Santos Basin Wind Patterns for Planning Offshore Pre-Salt Activities ()
1. Introduction
The Santos Basin is a 352,260 square kilometers offshore pre-salt basin. It is located in the South Atlantic Ocean, approximately 300 kilometers off the southeastern coast of São Paulo, Brazil. One of the largest Brazilian sedimentary basins, it is the site of several significant pre-salt oil and gas reservoirs [1] , as shown in Figure 1.
Santos Basin contains an important drilling and oil production complex. Therefore, information about the wind, waves and currents patterns is indispensable for operational activities planning and projects.
Moreover, as the use of renewable energy system increases, more attention is being given to wind potential analysis. Theoretical models to assess the efficiency and functioning of eolic machines strongly depend on wind data.
Different methods to classify wind over a location include the principal component analysis [2] and the cluster analysis [3] [4] .
Clustering is an unsupervised learning method for statistical data analysis typically used in data mining, ma-
![]()
Figure 1. Brazilian pre-salt reservoirs. Source: petrobras.
chine learning and pattern recognition or dimension reduction.
The goal of this study is to apply a clustering method [5] to classify winds patterns of a gridded data set in Santos Basin, Brazil, using reanalysis data from the National Center for Environmental Prediction (NCEP) and National Center for Atmospheric Research (NCAR) [6] [7] .
Section 2 presented data set and study area. Section 3 describes the methodology used in this paper. Section 4 presented the results for the wind patterns. Discussion and conclusions are drawn in Section 5.
2. Wind Data
The NCEP/NCAR Reanalysis project (NCEP: National Centre for Environmental Prediction; NCAR: Prediction/National Centre for Atmospheric Research) was undertaken to support the needs of the research and climate monitoring communities and has produced a 40-year record of global analyses of atmospheric fields [6] [7] .
The project used a dynamic data assimilation model, incorporating all available rawinsonde and pilot balloon data, as well as observations from surface, ship, aircraft, satellites, and other data sources. The result is worldwide data sets of wind, temperature, and other variables on a 208 km resolution grid with over 18,000 points.
Santos Basin is located on the western boundary of the South Atlantic Ocean, between latitudes 23˚S - 28˚S and longitude 41˚W - 48˚W along the Brazilian shelf. With the Pre-Salt cluster discovery, activities near the Santos Basin have been accelerating and, consequently, the importance of information related to wind, waves and currents patterns have been increasing in this area.
The data analyzed in this work is the wind speed at 10 m above the surface, every 6 hours, for 31 years (from 1979 to 2009) in 11 grid points over Santos Basin, Brazil. These grid points are shown in Figure 2.
3. Methodology
The raw Reanalysis data are organized so that each file contains the data for the entire world for one particular date and time. Although, clustering methodology requires a time series of Reanalysis data for a particular grid point in one extract data file. This creates a significant data reordering problem to solve.
We first create subset files, taking from the original Reanalysis data files only the variables and levels we need. This process results in 372 files, one for each month of 31 years (from 1979 to 2009), containing the following information: year, month, day, hour, latitude, longitude and the u and v components of the wind.
We then select in each date file the grid points of interest and merge data in eleven files, one file for each grid point location.
After data selection, time was adjusted, once an observed condition reported at 00:00 a.m. UTC (Coordinated
![]()
Figure 2. Grid points selected over santos basin.
Universal Time) corresponds to 9:00 p.m. the previous day in Santos Basin time zone (UTC-3 hours). In addition, the wind speed module (S) was obtained, based on u and v wind speed components:
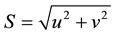 (1)
(1)
The next stage of data preparation procedure consists in arrange the sequential wind data in a matrix format, composed by 24 hour wind speed vectors. Theses vectors contain data (wind speed) at five consecutive hours: 03:00 a.m., 09:00 a.m., 03:00 p.m., 09:00 p.m. and 03:00 a.m. next day.
After data preparation, wind speed vectors were separated into constituent groups by using cluster analysis techniques in each grid point file.
In cluster analysis the objective is to divide a set of observations (here the collection of gridded wind field data at various times of the year) into groups or clusters in such a way that most pairs of observations which are placed in the same cluster are more similar to each other than are pairs of observations which are placed in two different clusters.
The most intuitive and frequently used criterion function in partitional clustering techniques is the squared error criterion, which tends to work well with isolated and compact clusters. The squared error for a clustering of a dataset containing k clusters is:
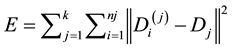 (2)
(2)
where 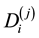 is the ith object belonging to the jth cluster and Dj is the centroid of the jth cluster.
is the ith object belonging to the jth cluster and Dj is the centroid of the jth cluster.
The k-means method [8] starts with a random initial partition and keeps reassigning the objects to clusters based on the similarity between the object and the cluster centers until a convergence criterion is met. The algorithm can be briefly described as follows:
1) Choose, randomly, k objects to define the initial cluster centers.
2) Assign each object to the closest cluster center.
3) Recompute the cluster centers using the current cluster memberships.
4) If a convergence criterion is not met, go to step 2, else, the end.
k-means method was applied in each grid point file resulting in 24 hour wind speed vectors groups. The group centers represent the wind patterns for each grid point location.
The program used for the cluster analysis is called StarCluster [9] .
4. Results
Grid point files were processed by the clustering technique. The resulting group centers represent wind patterns for these point locations.
It had been identified four representative wind patterns for all eleven points, as shown in Figure 3.
Pattern 1: Strong winds during the whole day, increasing slightly at 3:00 PM. The group corresponds to 21% of the days and occurs 33% in winter, 31% in spring, 17% in summer and 19% in fall.
Pattern 2: Moderate winds (higher than average) from 3:00 AM until 3:00 PM, after that decay to minimal intensities. The group corresponds to 23% of the days and occurs 25% in winter, 27% in spring, 24% in summer and 24% in fall.
Pattern 3: Light winds from 3:00 AM until 9:00 AM, after that increase to stronger intensities. The group corresponds to 26% of the days and occurs 28% in winter, 21% in spring, 24% in summer and 27% in fall.
Pattern 4: Light winds during the whole day, increasing slightly at 3:00 PM. The group corresponds to 30% of the days and occurs 19% in winter, 21% in spring, 31% in summer and 29% in fall.
Patterns are similar in variance, but they have different absolute values in each grid point location, as presented in Table 1. The average wind speed increases from the coastline to the open sea.
![]()
Table 1. Wind speed patterns at grid points.
5. Conclusions
The application of k-means clustering method to the Santos Basin (Brazil) wind data demonstrated to be an effective technique to create a manageable set of relatively homogeneous wind classes.
The wind speed clustering, using 31 years (1979 to 2009) of NCEP/NCAR reanalysis data over Santos Basin (Brazil), results in four representative wind patterns:
- Pattern 1 corresponds to strong winds during the whole day (21% of the days). This pattern has a higher occurrence during the winter (33%) and spring (31%) months;
- Pattern 2 corresponds to moderate winds from 3:00 AM until 3:00 PM, decaying to minimal intensities (23% of the days). This pattern occurs with a similar frequency throughout the year;
- Pattern 3 corresponds to light winds from 3:00 AM until 9:00 AM, increasing to higher intensities (26% of the days). This pattern is slightly more frequent during winter (28%) and fall (27%);
- Pattern 4 corresponds to light winds during the whole day, increasing slightly at 3:00 PM (30% of the days). This pattern has a higher frequency in summer (31%) and fall (29%) months.
The results of this paper contribute with wind patterns that can be employed in drilling and oil production activities planning. Moreover, Brazil’s offshore wind power productivity is promising; therefore, the results could be used directly in theoretical models of renewable energy systems, which strongly depend on wind assumptions.