (SRS), a classification technique of the features which extracted by DWT and WPT was used to evaluate the effectiveness of the extracted features in differentiating between the speakers. In this study, the classifier has been used was ANNs. ANNs are adaptive model that can changes its structure depended on information passes through it during the training process. Here the FFBPNN is used which belongs to the multilayer networks. After several experiments with various network structures the highest accuracy was found with 128 neurons for the two hidden layers, and 23 neurons in the output layer. The number of training epochs was selected to be 1000. The learning rate was left to be variable. The error Back- Propagation learning algorithm was used. The FFBPNN is proposed in Figure 6.
The recognition rate is evaluated by plotting the confusion matrix. It contains information about actual and predicted classifications done by a classification system.it consists of columns and rows where each column represents the predicted classes while each row represents the actual classes as proposed in Figure 7.
4. Results and Discussion
A computer with specifications of processor Intel® Core™ 2 Duo CPU 2 GHZ, RAM 2 GB, an operating system windows 7 32-bit, and MATLAB (R2009b) program were used for achieving the experiment. A standard database ELSDSR is used where each registered speaker speaks a certain seven sentences and each sentence has been said for one time. Thus for each speaker we had seven speech samples, and 161 (23 *7) speech samples for the whole speakers. The experiment is carried out on three stages ranged from stage 0 to stage 2 and can be summarized as follows.
Stage 0, we had made normalization on each speech sample to prevent the error estimation caused by speakers’ volume changes as see in Figure 8.
As noticed from Figure 8 the signal values are redistributed in a wide range vertically at this instance the speech samples are ready to analysis them to extract the features vectors and enter the next stage.
Stage 1, we have extracted the features vectors for each sentence for each speaker. In the features extraction step we have applied DWT and WPT but we have got a high performance rate when the speech samples were analyzed with WPT as it has characterized by the recursive analysis. We have used the Daubechies as mother wavelet and performed decomposition up to level 7 and the original speech sample is divided into 128 sub-band. We investigated on the better features that can represent each speaker, so calculation of the energy corresponding to each sub-band was the best choice as by it we can distinguish between the speakers’ identities as proposed in Figure 9.
As noticed from the preceding figure the energy feature can differentiate between the speakers. We have formed a (128 *161) features matrix for the whole database’s speakers. The features matrix was the threshold to enter the final stage in our experiment.
Stage 2, Classification is performed on two stages, in the training stage the features matrix and a suitable target matrix have been entered as inputsto the FFBPNN which specified in Table 1 and is drawn in Figure 6.
The FFBPNN varies its weight depended on the input and the expected output which feed to it. The expected output which also called the target matrix has a size of (23 *161). It is organized as for each speaker there is 7
![]()
Figure 8. The speech signal for the first speaker before and after normalization.
![]()
Figure 9. Energy distribution of sentence 1 for the two different speakers.
![]()
Table 1. Description of the FFBPNN.
columns (equals to the seven training sentences) with the first row has 1 values and the rest rows have 0 values, for the second speaker we bank the second seven columns with the second row in them has 1 values and the other rows have 0 values and so on until the twenty-three speaker for him the twenty-three row is filled with 1 values. Our target matrix can be summarized as in the Table 2.
Table 3 shows a summary of the confusion matrix which represents the accuracy of the FFBPNN for speakers individually as well as the system overall. Depending on the training database set, the system attempts to recognize 7 samples for each speaker where the total number of samples is 161. The overall system accuracy was 100%.
After getting on that accuracy in the training stage we saved the weights and biases of all layers of the trained FFBPNN. The weight values from the second hidden layer to the output layer can be abbreviated in Table 4.
At the testing stage, we have created another feature matrix (128 *23) where each speaker said another sentence differs from the seven sentences which used in the training stage and also differs from one speaker to another one, we have created the same FFBPNN with the saved weights and biases, and performed the test to get a recognition rate equal to 95.7% which recorded from the confusion matrix. Table 5 shows a summary of the confusion matrix in that stage. The system failed to recognize the six-teen speaker to become the overall recognized speakers equal to 22, and the overall accuracy of the system is 95.7%. Table 6 shows a comparison between MFCC, the Zak transform and the WPT techniques when all seven training files are used in the training phase. The WPT technique shows the same recognition rate 100% as the other two techniques if two test files are used and a recognition rate 95.7% if the first test file is used which better than the obtained by using the Zak transform 91.3% [5] .
![]()
Table 3. Recognition rate results at the Training stage.
![]()
Table 4. Some of the weights values from the second hidden layer to the output layer.
![]()
Table 5. Recognition rate results at the testing stage.
![]()
Table 6. Comparison with MFCC, Zak in terms recognition rate.
5. Conclusion and Future Work
In this paper, an intelligent VRS using WPT and FFBPNN is presented. A new method for feature extraction based on energy distribution of WP tree nodes and classification based on the FFBPNN is presented. The obtained results show that the proposed method can make an effective analysis. The average identification rate was 95.7% better than another study 91.3% [5] on the same database where the recognition rate was 91.3% by using a single test file published before. In the future work, we will try to reduce the number of features associated with each speaker, and try to improve the efficiency of the proposed system in the real-time where the noise exist such as the street by using a hardware circuit such as the FPGA circuit.