Quantum-Inspired Neural Network with Quantum Weights and Real Weights ()
1. Introduction
In 1980s, Benioff firstly proposed the concept of quantum computation [1] . Shor discussed the first quantum algorithm of very large integer factorization [2] in 1994. In 1996, Grover explored an important quantum algorithm, which can search for a marked state in an unordered list [3] . Although the quantum machines are not yet technologically feasible, the quantum algorithms that can be applied on the quantum computers are indeed interesting and significantly different from the classical computing. As we know, fuzzy logic, evolutionary computation, and neural networks are regarded as intelligent computing (soft computing), and also have some comparability with the quantum computation [4] . Therefore, combination of these computing methods is emerging. Different from the Hebbian learning, a quantum neural network can be used for the enriched learning of neural networks. Proposed by Penrose in 1989 [5] , the idea of quantum information processing in the human brain was still a controversial theory, which has not been experimentally proved. However, the exploration of quantum information devices is a promising research topic, because of the enhanced capacity and speed from the quantum mechanism. With characteristics such as smaller size of quantum devices, larger capacity of quantum networks and faster information processing speed, a quantum neural network can mimic some distinguishing properties of the brain better than the classical neural networks, even if the real human brain does not even have any quantum element. In a word, the quantum neural networks have important research significance in both theory and engineering.
Since Kak firstly proposed the concept of quantum neural computation [6] in 1995, the quantum neural networks had attracted great attention during the past decade, and a large number of novel techniques had been studied for the quantum computation and neural networks. For example, Ref. [7] proposed the model of quantum neural networks with multi-level hidden neurons based on the superposition of quantum states in the quantum theory. Ref. [8] proposed a neural network model with quantum gated nodes and a smart algorithm for it, which showed superior performance in comparison with a standard error back propagation network. Ref. [9] proposed a weightless model based on quantum circuit. It is not only quantum-inspired but is actually a quantum NN. This model is based on Grover’s search algorithm, and it can perform both quantum learning and simulate the classical models. Ref. [10] proposes the neural networks with the quantum gated nodes, and indicates that such quantum networks may contain more advantageous features from the biological systems than the regular electronic devices. Ref. [11] have proposed a quantum BP neural networks model with learning algorithm based on the single-qubit rotation gates and two-qubit controlled-NOT gates.
In this paper, we study a new hybrid quantum-inspired neural networks model with quantum weights and real weights. Our scheme is a three-layer model with a hidden layer, which employs the gradient descent principle for learning. The input/output relationship of this model is derived based on the physical meaning of the quantum gates. The convergence rate, number of iterations, and approximation error of the quantum neural networks are examined with different restriction error and restriction iterations. Three application examples demonstrate that this quantum-inspired neural network is superior to the classical BP networks.
2. Quantum-Inspired Neural Network Model
2.1. Qubits and Quantum Rotation Gate
In the quantum computers, the “qubit” has been introduced as the counterpart of the “bit” in the conventional computers to describe the states of the circuit of quantum computation. The two quantum physical states labeled as 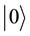 and
and 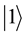 express 1 bit information, in which
express 1 bit information, in which 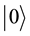 corresponds to the bit 0 of classical computers, while
corresponds to the bit 0 of classical computers, while 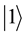 bit 1. Notation of “
bit 1. Notation of “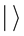 ” is called the Dirac notation, which is the standard notation for the states in the quantum mechanics. The difference between bits and qubits is that a qubit can be in a state other than
” is called the Dirac notation, which is the standard notation for the states in the quantum mechanics. The difference between bits and qubits is that a qubit can be in a state other than  and
and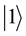 . It is also possible to form the linear combinations of the states, namely superpositions
. It is also possible to form the linear combinations of the states, namely superpositions
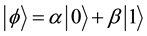 (1)
(1)
where 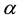 and
and 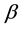 are complex numbers, called probability amplitudes. That is, the qubit state
are complex numbers, called probability amplitudes. That is, the qubit state 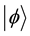 collapses into either
collapses into either 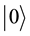 state with probability
state with probability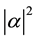 , or
, or 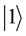 state with probability
state with probability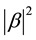 , and we have
, and we have
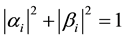 . (2)
. (2)
Hence, the qubit can be described by the probability amplitudes as![]() .
.
Suppose we have n qubits, and correspondingly, a n qubits system has ![]() computational basis states. Similar to the case of a single qubit, the n qubits system may form the superpositions of
computational basis states. Similar to the case of a single qubit, the n qubits system may form the superpositions of ![]() basis states:
basis states:
![]() (3)
(3)
where ![]() is called probability amplitude of the basis states
is called probability amplitude of the basis states![]() , and “
, and “![]() ” means “the set of strings of length two with each letter being either zero or one”. The condition that these probabilities can sum to one is expressed by the normalization condition
” means “the set of strings of length two with each letter being either zero or one”. The condition that these probabilities can sum to one is expressed by the normalization condition
![]() . (4)
. (4)
In the quantum computation, the logic function can be realized by applying a series of unitary transform to the qubit states, which the effect of the unitary transform is equal to that of the logic gate. Therefore, the quantum services with the logic transformations in a certain interval are called the quantum gates, which are the basis of performing the quantum computation.
The definition of a single qubit rotation gate is given
![]() . (5)
. (5)
Let the quantum state![]() , and
, and ![]() can be transformed by
can be transformed by ![]() as follows:
as follows:
![]() (6)
(6)
It is obvious that ![]() shifts the phase of
shifts the phase of![]() .
.
2.2. Quantum-Inspired Neuron Model
A neuron can be described as a four elements array: (input, weight, transform function, output), where input and output is the outer attribute of the neuron, and weight and transform function are the inner attribute of the neuron. Therefore, the different neuron models can be constructed by modifying types of weight and transform function. According this viewpoint, for the quantum-inspired neuron proposed in this paper, the weights are represented by qubits, and the transform function is represented by inner-product operator. The difference from the traditional neuron is that the quantum-inspired neuron carries a group of single-bit quantum gates that modify the phase of quantum weights. The quantum-inspired neuron model is shown in Figure 1.
In quantum-inspired neuron model, the weights are represented by qubits![]() . Let
. Let ![]() is the input real vector, y is an output real number,
is the input real vector, y is an output real number, ![]() is the quantum weight, the input/output relation of quantum-inspired neuron can be described as follows:
is the quantum weight, the input/output relation of quantum-inspired neuron can be described as follows:
![]() (7)
(7)
where ![]() is an inner product operator,
is an inner product operator, ![]() ,
, ![]() , the
, the ![]() is a quantum rotation gate to modify the phase of the
is a quantum rotation gate to modify the phase of the![]() .
.
2.3. Quantum-Inspired Neural Network Model
Quantum-inspired Neural Network (QINN) is defined as the model that all the input, output, and linked weights for each layer may be qubits. The QINN structure is the same as the general ANN which includes input layer, hidden layer, and output layer. Obvious, the network including neuron in Figure 1 is QINN. The QINN only including quantum neurons is defined as the normalization QINN, and the QINN including quantum neurons and general neurons is defined as the hybrid QINN. Since QINN transform function adopts linear operator, the non-
![]()
Figure 1. Quantum-inspired neuron model.
linear mapping capability falls under restriction. Therefore, this paper considers the hybrid QINN (HQINN) including a hidden layer of quantum neuron, which holds the advantage of the quantum computing and the nonlinear mapping capability of the general ANN. HQINN model is presented in Figure 2.
The model includes three layers, the input layer and output layer contains n and m general neurons, respectively, and the hidden layer contains p quantum-inspired neurons. The input/output relation can be described as follows:
![]() (8)
(8)
where![]() ;
;![]() ;
;![]() ,
, ![]() is the linked weight between the jth neuron in hidden layer and the kth neuron in output layer, g is the Sigmoid function or Gauss function.
is the linked weight between the jth neuron in hidden layer and the kth neuron in output layer, g is the Sigmoid function or Gauss function.
2.4. Learning Algorithm
For the HQINN in Figure 2, when transform function in output layer is continuous and differentiable, the learning algorithm may adopt BP algorithm. The output error function is defined as follows:
![]() (9)
(9)
where ![]() represents the desired output.
represents the desired output.
According to BP algorithm, the modifying formula for output layer weight is described as follows:
![]() (10)
(10)
where, ![]() ,
, ![]() ,
, ![]() represents the learning ratio, and t represents the iteration steps.
represents the learning ratio, and t represents the iteration steps.
The weights between the input layer and quantum hidden layer are modified by quantum rotation gates described as follows:
![]() (11)
(11)
where![]() ,
,![]() . According BP algorithm, the
. According BP algorithm, the ![]() can be gained from the following formula.
can be gained from the following formula.
![]() (12)
(12)
where ![]() is the phase of the
is the phase of the![]() . For
. For![]() , the modifying formula is described as follows.
, the modifying formula is described as follows.
![]()
Figure 2. Hybrid quantum-inspired neural network model.
![]() (13)
(13)
Let the vector![]() , the modifying formula of
, the modifying formula of ![]() is described as follows:
is described as follows:
![]() (14)
(14)
where t represents the iteration steps.
Synthesizing above depiction, the HQINN learning algorithm can be described as follows:
Step 1: Initialize network parameters. Include: The number of nodes in each layer, the learning ratio, the restriction error![]() , the restriction steps
, the restriction steps![]() . Set the current steps
. Set the current steps![]() .
.
Step 2: Initialize network weights. Hidden layer:![]() ,
, ![]() , and output layer:
, and output layer:![]() , where
, where ![]() is a random number in (0,1),
is a random number in (0,1), ![]() ,
, ![]() ,
,![]() .
.
Step 3: Compute network outputs according to Equation (8), modifying the weights of each layer according to Equation (10) and Equation (14), respectively.
Step 4: Compute network output error according to Equation (9), if ![]() or
or ![]() then go to Step 5,else
then go to Step 5,else![]() , go back to Step 3.
, go back to Step 3.
Step 5: Save the weights, and stop 3.
3. Simulations
To testify the validity of HQINN, two kinds of experiments are designed and the HQINN is compared with the classical BP network in this section. In two experiments, the HQINN adopts the same structure and parameters as the BP network.
3.1. Twenty-Five Sample Patterns Classification
For twenty-five sample points in Figure 3, determine the pattern of each point by HQINN. This is a typical two-pattern classification problem, which is regard as the generalization of XOR problem.
The network construct is set to
2-10-1
, and the learning ratio is set to 0.8. The HQINN and the BP network are learned 50 times, restively, and then compute the average of iteration steps. Training results are shown in Table 1. When the restriction error takes 0.05, the convergence curves are shown in Figure 4.
![]()
Figure 3. Twenty-five pattern classification samples.
![]()
Figure 4. The convergence curve comparison.
![]()
Table 1. The training results comparison between HQINN and BP network for 25 sample patterns classification.
3.2. Double Spiral Curves Classification
For two spiral curve in Figure 5, fetch 30 points from each curve, respectively, compose the sample set containing 50 sample points, and classify these points in sample set by HQINN.
The network construct is
2-20-1
, and the learning ratio is 0.7. The HQINN and the BP network are training 30 times, restively, and then compute the average of iteration steps. Training results are shown in Table 2. When the restriction error takes 0.10, the convergence curves are shown in Figure 6.
3.3. Function Approximation
In this simulation, such function is selected as follow:
![]() (20)
(20)
where![]() ,
, ![]() , and
, and ![]() are integers in the set {1, 2, 3, 4, 5}.
are integers in the set {1, 2, 3, 4, 5}.
To approximate the nonlinear function, we sample 40 groups of discrete data, half of which is used to train networks and the other half to test its performance. Set the maximum of iteration steps 5000. By changing the number of hidden neurons and the learning coefficient, we present an experimental evaluation of HQINN’s and compare their performance with that of the other algorithms. This example is simulated 30 times for each group of parameters by the HQINN, the BP, and the algorithm in Ref. [12] , respectively. When the number of hidden neurons is 6 and 8, the training result are presented in Table 3 and Table 4.
Firstly, we investigate how to change for the average convergence rate when the learning coefficient changes. The networks structure is
3-5-1
, the restriction error is 0.1, and the restriction iteration steps are 5000. The learning coefficient set is {0.1, 0.2, …, 1.0}. This example is simulated 30 times for each learning coefficient by the HQINN and the BP respectively. When the learning coefficient changes the average convergence ratio of HQINN always is 100% and is insensitive to the learning coefficient. However, the average convergence ratio of BP changes in a large range when the learning coefficient changes. The maximum of average convergence ratio of BP reaches to 80%, and the minimum is only 10%. The comparison result is shown in Figure 7.
The comparison result shows that the HQINN is evidently superior to the BP in both the average convergence ratio and the robustness.
![]()
Figure 6. The convergence curve comparison.
![]()
Figure 7. The relationship between the average convergence rate and the learning coefficient.
![]()
Table 2. The training results comparison between HQINN and BP network for double spiral curves classification.
Secondly, we investigate how to change for the average iteration steps when the learning coefficient changes. The networks structure is
3-5-1
, and the restriction error is 0.1. The learning coefficient set is still {0.1, 0.2, …, 1.0}. This example is simulated 30 times for each learning coefficient by the HQINN and the BP, respectively. When the learning coefficient changes, for the average iteration steps of HQINN, the maximum is 958 steps, the minimum is 496 steps, and the average is 693 steps. However, for the average iteration steps of BP, the maximum is 4619 steps, the minimum is 1532 steps, and the average is 2489 steps. Hence, the performance of HQINN is evidently superior to BP in both the average iteration steps and its fluctuation range when the learning coefficient changes. The comparison result is shown in Figure 8.
The comparison results show that the HQINN is evidently superior to the BP in both the average iteration steps and the robustness.
4. Conclusion
The HQINN is the amalgamation of quantum computing and nerve computing, which holds the advantage such as parallelism and high efficiency of quantum computation besides continuity, approximation capability, and generalization capability that the classical ANN holds. In HQINN, the weights are represented by qubits, and the phase of each qubit is modified by the quantum rotation gate. Since both probability amplitudes participate in optimizing computation, the computation capability is evidently superior to the classical BP network. Experimental results show that the HQINN model proposed in this paper is effective.
![]()
Figure 8. The relationship between the average iteration steps and the learning coefficient.
Table3. The simulation result for the nonlinear function approximation (the number of hidden neurons is 6).
Table4. The simulation result for the nonlinear function approximation (the number of hidden neurons is 8).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 61170132), the Scientific research and technology development project of CNPC (2013E-3809), and the Major National Science and Technology Program (2011ZX05020-007).