Received 12 March 2016; accepted 21 May 2016; published 24 May 2016

1. Introduction
Many problems in the industry involved optimization of certain complicated function of several variables. Furthermore there are usually set of constrains to be satisfied. The complexity of the function and the given constrains make it almost impossible to use deterministic methods to solve the given optimization problem. Most often we have to approximate the solutions. The approximating methods are usually very diverse and particular for each case. Recent advances in theory of neural network are providing us with completely new approach. This approach is more comprehensive and can be applied to wide range of problems at the same time. In the preliminary section we are going to introduce the neural network methods that are based on the works of D. Hopfield, Cohen and Grossberg. One can see these results at (section-4) [1] and (section-14) [2] . We are going to use the generalized version of the above methods to find the optimum points for some given problems. The results in this article are based on our common work with Greg Millbank of praxis group. Many of our products used neural network of some sort. Our experiences show that by choosing appropriate initial data and weights we are able to approximate the stability points very fast and efficiently. In section-2 and section-3, we introduce the extension of Cohen and Grossberg theorem to larger class of dynamic systems. For the good reference to linear programming, see [3] , written by S. Gass. The appearance of new generation of super computers will give neural network much more vital role in the industry, machine intelligent and robotics.
2. On the Structure and Applicationt of Neural Networks
Neural networks are based on associative memory. We give a content to neural network and we get an address or identification back. Most of the classic neural networks have input nodes and output nodes. In other words every neural networks is associated with two integers m and n. Where the inputs are vectors in 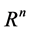 and outputs are vectors in
and outputs are vectors in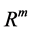 . neural networks can also consist of deterministic process like linear programming. They can consist of complicated combination of other neural networks. There are two kind of neural networks. Neural networks with learning abilities and neural networks without learning abilities. The simplest neural networks with learning abilities are perceptrons. A given perceptron with input vectors in
. neural networks can also consist of deterministic process like linear programming. They can consist of complicated combination of other neural networks. There are two kind of neural networks. Neural networks with learning abilities and neural networks without learning abilities. The simplest neural networks with learning abilities are perceptrons. A given perceptron with input vectors in 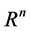 and output vectors in
and output vectors in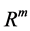 , is associated with treshhold vector
, is associated with treshhold vector 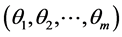 and
and 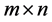 matrix
matrix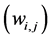 . The matrix W is called matrix of synaptical values. It plays an important role as we will see. The relation between output vector
. The matrix W is called matrix of synaptical values. It plays an important role as we will see. The relation between output vector
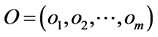 and input vector vector
and input vector vector 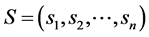 is given by
is given by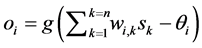 , with g a
, with g a
logistic function usually given as 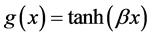 with
with 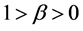 This neural network is trained using enough number of corresponding patterns until synaptical values stabilized. Then the perceptron is able to identify the unknown patterns in term of the patterns that have been used to train the neural network. For more details about this subject see for example (Section-5) [1] . The neural network called back propagation is an extended version of simple perceptron. It has similar structure as simple perceptron. But it has one or more layers of neurons called hidden layers. It has very powerful ability to recognize unknown patterns and has more learning capacities. The only problem with this neural network is that the synaptical values do not always converge. There are more advanced versions of back propagation neural network called recurrent neural network and temporal neural network. They have more diverse architect and can perform time series, games, forecasting and travelling salesman problem. For more information on this topic see (section-6) [1] . Neural networks without learning mechanism are often used for optimizations. The results of D.Hopfield, Cohen and Grossberg, see (section-14) [2] and (section-4) [1] , on special category of dynamical systems provide us with neural networks that can solve optimization problems. The input and out put to this neural networks are vectors in
This neural network is trained using enough number of corresponding patterns until synaptical values stabilized. Then the perceptron is able to identify the unknown patterns in term of the patterns that have been used to train the neural network. For more details about this subject see for example (Section-5) [1] . The neural network called back propagation is an extended version of simple perceptron. It has similar structure as simple perceptron. But it has one or more layers of neurons called hidden layers. It has very powerful ability to recognize unknown patterns and has more learning capacities. The only problem with this neural network is that the synaptical values do not always converge. There are more advanced versions of back propagation neural network called recurrent neural network and temporal neural network. They have more diverse architect and can perform time series, games, forecasting and travelling salesman problem. For more information on this topic see (section-6) [1] . Neural networks without learning mechanism are often used for optimizations. The results of D.Hopfield, Cohen and Grossberg, see (section-14) [2] and (section-4) [1] , on special category of dynamical systems provide us with neural networks that can solve optimization problems. The input and out put to this neural networks are vectors in 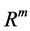 for some integer m. The input vector will be chosen randomly. The action of neural network on some vector
for some integer m. The input vector will be chosen randomly. The action of neural network on some vector 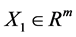 consist of inductive applications of some function
consist of inductive applications of some function 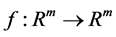 which provide us with infinite sequence
which provide us with infinite sequence![]() . where
. where![]() . And output (if exist) will be the limit of of the above sequence of vectors. These neural networks are resulted from digitizing the corresponding differential equation and as it is has been proven that the limiting point of the above sequence of vector coincide with the limiting point of the trajectory passing by
. And output (if exist) will be the limit of of the above sequence of vectors. These neural networks are resulted from digitizing the corresponding differential equation and as it is has been proven that the limiting point of the above sequence of vector coincide with the limiting point of the trajectory passing by![]() . Recent advances in theory of neural networks provide us with robots and comprehensive approach that can be applied to wide range of problems. At this end we can indicate some of the main differences between neural network and conventional algorithm. The back propagation neural networks, given the input will provide us the out put in no time. But the conventional algorithm has to do the same job over and over again. On the other hand in reality the algorithms driving the neural networks are quite massy and are never bug free. This means that the system can crash once given a new data. Hence the con- ventional methods will usually produce more precise outputs because they repeat the same process on the new data. Another defect of the neural networks is the fact that they are based on gradient descend method, but this method is slow at the time and often converge to the wrong vector. Recently other method called Kalman filter (see (section-15.9) [2] ) which is more reliable and faster been suggested to replace the gradient descend method.
. Recent advances in theory of neural networks provide us with robots and comprehensive approach that can be applied to wide range of problems. At this end we can indicate some of the main differences between neural network and conventional algorithm. The back propagation neural networks, given the input will provide us the out put in no time. But the conventional algorithm has to do the same job over and over again. On the other hand in reality the algorithms driving the neural networks are quite massy and are never bug free. This means that the system can crash once given a new data. Hence the con- ventional methods will usually produce more precise outputs because they repeat the same process on the new data. Another defect of the neural networks is the fact that they are based on gradient descend method, but this method is slow at the time and often converge to the wrong vector. Recently other method called Kalman filter (see (section-15.9) [2] ) which is more reliable and faster been suggested to replace the gradient descend method.
3. On the Nature of Dynamic Systems Induced from Energy Functions
In order to solve optimization problems using neural network machinery we first construct a corresponding energy function E, such that the optimum of E will coincide with the optimum point for the optimization problem. Next the energy function E, that is usually positive will induce the dynamic system![]() . The trajectories of
. The trajectories of ![]() will converge hyperbolically to local optimums of our optimization problem. Finally we construct the neural network
will converge hyperbolically to local optimums of our optimization problem. Finally we construct the neural network ![]() which is the digitized version of
which is the digitized version of![]() , where depending on initial points it will converge to some local optimum. As we indicated in section-1, certain category of dynamic system which is called Hopfield and its generalization which is called Cohen and Grossberg dynamic system will induce a system of neural networks that are able to solve some well known NP problems. More recently the more advanced dynamic systems based on generalization of the above dynamic systems been used in [4] to to solve or prove many interesting problems including four color theorem. In the following sequence of lemmas and theorems, we are going to show that if the dynamic system L satisfies certain commuting condition, then it can be induced from an energy function
, where depending on initial points it will converge to some local optimum. As we indicated in section-1, certain category of dynamic system which is called Hopfield and its generalization which is called Cohen and Grossberg dynamic system will induce a system of neural networks that are able to solve some well known NP problems. More recently the more advanced dynamic systems based on generalization of the above dynamic systems been used in [4] to to solve or prove many interesting problems including four color theorem. In the following sequence of lemmas and theorems, we are going to show that if the dynamic system L satisfies certain commuting condition, then it can be induced from an energy function![]() , which is not usually positive and all its trajectories converge hyperbolically to a corresponding attractor points. Furthermore the attractor corresponding to the global opti- mum is located on the non trivial trajectory. Note that the energy function that is induced from optimization scenario is always positive and the corresponding dynamic system
, which is not usually positive and all its trajectories converge hyperbolically to a corresponding attractor points. Furthermore the attractor corresponding to the global opti- mum is located on the non trivial trajectory. Note that the energy function that is induced from optimization scenario is always positive and the corresponding dynamic system![]() , is a commuting dynamic system.
, is a commuting dynamic system.
Suppose we are given dynamic system L, as in the following,
![]()
Also the above equation can be expressed as
![]() .
.
Definition 2.1 We say that the above system L satisfies the commuting condition if for each two indices
![]() we have
we have
![]() .
.
This is very similar to the properties of commuting squares in the V.Jones index theory [5] .
The advantage of commuting system as we will show later is that each trajectory ![]() passing through an initial point
passing through an initial point![]() , will converge to the critical point
, will converge to the critical point![]() , and
, and ![]() is asymptotically stable.
is asymptotically stable.
In particular note that if the dynamic system is induced from an energy function E, then the induced neural network![]() , is robot and stable. In the sense that beginning from one point
, is robot and stable. In the sense that beginning from one point![]() , the neural network will asymptotically will converge to a critical point. This property plus some other techniques make it possible to find the optimum value of E. The following lemma will lead us to the above conclusions.
, the neural network will asymptotically will converge to a critical point. This property plus some other techniques make it possible to find the optimum value of E. The following lemma will lead us to the above conclusions.
Lemma 2.2 Suppose the dynamic system L has a commuting property. Then there exists a function ![]() acting on
acting on ![]() such that for every integer
such that for every integer ![]() we have
we have
![]() .
.
Furthermore for every trajectory![]() ,
, ![]() and
and ![]() only on the corresponding critical point
only on the corresponding critical point ![]() on which
on which![]() .
.
Proof Let us pick up an integer![]() . Next define
. Next define![]() . Then for any integer
. Then for any integer![]() , we
, we
have![]() . finally we have,
. finally we have,
![]() .
.
And the equality holds, i.e. ![]() only on the critical point
only on the critical point ![]() on which
on which![]() . Q.E.D.
. Q.E.D.
But the problem is that the induced ![]() in Lemma 2.2 is not always a positive function. In the case that
in Lemma 2.2 is not always a positive function. In the case that ![]() is a positive function we have the following lemma.
is a positive function we have the following lemma.
Lemma 2.3 Following the notation as in the above suppose L is a commuting system and that ![]() is analytical function. Next let
is analytical function. Next let ![]() be the critical point for the system L which is on non trivial trajectory with
be the critical point for the system L which is on non trivial trajectory with![]() . Then
. Then ![]() is asymptotically stable.
is asymptotically stable.
Proof. Following the definition of Liaponov function and using Lemma 2.2, the fact that ![]() implies that regarding to the trajectory passing through
implies that regarding to the trajectory passing through![]() , it is asymptotically stable. Q.E.D.
, it is asymptotically stable. Q.E.D.
There are some cases that we can choose ![]() to be a positive function as we will show in the following lemma.
to be a positive function as we will show in the following lemma.
Lemma 2.4 Keeping the same notations as in the above, suppose that there exists a number![]() , such that
, such that ![]() for all
for all![]() . Then there exists a positive energy function
. Then there exists a positive energy function ![]() for the dynamic system L.
for the dynamic system L.
Proof. Let us define ![]() acting on
acting on ![]() by
by![]() . Then
. Then ![]() is a positive function. Furthermore
is a positive function. Furthermore
![]() and over the trajectories
and over the trajectories![]() , it is equal to zero only over the attracting points. This will complete the proof of the lemma. Q.E.D.
, it is equal to zero only over the attracting points. This will complete the proof of the lemma. Q.E.D.
Lemma 2.5 Let L be a commuting dynamic system. Let ![]() be the induced energy function. Then if
be the induced energy function. Then if ![]() is a point on a non trivial trajectory on which
is a point on a non trivial trajectory on which![]() , achieves an optimum
, achieves an optimum![]() , then the trajectory passing through
, then the trajectory passing through ![]() will converge asymptotically to
will converge asymptotically to![]() .
.
Proof Set![]() , then using Lemma 2.4
, then using Lemma 2.4 ![]() is an energy function for L and since
is an energy function for L and since
![]() we are done. Q.E.D.
we are done. Q.E.D.
Suppose L is a commuting dynamic system. Let ![]() be an induced energy function. The main goal of the corresponding neural network
be an induced energy function. The main goal of the corresponding neural network ![]() is to reach a point
is to reach a point ![]() at which
at which ![]() will get its optimum value. In Lemma 2.5, we proved that any non trivial trajectory passing through
will get its optimum value. In Lemma 2.5, we proved that any non trivial trajectory passing through ![]() will converges to
will converges to ![]() asymptotically. In the following we show that in general the above property holds for any attracting point of commuting dy- namic systems.
asymptotically. In the following we show that in general the above property holds for any attracting point of commuting dy- namic systems.
Lemma 2.6 Suppose L is a commuting dynamic system and ![]() an attractive point. Then the trajectory passing through
an attractive point. Then the trajectory passing through ![]() will converge asymptotically to
will converge asymptotically to![]() .
.
Proof Let![]() . Next define the function
. Next define the function ![]() acting on
acting on![]() , by
, by![]() . In order to
. In order to
complete the proof we have to show that with regard to the trajectory ![]() passing through
passing through![]() ,
, ![]() is a Liapunov function. For this it is enough to show that
is a Liapunov function. For this it is enough to show that![]() . But
. But
![]() . Finally the fact that
. Finally the fact that ![]() implies
implies
that ![]() and this complete the proof. Q.E.D.
and this complete the proof. Q.E.D.
Suppose L is a commuting dynamic system and ![]() is a point on some non trivial trajectory at which
is a point on some non trivial trajectory at which ![]() reaches its infimum. We want to find a conditions that guarantees the existence of a non trivial trajectory passing through
reaches its infimum. We want to find a conditions that guarantees the existence of a non trivial trajectory passing through![]() .
.
Definition 2.6 Keeping the same notation as in the above, for a commuting dynamic system L, we call ![]()
canonical if for each critical point![]() , with
, with![]() , we have
, we have![]() .
.
Before proceeding to the next theorem let us set the following notations.
Let ![]() and
and![]() . Furthermore for
. Furthermore for![]() , let
, let ![]() be the first
be the first
point at which the trajectory ![]() will intersect
will intersect![]() .
.
Lemma 2.7 Following the above notations suppose without loss of generality, ![]() , and that there is no trajectory passing through a point
, and that there is no trajectory passing through a point ![]() and converging to
and converging to![]() . Then there exists
. Then there exists ![]() and a sequences
and a sequences
![]() and
and![]() , such that for each
, such that for each![]() ,
, ![]() will intersect
will intersect ![]() first time at the point
first time at the point![]() .
.
Proof. Otherwise for each![]() , there exists a positive number
, there exists a positive number ![]() such that for any positive number
such that for any positive number
![]() , and a point
, and a point![]() , the trajectory
, the trajectory ![]() will lie in
will lie in![]() . This implies the existence of the sequence
. This implies the existence of the sequence ![]() converging to
converging to![]() , such that for each
, such that for each![]() ,
,![]() . hence assuming that
. hence assuming that
![]() is analytic this implies that
is analytic this implies that ![]() which is a contradiction. Q.E.D.
which is a contradiction. Q.E.D.
Theorem 2.8 Keeping the same notation as in the above, suppose we have a commuting system L, with the induced energy function![]() , being canonical. Suppose there exists a point
, being canonical. Suppose there exists a point![]() , with
, with![]() . Then there exists a non trivial trajectory
. Then there exists a non trivial trajectory![]() , converging to
, converging to![]() .
.
Proof. Suppose there is no non trivial trajectory passing through![]() . Next for any
. Next for any![]() , let us choose
, let us choose![]() , with
, with![]() . Furthermore let
. Furthermore let![]() , be the trajectory through the point
, be the trajectory through the point![]() . Now let
. Now let![]() , and
, and
![]() be as indicated at Lemma 2.7. Next for
be as indicated at Lemma 2.7. Next for![]() , consider
, consider![]() , passing through
, passing through![]() . Let
. Let
![]() be the first point at which
be the first point at which ![]() intersect
intersect![]() . We have,
. We have,
![]() . Now consider the trajectory
. Now consider the trajectory![]() . Let us denote by
. Let us denote by
![]() , the time at which the trajectory
, the time at which the trajectory ![]() arrives at
arrives at![]() . This implies,
. This implies,
![]() .
.
Thus, applying mean value theorem implies
![]() , with
, with![]() . (1)
. (1)
To complete the proof of the Theorem 2.8, we need the following lemma.
Lemma 2.9 Keeping the same notations as in the above then there exists a ![]() such that for
such that for ![]() large enough, there exists a positive number
large enough, there exists a positive number![]() , with the property that for every
, with the property that for every![]() , j, large enough,
, j, large enough,
![]() .
.
Proof. Otherwise there exists a sequence of numbers ![]() such that
such that ![]() as
as![]() , where for each
, where for each![]() , we have
, we have ![]() as
as![]() . Thus considering the Equation (1), and the fact That for the
. Thus considering the Equation (1), and the fact That for the
indices ![]() large enough we have
large enough we have![]() ,
, ![]() , we can write,
, we can write,
![]() ,
,
![]() .
.
This using the fact that ![]() is canonical will lead to contradiction. Q.E.D
is canonical will lead to contradiction. Q.E.D
To complete the proof of theorem 2.8, note that for every point![]() , the points located on the trajectory
, the points located on the trajectory
![]() , can be expressed as a continuous function
, can be expressed as a continuous function![]() , of
, of ![]() and t. The function
and t. The function ![]() acts on the set
acts on the set![]() , which is a compact set. Hence there exists a number Length such that
, which is a compact set. Hence there exists a number Length such that
![]() for all
for all![]() . Next for each
. Next for each ![]() we divide
we divide ![]() into
into ![]() part
part
each of length equal to![]() . Let us define the following points,
. Let us define the following points, ![]() be the
be the
points corresponding to the above partitions. Furthermore consider the following countable set of points.
![]() . Furthermore for each triple
. Furthermore for each triple![]() , let us define a point
, let us define a point ![]() to be a limit point of the set
to be a limit point of the set![]() . Finally consider the following set
. Finally consider the following set![]() .
.
Then the set ![]() the closure of S in
the closure of S in ![]() is an non trivial trajectory passing through
is an non trivial trajectory passing through ![]() But this is a con- tradiction to our assumption. Q.E.D.
But this is a con- tradiction to our assumption. Q.E.D.
Lemma 2.10 Keeping the same notations as in the above, suppose for a given commuting system L the induced energy function ![]() is positive function. Then
is positive function. Then ![]() is canonical.
is canonical.
Proof. If ![]() is not canonical then there exist an increasing sequences of positive numbers,
is not canonical then there exist an increasing sequences of positive numbers, ![]() as
as
![]() , and
, and ![]() as
as![]() , such that for each
, such that for each![]() , there exists a point
, there exists a point![]() , at the distance of less
, at the distance of less
than ![]() from
from ![]() with
with![]() .
.
Next we can assume that there exists a line ![]() in
in ![]() connecting sequence of points
connecting sequence of points ![]() to the limiting
to the limiting
point![]() , such that
, such that![]() . But
. But![]() , thus using Hopital lemma,
, thus using Hopital lemma,
![]() .
.
Let us set![]() . Then by the above,
. Then by the above,![]() . Next if
. Next if
![]() , then using Hopital lemma we have,
, then using Hopital lemma we have,![]() . continue this process suppose using induction that
. continue this process suppose using induction that![]() , then we get by Hopital lemma,
, then we get by Hopital lemma,
![]() .
.
Now if for each![]() ,
, ![]() , then using the fact that
, then using the fact that ![]() is analytic function we
is analytic function we
get that![]() . which is a contradiction. Hence there exists an integer
. which is a contradiction. Hence there exists an integer![]() , such that
, such that
![]() but
but![]() . Therefore the above arguments imply that
. Therefore the above arguments imply that
![]() , and this is a contradiction to the assumption. Q.E.D.
, and this is a contradiction to the assumption. Q.E.D.
As a result of the Lemma 2.10 we get that if ![]() the system L is always canonical, hence we have the the following corollary, Corollary 2.11 Keeping the same notations as in the above, The results of Theorem 2.8 holds as long as
the system L is always canonical, hence we have the the following corollary, Corollary 2.11 Keeping the same notations as in the above, The results of Theorem 2.8 holds as long as![]() .
.
At this point we have to mention that non trivial trajectories will supply us with much more chance of hitting the global optimum, once we perform a random search to locate it.
For some dynamic systems L which is expressed in the usual form![]() , the commuting condition does not hold. For example consider the Hopfield neural network and its corresponding dynamic system,
, the commuting condition does not hold. For example consider the Hopfield neural network and its corresponding dynamic system,
![]() ,
,
where![]() . It is clear that the above system does not posses commuting properties. Let us multiply both side of the i'th equation in the above by
. It is clear that the above system does not posses commuting properties. Let us multiply both side of the i'th equation in the above by![]() , to get the dynamic system
, to get the dynamic system![]() , given in the
, given in the
following as, ![]() , therefore we get,
, therefore we get,
![]() (2)
(2)
Let us denote ![]() and
and![]() , the the dynamic system
, the the dynamic system ![]() can be expressed as
can be expressed as
![]() .
.
It is clear that if ![]() is a trajectory of the system L, and provided
is a trajectory of the system L, and provided![]() , then
, then ![]() is a trajectory of system
is a trajectory of system ![]() too. Now the commuting property holds for the right side of Equation (2), hence using the same techniques as before we can construct the energy function
too. Now the commuting property holds for the right side of Equation (2), hence using the same techniques as before we can construct the energy function ![]() for the system (2) such that,
for the system (2) such that, ![]() , furthermore we have
, furthermore we have
![]() .
.
This implies that ![]() except on the attractive points. Now by the results of the Lemma 2.3, this implies
except on the attractive points. Now by the results of the Lemma 2.3, this implies
that for any trajectory![]() , the convergent asymptotically to the corresponding attractive point
, the convergent asymptotically to the corresponding attractive point![]() .
.
As we mentioned before more generalized version of Hopfield dynamic system which is called Cohen and Grossberg dynamic system is given as in the following.
![]() (3)
(3)
where the set of coefficients![]() , will satisfy,
, will satisfy,![]() . Furthermore
. Furthermore
![]() .
.
Likewise the system (2), system (3) is not a commuting system. But if we multiply both side of the ith equation in system (3) by ![]() then we get a dynamic system where its right side is commuting. Hence each of the trajectories converge asymptotically to corresponding attracting point.
then we get a dynamic system where its right side is commuting. Hence each of the trajectories converge asymptotically to corresponding attracting point.
4. Reduction of Certain Optimization Problems to Linear or Quadratic Programming
In solving optimization problems using neural network we first form an energy function![]() , corresponding to the optimization problem. Next the above energy will induces the dynamic system L that its trajectories converge to local optimum solutions for the optimization problem.
, corresponding to the optimization problem. Next the above energy will induces the dynamic system L that its trajectories converge to local optimum solutions for the optimization problem.
Given the energy function ![]() acting on
acting on![]() , the induced dynamic system L is given in the following,
, the induced dynamic system L is given in the following,
![]() .
.
As we showed L is a commuting system.
As an example consider the travelling salesman problem. As it has been expressed in section 4.2, page 77 of [1] the energy function E is expressed as in the following,
![]()
where we are represent the points to be visited by travelling salesman as ![]() and the distance of point
and the distance of point ![]() to the point
to the point ![]() by
by![]() . Since in solving optimization problems using neural network we are interested in variables that are of 0 or 1 nature therefore let us define new set of variables by,
. Since in solving optimization problems using neural network we are interested in variables that are of 0 or 1 nature therefore let us define new set of variables by,
![]() ,
,![]() .
.
Thus the dynamic system L corresponding to E, can be written as in the following,
![]()
As we proved the point at which E reaches its optimum is a limiting point![]() , of a trajectory belonging to the dynamic system L. as given in the above.
, of a trajectory belonging to the dynamic system L. as given in the above.
Next as we had,
![]() .
.
But ![]() hence we get the following dynamic system
hence we get the following dynamic system![]() ,
,
![]() .
.
Thus as we showed the system ![]() is a commuting system and its critical points coincides with the critical points of the system L.
is a commuting system and its critical points coincides with the critical points of the system L.
Now consider the following set of variables![]() ,
, ![]() , where we choose the set
, where we choose the set![]() . to satisfy,
. to satisfy,
![]() .
.
Hence we will have the following set of equations,
![]() .
.
Replacing ![]() by
by ![]() in equations of system
in equations of system ![]() implies,
implies,
![]() .
.
But ![]() as,
as, ![]() , which implies that,
, which implies that, ![]() as
as![]() , hence this implies that the above
, hence this implies that the above
equations together with the optimality of the expression ![]() is a system of
is a system of
quadratic linear programming that will give us the optimum value much faster that usual neural network. In fact this method can be applied to many types of optimization problems which guaranties fast convergent to desired critical point.
Let us consider the Four color Theorem. The similar scenario to Four color Theorem is to consider the have two perpendicular axis X and Y and sets of points ![]() on X axis and the set of points
on X axis and the set of points
![]() on the Y axis. with
on the Y axis. with ![]() and
and![]() . Let us set the following four points
. Let us set the following four points![]() . We want to connect the points of the sets
. We want to connect the points of the sets ![]() to
to ![]() such that the connecting line will intersect only out side the square
such that the connecting line will intersect only out side the square![]() . Now suppose we take a point
. Now suppose we take a point ![]() and
and![]() ,
, ![]() and
and![]() . Next connecting the points
. Next connecting the points ![]() and
and ![]() will give us the
will give us the
line![]() . Connecting the points
. Connecting the points ![]() and
and ![]() will give us the line
will give us the line![]() . We want to choose the lines
. We want to choose the lines ![]() and
and ![]() such that the point z which is the intersection of
such that the point z which is the intersection of ![]() and
and ![]() will stay outside the square
will stay outside the square![]() . Suppose
. Suppose
![]() . Then the above condition is equivalent to the fact that either
. Then the above condition is equivalent to the fact that either ![]() or
or![]() . But
. But
![]() . Now the above condition is equivalent to the following set of inequalities,
. Now the above condition is equivalent to the following set of inequalities,
Case-1. If![]() , then either
, then either ![]() or
or![]() . or symmetrically,
. or symmetrically,
Case-2. If![]() , then either
, then either ![]() or
or![]() .
.
Next let us take the set of following variables, ![]() and
and![]() , with
, with ![]() and
and
![]() . Furthermore consider the following equalities,
. Furthermore consider the following equalities,
![]() , for all
, for all![]() .
.
![]() , for all
, for all![]() .
.
Furthermore let us set the following energy function to be optimize,
![]() also we must meet the conditions of Case-1 and Case-2 over the indices.
also we must meet the conditions of Case-1 and Case-2 over the indices.
Now the above system is equivalent to find the optimum solution for coloring.
So as before assuming, ![]() we have,
we have, ![]() and
and
![]() .
.
This implies, ![]() with
with![]() .
.
Next let us define ![]()
On the other hand it is easy to show that ![]() with
with![]() .
.
Next let us define,![]() .
.
Finally if the following inequalities holds,
![]()
![]()
where the indices satisfy, the conditions of Case-1 and Case-2. then as t tends to infinity we have, ![]() and
and![]() .
.
At this point using the above arguments it is enough to find Q, and P, satisfying the above equalities and will optimize the following expression,
![]() and
and![]() .
.
Therefore the above equations together with optimization expression will form a system of linear programming that will converge to the optimal solution at no time.
5. Conclusion
In this article we introduced the methods of approximating the solution to optimization problems using neural networks machinery. In particular we proved that for certain large category of optimization problems the appli- cation of neural network methods guaranties that the above problems will be reduced to linear or quadratic programming. This will give us very important conclusion because the solution of the optimization problems in these categories can be reached immediately.