A Novel Hybrid Method for Measuring the Spatial Autocorrelation of Vehicular Crashes: Combining Moran’s Index and Getis-Ord Gi* Statistic ()
1. Introduction
In many vehicle crash data, geographic relationships among crashes can exist, and this phenomenon is termed spatial autocorrelation, which is a measure of the correlation of a crash with other crashes through space. Most statistical analyses are based on the assumption that the values of observations in each sample are independent of one another. Spatial autocorrelation violates this assumption, because samples taken from nearby locations are related to each other, and hence, they are statistically not independent of one another [1] [2] . Therefore, the consideration of spatial autocorrelations has been gaining attention in crash data modeling in recent years, and researchers have shown that ignoring this factor may lead to a biased estimation of the model parameters [3] - [12] . Taking the spatial autocorrelation into account in crash modeling can improve model parameter estimation, and the overall model fit [8] [13] . The spatial autocorrelation phenomenon can be best summarized by the Tobler’s first law of Geography that everything is related to everything else but those which are near to each other are more related when compared to those that are further away [14] .
Spatial autocorrelation can be positive or negative among observations. Positive spatial autocorrelation occurs when observations having similar values are closer (i.e. clustered) to one another, and negative spatial autocorrelation occurs when observations having dissimilar values occur near one another [2] [15] . Two problems may be faced when sample data has a locational dimension: 1) the existence of spatial autocorrelation between the observations, and 2) the variation of this relationship over the space that could be described as spatial heterogeneity [16] or spatial non-stationarity [17] . Hence, spatial autocorrelation must be incorporated in modeling crash data to properly account for the effect of spatial correlation and any unobserved spatial heterogeneity that may exist in the crash data. To assess spatial autocorrelation, a distance measure must be specified in order to define what is meant by two observations being close together. These distances are usually presented in the form of a weight matrix, which defines the relationships between locations at which the observations occur [18] . If data are collected at n locations, then the weight matrix will be n × n with zeroes on the diagonal. The weight matrix is often row-standardized, (i.e. all the weights in a row sum to one), and can be constructed given a variety of assumptions [2] , such as, a constant distance that represents the weight for any two different locations; a fixed weight for all observations within a specified distance; or k nearest neighbors.
2. Background Literature
The differences between the network autocorrelation and spatial autocorrelation were examined [1] . In this study, it was shown that the network autocorrelation could influence the values associated with a network link given its relationship to another link in the network. To account for these relationships, spatial autocorrelation was only modeled between neighboring (adjacent) network links. The effect of spatial autocorrelation on traffic crashes was examined by geo-coding them to the nearest intersection or ramp, and then calculating different spatial statistics such as, mean, standard deviation, and standard deviational ellipse [19] . In another study the spatial autocorrelation of road segments was examined by using the Moran’s Index [20] , and it was found that a significant level of positive spatial autocorrelation existed in the data. When investigating spatial autocorrelation among traffic crashes, [21] estimated a series of crash frequency models aggregated at the county level for the state of Texas. The rear-end crashes at signalized intersections were analyzed o model the spatial correlation between intersections [22] . In this study, three different correlation structures were considered: independent correlation, exchangeable correlation, and autoregressive correlation, where the correlation decreases as the gap between intersections increases. The models proved that high spatial correlations exist between intersections for rear-end crashes. A multivariate spatial modeling approach for excess crash frequency and severity was developed in cantons (counties) for Costa Rica [23] , and results showed that the multivariate spatial model performed better than univariate spatial models. The study also reported that the effects of spatial smoothing due to multivariate spatial random effects were evident in the estimation of no-injury collisions. Generalized Poisson models were utilized [24] to explore the spatial autocorrelation of crashes, and found that spatial correlation sharply decreases at distances exceeding 7 km, and shorter road segments with high crash frequency tend to have higher spatial dependency.
3. Global and Local Indices of Spatial Autocorrelation
There are many indices or statistics that attempt to measure spatial autocorrelation for count data, such as Moran’s index (also called Moran’s I), the Geary’s C, and the Getis-Ord G statistic. These indices can be computed as Globalor Local measures depending on the scope of the analysis. Global spatial autocorrelation measures the overall spatial autocorrelation of the entire study area, providing a single measurement of spatial autocorrelation for an entire data. Local spatial autocorrelation measures the spatial autocorrelation of individuals features and identifies the spatial patterns across the study area considering the relationship between individual features. Indices of spatial autocorrelation are based on the general index of matrix association (i.e. the Gamma Γ index). The Global Gamma index consists of the sum of the cross products of the elements aij and bij in two matrices of similarity, using spatial similarity in one matrix and value similarity in the other matrix, such that [25] :
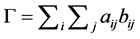 (1)
(1)
Using different value similarity would result in different indices. For example, setting 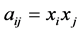 would result in Moran’s I statistic, and setting
would result in Moran’s I statistic, and setting 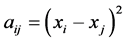 would result in Geary’ C index [25] . The Global Gamma index equals the sum of local Gamma indices within the study area. Anselin [25] outlined a general class of local indicators of spatial autocorrelation termed the Local Indicator of Spatial Autocorrelation (LISA) statistic that satisfies two conditions, first; the LISA for each point or section in the space gives an indication of significant spatial clustering (grouping) of similar or dissimilar values around that point or section, and second; the sum of LISAs for all points or sections in a given study area is proportional to a corresponding global indicator of spatial autocorrelation for that area, which implies that the LISA statistic decomposes global results into their local parts. For example, a significant global index of a study area may hide large spatial patches of no autocorrelation, and LISA can detect this and show the locations of these insignificant patches in space. Conversely, an insignificant global index may hide patches of strong autocorrelation, and LISA can detect this again.
would result in Geary’ C index [25] . The Global Gamma index equals the sum of local Gamma indices within the study area. Anselin [25] outlined a general class of local indicators of spatial autocorrelation termed the Local Indicator of Spatial Autocorrelation (LISA) statistic that satisfies two conditions, first; the LISA for each point or section in the space gives an indication of significant spatial clustering (grouping) of similar or dissimilar values around that point or section, and second; the sum of LISAs for all points or sections in a given study area is proportional to a corresponding global indicator of spatial autocorrelation for that area, which implies that the LISA statistic decomposes global results into their local parts. For example, a significant global index of a study area may hide large spatial patches of no autocorrelation, and LISA can detect this and show the locations of these insignificant patches in space. Conversely, an insignificant global index may hide patches of strong autocorrelation, and LISA can detect this again.
4. Moran’s I
Moran’s I statistic is one of the oldest indices of spatial autocorrelation and can be used to test for global and local spatial autocorrelation among continuous data. For any continuous variable, xi, a mean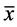 , can be calculated and the deviation of any observation from that mean can be calculated based on the cross products of the deviations from the mean. The statistic then compares the value of the variable at any one location with the values at all other locations [26] [27] [28] . For n observations on a variable x at locations i, j, Global Moran’s I can be calculated as follows [25] :
, can be calculated and the deviation of any observation from that mean can be calculated based on the cross products of the deviations from the mean. The statistic then compares the value of the variable at any one location with the values at all other locations [26] [27] [28] . For n observations on a variable x at locations i, j, Global Moran’s I can be calculated as follows [25] :
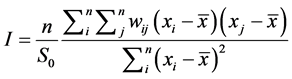 (2)
(2)
where,
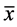 : the mean of the variable x;
: the mean of the variable x;
xi: the value of variable x at location i;
xj: the value of variable x at location j;
wij: the elements of the weight matrix;
n: number of observations;
S0: is the sum of the elements of the weight matrix: 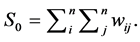
The local Moran’s I for location i can be calculated as follows:
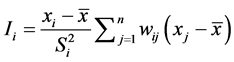 (3)
(3)
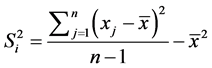 (4)
(4)
Values for this index typically, range from −1.0 to +1.0, where a value of −1.0 indicates negative spatial autocorrelation, and a value of +1.0 indicates positive spatial autocorrelation. When nearby points have similar Moran’s values, their cross product is high. Conversely, when nearby points have dissimilar Moran’s values, their cross-product is low. The expectation of Moran’s I statistic is:
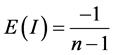 (5)
(5)
When a Moran’s I value is larger than E(I), this would indicate positive spatial autocorrelation, and if a Moran’s I is less than E(I), this would indicate negative spatial autocorrelation. In Moran’s initial formulation, the weight variable, wij, was a contiguity matrix. Therefore, if zone j is adjacent to zone i, the product receives a weight of 1.0, otherwise, the product receives a weight of 0.0. A study [29] generalized these definitions to include any type of weight, and in a wider term, wij, is a distance-based weight which is the inverse distance between locations i and j (1/dij). The z-score of Moran’s I can be computed as follows:
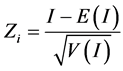 (6)
(6)
where E(I) is the expected value of I, and V(I) is the variance of I, as shown in Equation (7):
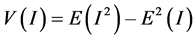 (7)
(7)
5. Getis-Ord G Statistic
The Getis-Ord G statistic is calculated with respect to a specified threshold distance (defined by the user) rather than to an inverse distance, as with the Moran’s I [30] [31] . The Global G statistic computes a single statistic for the entire study area, while the Gi statistic is an indicator for local spatial autocorrelation for each data point. The Global G statistic can be calculated as follows [32] :
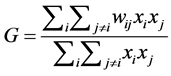 (8)
(8)
where,
xi: the value of variable x at location i;
xj: the value of variable x at location j;
wij: the elements of the weight matrix.
There are two types of local Gi statistics, although almost the two types produce identical results [31] [33] . The first one, Gi, does not include the autocorrelation of a zone with itself, whereas the 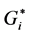 includes the interaction of a zone with itself (i.e. the Gi statistic does not include the value of Xi itself, but only the neighborhood values, but
includes the interaction of a zone with itself (i.e. the Gi statistic does not include the value of Xi itself, but only the neighborhood values, but ![]() includes Xi as well as the neighborhood values), and both can be computed by the formulae [32] :
includes Xi as well as the neighborhood values), and both can be computed by the formulae [32] :
![]() (9)
(9)
![]() (10)
(10)
where d is the neighborhood (threshold) distance, and wij is the weight matrix that has only 1.0 or 0.0 values, 1.0 if j is within d distance of i, and 0.0 if its beyond that distance. These formulae indicate that the cross-product of the value of X at location i and at another location j is weighted by a distance weight, wij which is defined by either a 1.0 if the two locations are equal to or closer than a threshold distance, d, or a 0.0 otherwise. The G statistic can vary between 0.0 and 1.0. The statistical significance of the local autocorrelation between each point and its neighbors is assessed by the z-score test and the p-value. ArcGIS uses the following formulae to calculate the local Getis-Ord ![]() [34] :
[34] :
![]() (11)
(11)
![]() (12)
(12)
![]() (13)
(13)
where,
xi: the value of variable x at location i;
xj: the value of variable x at location j;
wij: the elements of the weight matrix;
n: number of observations.
The expected G value for a threshold distance, d, is defined as:
![]() (14)
(14)
where W is the sum of weights for all pairs of locations (![]() ), and n is the number of observations. Assuming normal distribution, the variance of G(d) is defined as:
), and n is the number of observations. Assuming normal distribution, the variance of G(d) is defined as:
![]() (15)
(15)
The standard error of G(d) is the square root of the variance of G. Therefore, a z-test can be computed by:
![]() (16)
(16)
![]() (17)
(17)
6. Classification of Crash Clustering Patterns
The crash clustering patterns (i.e. type of concentration of crashes) and its statistical significance is evaluated based on the output z-scores, the correspondent p-values and the confidence level. These will determine whether a crash is classified as having a significant high spatial autocorrelation (denoted by High-High, HH), a significant low spatial autocorrelation (denoted by Low-Low, LL), a significant dispersed outlier (either a high value surrounded by low value denoted by HL, or vice versa, a low value surrounded by high value denoted by LH), or insignificant random crash. A high positive z-score for a crash point indicates a significant spatial autocorrelation (either with high values HH or with low values LL). A low negative z-score for a crash point indicates a statistically significant spatial outlier (either with high-low HL or low-high LH). A z-score of a crash point close to zero indicates that the crash is randomly and independently distributed in space. To determine if the z-score is statistically significant, it should be compared to a range of values for a particular confidence level. For example, at a significance level of 95%, a z-score would have to be less than −1.96 or greater than +1.96 to be statistically significant. Typical confidence levels are 90%, 95%, or 99%. Table 1 shows the critical p-values and z-scores for different confidence levels.
7. Data
To illustrate the analysis framework presented in this paper, Boone County, Missouri, USA crash data for the years (2013-2015) are used. Missouri crash data is reported by the Missouri State Highway Patrol (MSHP) and recorded in the Missouri Statewide Traffic Accident Records System (STARS). The total observed crashes within the three years 2013-2015 is 6886.0 along roads in Boone County. Figure 1 shows Boone County road network in Missouri and the distribution of crashes (2013-2015).
8. Methodology
In this paper ArcGIS 10.3.1 is used to compute the Moran’s I, and ![]() statistics for crash data in Boone County, Missouri for the aggregated years of 2013-2015 using the following steps:
statistics for crash data in Boone County, Missouri for the aggregated years of 2013-2015 using the following steps:
・ Spatially join the attributes of crash incidents to road segments based on their location relationship (i.e. latitude/longitude) using functionalities of a GIS that try to parse roads up into consistent analysis units and matching the two features according to their relative spatial locations;
・ Build a network of roads from the crash attributed road segments;
・ Generate spatial weights matrix for the network arcs;
・ Compute the Global Moran’s I available in the ArcMap 10.3.1 Spatial Statistics toolkit;
・ Compute the Global (General) Gi statistic available in the ArcMap 10.3.1 Spatial Statistics toolkit;
・ Compute Anselin local Moran’s I available in the ArcMap 10.3.1 Spatial Statistics toolkit;
・ Compute the local Getis-Ord local ![]() statistic available in the ArcMap 10.3.1 Spatial Statistics toolkit.
statistic available in the ArcMap 10.3.1 Spatial Statistics toolkit.
Statistically significant high spatial autocorrelation locations will have a high z-value and be surrounded by other crashes with high z-values as well (HH). Statistically significant low spatial autocorrelation locations (LL) will be found in cases where a crash point will have a low z-value and be surrounded by other
![]()
Table 1. Critical z-scores, p-values, and significance levels.
![]()
Figure 1. Boone county, MO road network and distribution of crashes (2013-2015).
crashes with low z-values as well. If the z-value of a particular crash location is higher than the mean z-value of all crashes, then it would be considered high. If the z-value of a particular crash point is lower than the mean z-value of all crashes, then it would be considered low. The resultant z-scores and p-values indicate whether crashes with either high or low z-values are clustered. A high z-score and small p-value for a crash point indicates a spatial clustering of high values (i.e. HH). A low z-score and small p-value indicates a spatial clustering of low values (i.e. LL). The higher (or lower) the z-score, the more intense the clustering. A negative z-score for a crash point indicates an outlier (i.e. a dispersed crash). A z-score near zero indicates no apparent spatial clustering (i.e. a random crash). Both the Anselin local Moran’s I and the local ![]() statistic can be computed by the ArcMap 10.3.1 Spatial Statistics toolkit [35] .
statistic can be computed by the ArcMap 10.3.1 Spatial Statistics toolkit [35] .
9. The New Hybrid Method
Since the Anselin Moran’s I and the ![]() can identify relatively different clustering patterns of crashes, therefore this paper introduces a new hybrid method to assess the spatial autocorrelation of crashes and identifies their clustering patterns. The new method combines both Moran’s I, and the
can identify relatively different clustering patterns of crashes, therefore this paper introduces a new hybrid method to assess the spatial autocorrelation of crashes and identifies their clustering patterns. The new method combines both Moran’s I, and the ![]() statistic into one new hybrid index that can improve the results. Any combination maybe used by the user depending on his/her own interpretation of the results that produces the optimal outcome. For instance, a combination of 30% Moran’s I, and 70%
statistic into one new hybrid index that can improve the results. Any combination maybe used by the user depending on his/her own interpretation of the results that produces the optimal outcome. For instance, a combination of 30% Moran’s I, and 70% ![]() is used in this paper to examine the new spatial clustering patterns of crashes. The hybrid method is applied using the Getis-Ord
is used in this paper to examine the new spatial clustering patterns of crashes. The hybrid method is applied using the Getis-Ord ![]() index available in ArcMap 10.3.1 toolkits for all crashes. The results produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values. Using different combination of Moran’s, and
index available in ArcMap 10.3.1 toolkits for all crashes. The results produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values. Using different combination of Moran’s, and![]() , such as 50% Moran’s +50%
, such as 50% Moran’s +50% ![]() could result in different cluster mapping. The user can try different combination, and choose the optimal one that produces the best interpreted results. In addition, the new hybrid method could produce new clusters if Moran’s I is used in determining the hybrid results instead of the
could result in different cluster mapping. The user can try different combination, and choose the optimal one that produces the best interpreted results. In addition, the new hybrid method could produce new clusters if Moran’s I is used in determining the hybrid results instead of the ![]() statistic.
statistic.
10. Results
Crashes occurred along the roads in Boone County, Missouri (2013-2015) are analyzed to assess whether they are spatially clustered, dispersed, or random. The Global Moran’s I and the Global (General) ![]() for the entire Boone County roads, were first calculated using the ArcMap 10.3.1 Spatial Statistics toolkit. The Global Moran’s I, and the Global
for the entire Boone County roads, were first calculated using the ArcMap 10.3.1 Spatial Statistics toolkit. The Global Moran’s I, and the Global ![]() statistic, z scores, and p-values are reported in Table 2.
statistic, z scores, and p-values are reported in Table 2.
The results of the analysis are interpreted within the context of the null hypothesis, which states that the crashes occurred in Boone County roads (2013-2015) are randomly distributed in the study area (i.e. there is no global spatial autocorrelation exists for the entire area). Since the p-values in Table 2 for both Moran’s I and the ![]() are smaller than 0.05 (using a confidence level of 95%), then this indicates that the values of Global Moran’s I and the Global
are smaller than 0.05 (using a confidence level of 95%), then this indicates that the values of Global Moran’s I and the Global ![]() are significant for the entire area, and hence, we will reject the null hypothesis, and conclude that it is quite possible that the spatial distribution of the overall Boone County road crashes is the result of clustered spatial processes.
are significant for the entire area, and hence, we will reject the null hypothesis, and conclude that it is quite possible that the spatial distribution of the overall Boone County road crashes is the result of clustered spatial processes.
Table 3 shows the results of the significant high spatial autocorrelation crashes, the significant low spatial autocorrelation crashes, outliers, and the non-sig- nificant random crashes of the Boone County roads by Anselin Moran’s I and local ![]() statistic respectively. The Moran’s I identified (2411) significant HHs crashes for the Boone County roads, whereas the
statistic respectively. The Moran’s I identified (2411) significant HHs crashes for the Boone County roads, whereas the ![]() statistic identified (2916) significant HHs crashes. The Moran’s I identified (3544) significant LLs crashes, whereas the
statistic identified (2916) significant HHs crashes. The Moran’s I identified (3544) significant LLs crashes, whereas the ![]() statistic identified (3265) significant LLs crashes. The Moran’s I identified (73) significant HLs and (38) significant LHs, compared to the
statistic identified (3265) significant LLs crashes. The Moran’s I identified (73) significant HLs and (38) significant LHs, compared to the ![]() that identified (0) significant HLs and (0) significant LHs as the
that identified (0) significant HLs and (0) significant LHs as the ![]() does not identify outliers. The Moran’s I identified (820) non-significant random crashes, compared to (705) non-significant random crashes by the
does not identify outliers. The Moran’s I identified (820) non-significant random crashes, compared to (705) non-significant random crashes by the![]() . So, it is clear that both Moran’s I and the
. So, it is clear that both Moran’s I and the ![]() statistic identify different numbers of clustering patterns.
statistic identify different numbers of clustering patterns.
Figure 2 shows the clustering patterns identified by Anselin local Moran’s I for the Boone County roads. Figure 3 shows the clustering patterns identified by the local ![]() statistic for the Boone County roads. The number and extent of HHs, LLs, and random crashes differ from one method to the other. For example, cluster #1 is identified by Moran’s I as mixed HHs, LLs, HLs, LHs and random crashes while it has been identified as mostly HHs, LLs and random crashes by
statistic for the Boone County roads. The number and extent of HHs, LLs, and random crashes differ from one method to the other. For example, cluster #1 is identified by Moran’s I as mixed HHs, LLs, HLs, LHs and random crashes while it has been identified as mostly HHs, LLs and random crashes by![]() . Clusters #2 is identified by Moran’s I as mostly random crashes, while it has been identified by
. Clusters #2 is identified by Moran’s I as mostly random crashes, while it has been identified by ![]() as mostly LLs. Cluster #3 is identified by Moran’s I as mixed LLs, HLs, and random crashes while it has been identified as mostly LLs by
as mostly LLs. Cluster #3 is identified by Moran’s I as mixed LLs, HLs, and random crashes while it has been identified as mostly LLs by![]() .
.
![]()
Table 2. Global Moran’s I and global![]() .
.
![]()
Table 3. Number of crash clustering patterns by Moran’s I and![]() .
.
![]()
Figure 2. Crash clustering patterns by Anselin local Moran’s I.
![]()
Figure 3. Crash clustering patterns by the local ![]() statistic.
statistic.
Using the new hybrid method by combining 30% Moran’s I, and 70% ![]() renders another measure of spatial autocorrelation as shown in Figure 4 for the Boone County roads. The results of the new method produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values. From Figure 4, it can be seen that cluster #1 near the city of Columbia area is mixed of HHs, LLs, and random crashes compared to mostly HHs and LLs in
renders another measure of spatial autocorrelation as shown in Figure 4 for the Boone County roads. The results of the new method produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values. From Figure 4, it can be seen that cluster #1 near the city of Columbia area is mixed of HHs, LLs, and random crashes compared to mostly HHs and LLs in ![]() and mostly outliers, HHs, and LLs in Moran’s I.
and mostly outliers, HHs, and LLs in Moran’s I.
Cluster #2 now presents insignificant random crashes compared to mostly LLs in ![]() and mostly outliers in Moran’s I. Clusters #3 becomes mostly insignificant random crashes with some LLs compared to mixed LLs, and outliers in Moran’s I and LLs in
and mostly outliers in Moran’s I. Clusters #3 becomes mostly insignificant random crashes with some LLs compared to mixed LLs, and outliers in Moran’s I and LLs in![]() . This change makes sense because clusters of LLs and random crashes are more likely happen in big cities (i.e. the City of Columbia), and clusters of HHs are more likely happen in the suburban areas of big cities [36] . These results obtained by the new hybrid method show an effective improvement in the clustering patterns of crashes along Boone County roads.
. This change makes sense because clusters of LLs and random crashes are more likely happen in big cities (i.e. the City of Columbia), and clusters of HHs are more likely happen in the suburban areas of big cities [36] . These results obtained by the new hybrid method show an effective improvement in the clustering patterns of crashes along Boone County roads.
Table 4 summarizes the HHs, LLs, HLs, LHs, and random crashes identified by Anselin local Moran’s I, the local![]() , and the new hybrid method for Boone County roads.
, and the new hybrid method for Boone County roads.
From Table 4, it can be seen that the number of the significant (HHs) and (LLs) identified by the hybrid method have decreased compared to Moran’s I and![]() . However, the number of insignificant random crashes identified by this method has increased compared to the other two methods, which indicates an improvement of the crash clustering patterns.
. However, the number of insignificant random crashes identified by this method has increased compared to the other two methods, which indicates an improvement of the crash clustering patterns.
11. Conclusion
In many vehicle crash data, locational relationships among crashes can exist
![]()
Figure 4. Crash clustering patterns by the new hybrid method.
![]()
Table 4. Number of crash clustering patterns by Moran’s I, ![]() , and the new hybrid method.
, and the new hybrid method.
given that movement is confined to roadways which are traversed by many users. This phenomenon is termed spatial autocorrelation and if not appropriately accounted for, can lead to incorrect parameter estimates in the modeling process. This paper examined two spatial autocorrelation indices: Moran’s I; and Getis-Ord ![]() statistic to differentiate between spatially clustered, dispersed, or random crash events that occurred in Boone County roads, Missouri in years (2013-2015). Since the two indices can identify relatively different numbers of clustering patterns of crashes, therefore this paper introduced a new hybrid method to assess the spatial autocorrelation of crashes and identify their clustering patterns. The new method combined both Moran’s I, and the
statistic to differentiate between spatially clustered, dispersed, or random crash events that occurred in Boone County roads, Missouri in years (2013-2015). Since the two indices can identify relatively different numbers of clustering patterns of crashes, therefore this paper introduced a new hybrid method to assess the spatial autocorrelation of crashes and identify their clustering patterns. The new method combined both Moran’s I, and the ![]() statistic into one new hybrid index that can improve the results. Any combination maybe used by the user depending on his/her own interpretation of the results that produces the optimal outcome. A combination of 30% Moran’s I, and 70%
statistic into one new hybrid index that can improve the results. Any combination maybe used by the user depending on his/her own interpretation of the results that produces the optimal outcome. A combination of 30% Moran’s I, and 70% ![]() was used in this paper to examine the new spatial clustering patterns of crashes. The hybrid method was applied using the Getis-Ord
was used in this paper to examine the new spatial clustering patterns of crashes. The hybrid method was applied using the Getis-Ord ![]() index available in ArcMap 10.3.1 toolkits for all crashes. The results produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values that effectively improved the clustering patterns of crashes.
index available in ArcMap 10.3.1 toolkits for all crashes. The results produced new statistically significant spatial clusters of high spatial autocorrelation values and low spatial autocorrelation values that effectively improved the clustering patterns of crashes.
NOTES
![]()
*PhD in Civil Engineering.