Deep Cutting Plane Inequalities for Stochastic Non-Preemptive Single Machine Scheduling Problem ()
1. Introduction
The problem of scheduling a single machine to minimize the total weighted completion time is one of most well-studied problems in the area of scheduling theory in [1] [2] . The textbook by Leung [3] provided excellence coverage of most advantage topic in scheduling problem. In this paper, we will concentrate on the situation that the period of length of each job is uncertain; additionally, only a set of possible period of length scenarios are predictable. Traditional, two classic approaches are used to manage this problem: Stochastic Programming and Robust Optimization. The Stochastic Programming approach optimizes the expected value of total weighted completion time over all scenarios. However, since the accurate probability of each scenario usually is difficult to achieve [4] [5] , the Worst Case Scenario Analysis in Robust Optimization should be a better choice to manage this problem [6] .
Our objective is to optimize the cost of the total weighted completion time in the Worst Case scenarios; the historical development of this question is shown in [7] . This paper is organized in the fallowing way: in Section 1, we will build a model for this single machine scheduling problem; in Section 2, we will present an inequalities algorithm which is the corporation with the main idea of paper [8] [9] , and is also an open question of Zhao’s paper [10] ; in Section 3, we will deeply explain the worst case scenario analysis and provide numerical example. In the Section 4, we run the computational test and display the methodology of efficient cutting inequalities selection for this model; finally, our extensive computational results are reported to demonstrate the efficiency and effectiveness of the proposed solution procedures.
The most common assumptions for non-preemptive single machine scheduling problem are shown in the following section. A set of n jobs are required to be executed in a single machine, and each job demands a period of processing length L. The machine can only execute one job at a time.
Variable Definition:
・ 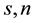 are positive integers.
are positive integers.
・ 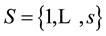 the set of scenarios.
the set of scenarios.
・ 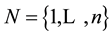 the set of jobs required to be executed.
the set of jobs required to be executed.
・ 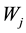 = the cost per unit of job j in the system.
= the cost per unit of job j in the system.
・ 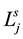 = the period of processing length of job j in scenario s.
= the period of processing length of job j in scenario s.
・ 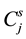 = the completion time of job j in scenario s.
= the completion time of job j in scenario s.
・ 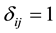 means the jobs i precedes job j in the schedule, and
means the jobs i precedes job j in the schedule, and 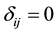 otherwise.
otherwise.
We consider the scheduling problem in the single machine environment without preemptive jobs. The purpose is to minimize the expected total weighted completion time over all scenarios. The stochastic model is shown in following.
 (1)
(1)
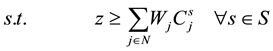 (2)
(2)
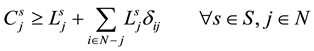 (3)
(3)
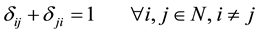 (4)
(4)
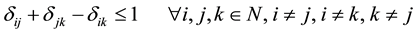 (5)
(5)
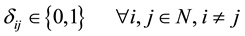 (6)
(6)
where
・ Constraint (1) ensures that the optimal value is the minimum total weighted completion time in worst case scenarios;
・ Constraint (2) means the completion time of job j in scenario s should be greater or equal than the processing length of job j in scenario s plus the total completion time of the jobs which are executed to start before job i in scenario s. It ensures that no job is scheduled to start while another job is being executed;
・ Constraint (3) ensures that a job can be only executed once in the system;
・ Constraint (4) enforce 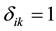 when
when 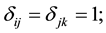
・ Constraint (5) declares that ![]() is a binary number.
is a binary number.
The model is an NP-hard problem as shown in [11] . Although time-indexed linear programming formulations have received a great attention in solving single machine scheduling problem, see [12] , the NP-hard scheduling problem is one of the most difficult questions. One possible solution is to generate cutting plane inequalities, as shown in [9] [13] [14] , for machine scheduling problem. In the next section, we will develop a large set of inequalities that valid for this model.
2. A Set of Cutting Plane Inequalities for L
In this section, I will introduce a large set of inequalities which are valid for L, and a sufficient condition that is necessary to estimate those inequalities. In order to find those cutting inequalities, we divide the set of jobs n into three parts: {x}, I and![]() , where x is an individual job, I is a nonempty subset of N. Let p be a permutation of I, and
, where x is an individual job, I is a nonempty subset of N. Let p be a permutation of I, and![]() . Suppose that
. Suppose that![]() . If
. If
![]() (7)
(7)
then
![]() (8)
(8)
is valid for L where
![]() (9)
(9)
Proof. We assume that![]() . Let C be a feasible schedule, and
. Let C be a feasible schedule, and ![]() be
be
the minimum value of ![]() over all C. Our purpose is to find
over all C. Our purpose is to find![]() . Three steps are required in order to reach the goal:
. Three steps are required in order to reach the goal:
a) Determine that any jobs in ![]() should be scheduled to start after all jobs in
should be scheduled to start after all jobs in ![]() in
in![]() .
.
b) Determine that ![]() is unchanged or holding one condition if we switch the scheduling order of job x and any job in I.
is unchanged or holding one condition if we switch the scheduling order of job x and any job in I.
c) Determine that ![]() is unchanged or holding the same condition as in b) if we switch the order of any two jobs in I.
is unchanged or holding the same condition as in b) if we switch the order of any two jobs in I.
If all three steps are satisfied, the schedule of all jobs in ![]() is settled and we get
is settled and we get![]() . I will show how each step works in the following:
. I will show how each step works in the following:
[Step 1] If any job in ![]() is scheduled to start before all jobs in
is scheduled to start before all jobs in![]() ,
, ![]() will increase because it will rise the value of
will increase because it will rise the value of ![]() or
or![]() . Therefore, it is reasonable that jobs in
. Therefore, it is reasonable that jobs in ![]() should be scheduled to start after all jobs in
should be scheduled to start after all jobs in ![]() in
in![]() . Also, the schedule of all jobs in
. Also, the schedule of all jobs in ![]() should be tight in all scenarios for the same reason.
should be tight in all scenarios for the same reason.
[Step 2] Assume that job x follows job ![]() in schedule immediately, where
in schedule immediately, where![]() . Let
. Let ![]() be the completion time resulting from switching the order of job x and
be the completion time resulting from switching the order of job x and ![]() while keeping the same completion time for all other jobs, we can get:
while keeping the same completion time for all other jobs, we can get:
![]()
Then,
![]()
The same result holds if ![]() follows x immediately in C, so we can conclude that it makes no difference when we switch the order of job x and any job in I. on the other hand, it indicates
follows x immediately in C, so we can conclude that it makes no difference when we switch the order of job x and any job in I. on the other hand, it indicates ![]() is the same when job x is scheduled to start before all jobs in I, after any one job in I, after any two jobs in I, ×××, fter all jobs in I. In addition to that, in Step 1, we known that all jobs in
is the same when job x is scheduled to start before all jobs in I, after any one job in I, after any two jobs in I, ×××, fter all jobs in I. In addition to that, in Step 1, we known that all jobs in ![]() should be scheduled to start after all jobs in
should be scheduled to start after all jobs in![]() , thus we can conclude that all jobs are scheduled in the order:{x}, all jobs in I, and jobs in
, thus we can conclude that all jobs are scheduled in the order:{x}, all jobs in I, and jobs in![]() .
.
[Step 3] Suppose that job ![]() is scheduled to start after job
is scheduled to start after job ![]() in C, where
in C, where ![]() and
and![]() . Let
. Let ![]() be the completion time resulting from switching the order of
be the completion time resulting from switching the order of ![]() and
and![]() , while keeping the same completion for all other jobs. We have:
, while keeping the same completion for all other jobs. We have:
![]()
Then,
![]()
Therefore, ![]() if
if![]() . It proved that, with this condition, the jobs in I
. It proved that, with this condition, the jobs in I
should be scheduled in order ![]() in
in![]() .
.
In a sum of step 1, 2 and 3, we can conclude that the minimum value of Q(C) can be achieved if the jobs are settled in the order:![]() , and jobs in
, and jobs in ![]() with condition (7). We can write the inequality as
with condition (7). We can write the inequality as
![]()
Specific Cases. Instead of adding all inequalities to the model, we focus on three special cases which can be generated efficiently.
First, assume that![]() , and then we found that condition (7) has always held. Thus, (8) becomes
, and then we found that condition (7) has always held. Thus, (8) becomes
![]() (10)
(10)
The numbers of inequalities are![]() .
.
Second, suppose that ![]() and
and![]() , so the condition equivalent to
, so the condition equivalent to
![]() (11)
(11)
with![]() . Suppose we sort
. Suppose we sort ![]() in a non-decreasing order, then we have
in a non-decreasing order, then we have
![]() (12)
(12)
the inequality becomes to
![]() (13)
(13)
In total, we can generate
![]()
inequalities.
Third, suppose there are N jobs and N scenarios, ![]() and
and![]() , then the condition can be rewritten as
, then the condition can be rewritten as
![]() (14)
(14)
Then the inequality becomes
![]() (15)
(15)
We can totally generate ![]() inequalities in this case.
inequalities in this case.
Example. Let![]() , the following inequalities are valid for this model:
, the following inequalities are valid for this model:
![]() (16)
(16)
![]() (17)
(17)
![]() (18)
(18)
In inequality (16), ![]() and
and![]() . In inequality (17),
. In inequality (17), ![]() and
and![]() . In inequality (18),
. In inequality (18), ![]() and
and![]() . Clearly, (16) is an example of special case one, and (17); (18) are examples of special case two.
. Clearly, (16) is an example of special case one, and (17); (18) are examples of special case two.
3. Worst-Case Scenario Analyses
In stochastic programming [4] , it is assumed that we have recognized the probability distribution of the data set, and the goal is to minimize the expected value over all scenarios. On the other hand, worst case scenario analysis can be considered as another method to solve the stochastic model, its goal is to find a solution that minimize the cost in worst case scenario [6] . Worst-case design is not intended to necessarily replace expected value optimization when the underlying uncertainty is stochastic. However, wise decision making requires the justification of policies based on expected value optimization in view of the worst-case scenario. Optimality does not depend on any single scenario but on all the scenarios under consideration. Worst-case optimal decisions provide guaranteed optimal performance for systems operating within the specified scenario range indicating the uncertainty. Here is a simple example to give us the real solution of worst case scenario method.
Example. We randomly generated a data set including 5 jobs and 7 scenarios in the Table 1, and assume all the coefficients of completion time be 1, so how to scheduling this single machine scheduling problem in worst case scenario model?
After solving this problem, we got the following result: the optimal solution is 783.1717, and the scheduling order is![]() . Additionally, since our objective function is to minimize the cost in worst case scenario, the relationship of optimal cost between worst case scenario and each single scenario should be interesting. Thus, we calculated the minimum cost and the optimal order across each scenario separately, and then we can get the optimal cost of other scenarios by this order. For instance, the optimal order for scenario 1 is
. Additionally, since our objective function is to minimize the cost in worst case scenario, the relationship of optimal cost between worst case scenario and each single scenario should be interesting. Thus, we calculated the minimum cost and the optimal order across each scenario separately, and then we can get the optimal cost of other scenarios by this order. For instance, the optimal order for scenario 1 is ![]() and optimal value is 478.28, so the cost will be 713.55 in scenario 2 and 723.06 in scenario 3 if we use this order. The result is displayed in Table 2.
and optimal value is 478.28, so the cost will be 713.55 in scenario 2 and 723.06 in scenario 3 if we use this order. The result is displayed in Table 2.
![]()
Table 2. Table of worst case scenario analysis.
To be surprised, the optimal order in worst case scenario model is following none of those scenarios. Also, the optimal cost in worst case scenario model is less than the largest cost in each scenario. To explain more specifically, if we choose to operate the machine by the optimal order of anyone one of scenario, the cost in worst situation is larger than the cost made from operating the machine by the optimal order from worst case scenario model.
4. Computational Results
In this section, we will show all the results from our computational test. Since we have already proved that our inequalities are working for this single machine scheduling problem, in order to test the efficiency of our inequities, we compare the computational time from solving the original model without any inequalities added, with all inequalities and with limited number of inequalities. We manage the model in following procedure:
![]()
Our computational test indicated that adding all inequalities would increase computational time because of the time to generate those inequalities. In fact, many of those inequalities actually cut nothing in feasible region. In order to save computational time, we should select the most valuable inequalities to the model instead of adding all the inequalities.
It is interesting that the slack values of some inequalities are zero in the integer model. It is a message that those inequalities go through the optimal point. On the other side, it means that the inequalities we generate are efficient. Thus, our inequalities are helpful to reduce the computational time if we add the right equalities. The idea is that we add top n equalities with smallest slack value selecting from the case one and case two. In the test, we found that the slack value of inequalities from case two was larger than the slack value in case one.
Thus, the inequalities we add in the model are the top N smallest slack value inequalities from case one. We randomly generated 45 examples of the model with size range from n = 50 and s = 5 to n = 110 and s = 10. The number of variables and constraints, totally, ranged between 2710 variables and 120,305 constraints to 13,091 variables to 1,308,020 constraints. Note that most of constraints are the triangle constraints; hence it will be better to take the possible advantage from selecting the essential triangle constraints rather than adding all of them in the formulation.
The coefficients of decision variable in objective function, ![]() were randomly generated from a continuous uniform distribution on [0, 50], and the length of processing time was drawn from a continuous uniform distribution on [0, 100]. Totally, we generated M scenarios in data set. We used a computer that contained a 2.20 GHz AMD Turion X2 Dual Core processor and 4 GB RAM, and we run the model in CPLEX 12.2 in default setting, except that eliminated the cover cut, Gomory mixed-integer cut and mixed integer rounding cut genera- tion. We compared the results from CPLEX with and without our inequalities added to the model. The gap between the LP relaxation and optimal integer solution is very small in each test, ranging from 0.0015% to 0.005%.
were randomly generated from a continuous uniform distribution on [0, 50], and the length of processing time was drawn from a continuous uniform distribution on [0, 100]. Totally, we generated M scenarios in data set. We used a computer that contained a 2.20 GHz AMD Turion X2 Dual Core processor and 4 GB RAM, and we run the model in CPLEX 12.2 in default setting, except that eliminated the cover cut, Gomory mixed-integer cut and mixed integer rounding cut genera- tion. We compared the results from CPLEX with and without our inequalities added to the model. The gap between the LP relaxation and optimal integer solution is very small in each test, ranging from 0.0015% to 0.005%.
We summarized the computational results in Table 3 where the column “Reduction” indicated the reduction in percentage of the integer model without cut.
Computational time is decreased for 85% of tests with our equalities added. On average, the reduction is about 28.6%.