Agglomerative Approach for Identification and Elimination of Web Robots from Web Server Logs to Extract Knowledge about Actual Visitors ()
1. Introduction
Web robots are autonomous agents used to browse the web in a mechanized and organized manner. They are also known as web crawlers, spiders, wanderers, and harvesters etc. They start their working with seed URLs lists and recursively visit hyperlinks accessible from that list. The purpose of crawlers is to discover and retrieve content and knowledge from the web on behalf of various web-based systems and services. Web robots are mostly used by search engines as a resource sighting and reclamation tools, which performs a vital role of maintaining data repositories state-of-the-art by powering the swift discovery of resources on the Internet. To sustain with the huge volumes of time-sensitive information, they must perform comprehensive searches, tender focused functionality and frequent visits to servers. These prospects have led to a spectacular augmentation in the number and types of robots, and their ferocity in visiting servers [1] .
Robots can be classified on the basis of their prime functionality. For example Indexers (or search engine crawlers) seek to harvest as much web content as possible on a regular basis, in order to build and maintain large search indexes. Analyzers (or shopping bots) crawl the web to compare prices and products sold by different e-Commerce sites. Experimental (focused crawlers) seek and acquire web-pages belonging to pre-specified thematic areas. Harvesters (email harvesters) collect email addresses on behalf of email marketing companies or spammers. Verifier (site-specific crawlers) performs various website maintenance chores, such as mirroring web sites or discovering their broken links. RSS crawler use to retrieve information from RSS feeds of a web site or a blog. Scrapers used to automatically create copies of web sites for malicious purposes [2] . Since their inception (First web robots were introduced in 1993) they are increasing exponentially. Because they are very simple to create and they offer great job by circumvent collection of information.
While many of the robots are legitimate and do serve a significant role to find relevant content on the web, but there are robots which do not proceed to a noteworthy reason. There are some instances where role of web robots are not defensible because it may harm to others by any extent and the several reasons are as follows: first the amount of traffic caused by crawlers may drain both the computation and communication resources of a server. Second many e-commerce web sites may not wish to serve incoming HTTP requests from unauthorized web crawlers to maintain business secrecy with competitor. Third commercial web portals perform analysis of browsing behavior of their customers and visitors and understand about their geographic, demographic trends but results are highly inflated due to presence of web robots traffic. Fourth pay-per-click advertising can be seriously harmed by deceptive behavior of web robots which involves among other things the unwilling or malicious repetitive “clicking” on advertisement links by Web robots [1] [3] . Hence it is extremely enviable to recognize visits by web robots and discriminate it from human users.
This paper is organized as follows: in Section 2 the previous work on web robot detection is discussed. In Section 3, outline of the brief description of methodology adopted for this work is presented. In Section 4, we describe the experimental design and. In Section 5, experiments are performed and experimental results were discussed. In Section 6 the paper has concluded with proposed future work.
2. Related Work
A substantial amount of literature has been published on identification of web robots traffic from web server access logs. In [4] author presents a comprehensive survey of web robots detection techniques, these techniques are broadly classified in to two category offline and real time. Real time web robot detection techniques do not operate over web server access logs and beyond the scope of this discussion. Offline web robot detection techniques works on web server logs and further classified in to syntactic log analysis, traffic pattern analysis and analytical learning. Syntactic log analysis is very simple and mostly relies on parsing of unequivocally documented information in web server logs but it can only detect already known robots. In traffic pattern analysis underlying assumption is that web robots navigational behavior is inherently different from human users and web robots are detected on this expected line rather than the knowledge of their name and origin.
Analytical learning techniques are considered more robust to handle camouflage and evasive behavior of robots as compare to others because it rely on learning features of robot traffic on the server. In [1] author use navigational behavioral patterns of web robots and humans to derive different features from each session and a decision tree (C4.5) to classify sessions based on a feature vector of their characteristics. In their study, they were able classify web robots with 90% accuracy after examining at least 4 requests within any given session. In [5] Stassopoulou et al. use a probabilistic learning based Bayesian network to identify Web robots by using number of features to achieve an 85% to 91.4% classification accuracy amongst a variety of datasets. In [6] Bomhardt et al. use a neural network model and a feature vector of session characteristics to detect web robots and compare results with [1] by using the many overlapping features. In [7] Lu et al. consider a hidden Markov model to distinguish robot and human sessions based on request arrival patterns and claims detection rate of 97.6%. Apart from the above analytical learning methods of robot detection other example works are as follows. In [8] Guo et al. proposed two detection algorithms that consider the volume and rate of resource requests to a Web server. In [9] Park et al. use a human activity detection approach of identifying web robots and web browsers by getting the evidence of mouse movement or keyboard typing from the client. All above mentioned major contributions in this field are suffer from poor session labeling and benefits of ensemble learning or agglomerative techniques. In the view of above, in this work we well addressed these two short comings of these methods.
3. Methodology
In Figure 1 we outline the proposed methodology to carry out the experiments. In following sections we briefly describe important work to be performed in different steps.
3.1. Web Server Access Logs
A Web server access log store the detailed information of each request made from user’s web browsers to the web server in a chronological order [10] . An example of classic web server log entries is given as follows and brief description in Table 1.

3.2. Session Identification
Any user can visit the particular website many times during a specific time period. Session identification aims at dividing the multi visiting user sessions into single ones. But, due to inherent constraints of the HTTP protocol (i.e. HTTP is stateless and connectionless protocol), these records are incomplete. We cannot assign distinctively all the requests contained by web server logs to the entity that has performed them. So discovering the user sessions from web server logs is a multifaceted and tricky task. Our log analyzer uses session-duration heuristic
![]()
Table 1. Brief description of web log entry headers.
*These fields only appear in the extended log file (ELF).
in conjunction with same user agent in which total session duration may not exceed a threshold θ and described by the same user agent string. Given t0, the timestamp for the first request in a constructed session S, the request with a timestamp t is assigned to S, if t − t0 ≤ θ. This heuristics varies from 25.5 minutes to 24 hours while 30 minutes is the mostly used default timeout for session duration [11] [12] .
3.3. Feature Extraction
In this step our log analyzer will extract the values of different features from identified sessions. These features are based on assumption that browsing behavior of web robots is different from human users and very useful in distinguishing between human users and web robots. All these features are adopted from [1] and describe Table 2.
3.4. Session Labeling
After extraction and selection of highly relevant features our log analyzer labels the all web serve log sessions in to two classes’ i.e. Human visitor sessions or web robot sessions. For robust session labeling we adopt a multifold approach in which first step we applied well known heuristics based session labeling algorithm of [1] but this will lead to poor session labeling. So in second step our log analyzer uses the database of IP addresses and user agent fields of well known bots [13] . If the web serve log session’s IP addresses or user agent is matches with IP or user agent of well known crawlers then session is labeled as web robot sessions.
3.5. Ensemble Based Methods
Ensemble is a combination of multiple classifiers so as to improve the generalization ability and increase the prediction accuracy [14] . The most popular combining techniques are boosting, bagging and voting. In bagging, each model in the ensemble votes with equal weight. In order to promote model variance, bagging trains each model in the ensemble using a randomly drawn subset of the training set [15] . Whereas, in boosting, each classifier is dependent on the previous one, and focuses on the previous one’s errors. Examples that are misclassified in previous classifiers are chosen more often or weighted more heavily [16] -[18] . Voting is a combining strategy of classifiers. Majority Voting and Weighted Majority Voting are more popular methods of Voting [19] [20] .
4. Experimental Design
In the previous section we have explained the methodology followed for these experiments. In running the experiments, we used the open source implementation of machine learning algorithms [21] . We used bagging [15] , boosting [17] , and voting ensemble [20] algorithms as implemented in [21] with default parameters. Bagging
![]()
Table 2. Brief description of extracted features from web server logs.
and boosting are implemented with C4.5 classifier (implemented as J48) in [21] . The base classifiers used for voting are C4.5 [22] , random forests [16] and Naive Bayes [22] which are popular in web robot detection [1] [5] . The combination rule of vote is majority voting. The data sets described below in Section 4.1 is used to test the performance of various ensemble methods. Each classifier is first trained on the training dataset, and then tested on another supplementary dataset. In the testing phase, the classification results generated by the trained classifiers are compared against the test-data’s respective session labels as they have originally been derived by the log analyzer
4.1. Dataset Description
Brief descriptions of data sets are used for this study are present in Table 3.
4.2. Performance Evaluation
The effectiveness of the classifier can be evaluated using different performance parameters. If TP and TN are total number of correctly identified true positive samples and true negative samples respectively, and FP and FN are total number of correctly identified false positive samples and false negative samples respectively, In a two-class problem (web robots, humans) the confusion matrix (shown in Table 4) records the results of correctly and incorrectly recognized examples of each class. In this study classification of user sessions as web robot
![]()
Table 4. Confusion or contingency matrix.
sessions is considered as positive class and human sessions as negative class. Given a classifier and a session, there are four possible outcomes. If the session is robot session and it is classified as robot session, it is counted as a true positive (TP); if it is classified as human session, it is counted as a false negative (FN). If the session is human session and it is classified as human session, it is counted as a true negative (TN); if it is classified as robot session, it is counted as a false positive (FP) [23] . So the contingency matrix will convert as follows.
This matrix forms the basis for many classifier evaluation measures but it is evident from Table 3 that robot data set is highly skewed towards one class. Due to this class imbalance problem the performance of the classifier simply measured by accuracy can be misleading. Therefore to test the effectiveness of ensemble classifiers we adopted recall, precision and f1-measures, which is harmonic mean of recall and precision to give equal importance to both and used to panelize a classifier which gives high recall but scarifies precision and vice-versa [24] . The equations are given in (1) to (3).
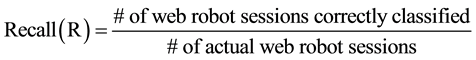 (1)
(1)
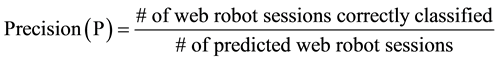 (2)
(2)
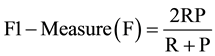 (3)
(3)
5. Experimental Results
The objective for this experiment was twofold first to test the effectiveness ensemble leaner’s in robot session identification with comparison of simple learners. Second to evaluate whether session length can improve the accuracy of web robot detection. We present and discuss the results of our two experiments in following sections.
5.1. Experiment-I
Here we present the results derived from first experiment. The comparisons of the recall, precision and F1 scores of Ensemble learners (boosting, bagging, and voting) with simple classifiers are shown in Figure 2 & Figure 3, for human sessions and web robots respectively. It is evident from the presented graphs that Ensemble learners produced improved value of recall, precision and F1 scores, as compared to simple classifiers especially with Naïve Bayes. Despite our main objective being only to web robot session identification but we evaluated preci- sion, recall and F1-measure for both majority and minority class as human sessions and web robot sessions respectively just to see the impact of majority class on different measures. As our data set is dominated by human sessions (majority class) (Figure 2) has perfect recall (100%) but lower precision (as expected) and F1 score yields the value closer to the smaller of two. The robot sessions represent the minority class in our data set (Figure 3) so precision is very high as compare to recall and F1 score is closer to recall. Figure 4 shows the time taken by different classifier models. Simple learners take significantly small time as compared to ensemble learners but at the cost of performance. But decision tree based classifiers (C4.5) has acceptable time as well as performance.
![]()
Figure 2. Comparison of measures simple vs ensemble.
![]()
Figure 3. Comparison of measures simple vs ensemble.
![]()
Figure 4. Comparison of model building time for classifiers.
5.2. Experiment-II
In this experiment we present the empirical evaluation on effectiveness of session length on classifiers perfor- mance using dataset with session length equal to or greater than (3, 4, 5, 6, and 7). The comparisons of the recall, precision and F1measure for the dataset with varying session length and different learners (both ensemble and simple) are shown in Figures 5-7, respectively. It is evident from the presented graphs that the increasing session length improves, the recall and precision and F1 measure, for all most all classifiers, except for Naïve Bays. Ensemle learners show slightly higher performance as compare to simple classifiers (same as in experiment 1) over varying length data sets. Among ensemble learners bagging performance is consistent and almost linear with data sets of increasing session length.
The results presented in the previous sections show that ensemble classifiers (boosting, bagging, and voting) achieve fairly high recall, precision and F1 measure in both experiments. Moreover, the precision for the web robots sessions (minority class) with ensemble classifiers are more than 80% in first experiment and 98% in
![]()
Figure 5. Precision-simple vs ensemble classifiers.
![]()
Figure 6. Recall-simple vs ensemble classifiers.
![]()
Figure 7. F1-measure-simple vs ensemble classifiers.
second Experiment. As a matter of fact, in second experiment, the F1 measure for all the algorithms which are used here are higher than the F1 measure for the same algorithms in first experiment.
6. Conclusion and Future Work
In this paper we presented the application of ensemble classifiers (boosting, bagging, and voting), for identification of web robot sessions from Web-server access logs. We evaluated the performance of these ensemble learners by using recall, precision and F1measue because these measures are well suited for this domain due to the high degree of class imbalance in the problem. The precision for the web robots sessions (minority class) with ensemble classifiers are more than 80% in first experiment and 98% in second experiment. The F1 measures for all the algorithms which are used in second experiment are higher than the F1 measure for the same algorithms in first experiment. We also presented that the increasing session length improves, the recall and precision and F1 measure, for all most all classifiers, but for Ensemble learners shows slightly higher performance compared to simple classifiers over varying length data sets. These results provide a promising direction for future work. In future we will address the issue of class imbalance with different data sampling techniques and evaluate the effect of various feature ranking methods to enhance the efficiency of automatic web robot detection.