The Research of Event Detection and Characterization Technology of Ticket Gate in the Urban Rapid Rail Transit ()
1. Introduction
The automatic fare collection (AFC) system has received a great deal of attention from the industrial and scientific communities over the past several decades owing to its wide range of applications in preventing stealing a ride, access control, law enforcement, etc. Obviously, it is a significant value study in the intelligent recognition system. Especially in the urban rapid rail transit, the fare evasion phenomenon is coming to rampant. The main difficulty of recognition of these events is that there are many ways for passengers to pass through the walkway of the ticket gate. For example, people can walk through the walkway without anything or pulling a suitcase; two walking passengers also can pass through the walkway closely to each other for a fare evasion. However, as far as I know, few researches have been reported on this problem. Since 1970s, Samsung [1] , Gun Nebo [2] , Nippon Signal [3] , and Omron [4] have successively set up their AFC systems. However, intelligence recognition system was hardly found in their product, or merely equipped with few simple recognition functions. Quri [5] presented a recognition algorithm based on event driven. In that paper, the method combines event recognition technology, human gait recognition technology and human body contour recognition technology. But this method has somewhat difficulty in dealing with the transit without a big gap between two walking passengers. The relatively low recognition rate (85%) is also far from the requirement of market. In order to improve the recognition rate, a novel method is proposed.
This paper focuses mainly on the issue of a robust recognition to several events of ticket gate in the urban rapid rail transit. According to the actual conditions, as shown in Figure 1, three types of events are discussed.
The overall process of recognition system can be viewed as a pipeline as shown in Figure 2. A single-chip microcomputer is used to collect signals sent by infrared sensors and communicate with an upper computer. During motion objects passing through the walkway, the measurement data from infrared sensors would be combined into a vector according to time order, as shown in Figure 5. The vector as the feature descriptor makes the characteristics of events more manifest. All feature descriptors of different events are used to train the
![]()
Figure 2. The overall process of recognition system.
recognition model. Finally, these recognition models are evaluated on the task of events recognition of ticket gate. Various methods [6] -[8] are used to train the recognition model.
Tripod turnstile gate, slide-stile gate and flap-stile gate are the three main types of ticket gates in the market. For slide-stile gate is often used as the preferred ticket gate, in this paper, it will be selected as the main research object. The rest of the paper is organized as follows. Section 2 introduces a topological graph of the sensors- array scheme. Section 3 presents a data preprocessing process. Section 4 is the design of recognition. Section 5 shows experimental results, and Section 6 is a conclusion.
2. Topological Graph of Sensors-Array
Eight diffuse reflectance infrared sensors are used to detect the movement sequence of the motion objects in the recognition system. All of the sensors are arranged in an array which we call sensors-array. For every diffuse reflectance infrared sensor, its emitter is integrated with its receiver. When no motion objects detected by a sensor, its output value is 1 (high level signal), otherwise, its output value is 0 (low level signal).
All of the diffuse reflectance infrared sensors are situated in the walkway side of the ticket gate in this paper. As shown in Figure 3, the walkway of the ticket gate is divided into three zones, which are defined as import area, gait detection area, export area.
Import area and Export area are used for charging and installing the roller brake respectively, witches are not within the scope of this article.
Gait detection area, No. 1 to No. 8 sensors are 15 cm off the ground, which are used to detect shanks of human body. Figures 4(a)-(c) describe the movement sequences of one passenger passing through the walk gate, two consecutive passengers passing through the ticket gate without a big gap between them, and one passenger walking through the walkway pulling a suitcase got by No. 1 to No. 8 sensors respectively, which show a big difference both in data representation and data length. As a whole, the data of above event types show a good sense of distinction.
3. Data Preprocessing
In order to improve the recognition rate, it is very important to maintain the integrity of the data. During one passenger passing through the walkway, according to Figure 4, the working stage of No. 1 to No. 8 infrared sensors would be represented by a matrix which consists of n rows and 8 columns (every row describes eight sensors’ working stage at a point in certain time; every column describes a sensor’s working stage at different points in time). Then we translate the matrix into a vector which contains 8 × n elements as the input vector for the event representation, as shown in Figure 5. At last, we will unify the input vector to the same length as training vector.
4. Event Feature
In this section, machine learning is used to identify events. For a good recognition, the machine learning model must be robust and efficient. Robustness refers to insensitivity to slight difference within the same event. Efficiency refers to a high identification to different events. Although many machine learning models can be used for event identification, the challenge of identifying events is finding a robust and efficient method. In this paper, an extensive set of publicly available machine learning models, deep learning (DL), back propagation neural
![]()
Figure 3. Location of diffuse reflectance infrared sensors.
![]() (a) One person (b) Two consecutive persons (c) One person with a suitcase
(a) One person (b) Two consecutive persons (c) One person with a suitcase
Figure 4. Movement sequences of different events defined in this paper got by No. 1 to No. 8 sensors. Red color means sensor detects a motion object, blue color means sensor detects nothing. (a) Movement sequences of one passenger passing through the walk gate got by No. 1 to No. 8 sensors; (b) Movement sequences of two consecutive walking passengers passing through the walk gate without a big gap between them got by No. 1 to No. 8 sensors; (c) Movement sequences of a passenger walking through the walkway pulling a suitcase got by No. 1 to No. 8 sensors.
network (BP), support vector machine (SVM), are used to evaluate the effectiveness of solving recognition problem respectively. Feature descriptor described in the previous section is put into the learning models as the input value.
4.1. Deep Learning (DL)
Recently, deep learning (DL) has been the leading technique to learn good information representation that exhibits similar characteristics to that of the mammal brain. It has gained significant interest for building hierarchical representations from unlabeled data. A deep architecture consists of feature detector units arranged in multiple layers: lower layers detect simple features and feed into higher layers, which in turn detect more complex features. In particular, deep belief network (DBN), the most popular approach of deep learning, is a multilayer generative model in which each layer encodes statistical dependencies among the units in the layer below, and it
![]()
Figure 5. Process of data preprocessing.
can be trained to maximize (approximately) the likelihood of its training data. A great deal of deep belief network (DBN) models have been proposed so far [6] [9] - [11] . Particularly, the model proposed by Hinton et al. is a breakthrough for training deep networks. It can be viewed as a composition of simple learning modules, each of which is a Restricted Boltzmann Machine (RBM) that contains a layer of visible units representing observable data and a layer of hidden units learned to represent features that capture higher-order correlations in the data. Today, including machine transliteration [12] , hand-written character recognition [9] [13] , object recognition [14] , various visual data analysis tasks [15] - [17] etc., DL have been successfully applied to above applications.
Restricted Boltzmann Machine (RBM) [13] [18] - [20] is a bipartite, two-layer, undirected graphical model consisting of a set of (binary or real-valued) visible units (random variables) 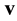 of dimension D representing observable data, and a set of binary hidden units (random variables)
of dimension D representing observable data, and a set of binary hidden units (random variables) 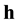 of dimension K learned to represent features that capture higher-order correlations in the observable data. Hidden units
of dimension K learned to represent features that capture higher-order correlations in the observable data. Hidden units 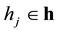 are independent of each other when conditioning on
are independent of each other when conditioning on 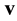 since there are no direct connections between hidden units. Similarly, the visible units
since there are no direct connections between hidden units. Similarly, the visible units 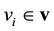 are also independent of each other when conditioning on
are also independent of each other when conditioning on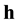 . Figure 6 illustrates the undirected graphical model of an RBM.
. Figure 6 illustrates the undirected graphical model of an RBM.
RBM is an energy-based model. We define the energy of joint distribution over the visible and hidden units by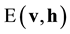 .
.
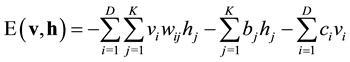 (1)
(1)
where ![]() is the weight between the visible units
is the weight between the visible units ![]() and hidden units
and hidden units![]() ,
, ![]() and
and ![]() are respectively visible and hidden units bias.
are respectively visible and hidden units bias.
![]() (2)
(2)
![]() (3)
(3)
where Z is normalized factor, also known as the partition function.
The probability that the network assigns to a visible vector ![]() (training vector), is given by summing over all possible hidden vectors:
(training vector), is given by summing over all possible hidden vectors:
![]() (4)
(4)
We can raise the probability that the network assigns to a training vector by adjusting the weights and bias to lower the energy of the training vector. The derivative of the log probability of a training vector with respect to a weight is surprisingly simple.
![]()
Figure 6. Undirected graphical model of an RBM.
![]() (5)
(5)
where the angle brackets represent expectations under the distribution specified by the subscript that follows. ![]() is the distribution of the training data, and
is the distribution of the training data, and ![]() is the equilibrium distribution defined by RBM. We can get a very simple learning rule for performing stochastic steepest ascent in the log probability of the training data:
is the equilibrium distribution defined by RBM. We can get a very simple learning rule for performing stochastic steepest ascent in the log probability of the training data:
![]() (6)
(6)
where ![]() denotes a learning rate.
denotes a learning rate.
DBN is a probabilistic generative model that composed by several layers of hidden variables, in which each layer captures high-order-correlations between the activities of hidden features in the layer below. DBN is mainly made up by Restricted Boltzmann Machine (RBM) and two adjacent layers of DBN including a RBM, as shown in Figure 7; the DBN is composed by three hidden layers![]() ,
, ![]() and
and![]() , v is the input layer.
, v is the input layer.
A marked feature of DBN is that to learn a deep hierarchical model we should repeat a greedy layer by layer unsupervised training for several times. In 2006, a fast, unsupervised learning algorithm for these deep networks is proposed by Hinton et al. [9] .
4.2. Back Propagation Neural Network (BP)
BP network is basically a gradient decent algorithm designed to minimize the error function in the weights space. During training of the neural network, weights are adjusted to decrease the total error. In principle, it has been proved that any continuous function can be uniformly approximated by BP network model with one or more hidden layer. However, it is not easy to choose the appropriate number of hidden layers because currently there is no definite rule to determine it. Using too many hidden layers maybe lead to local optimum and increase training time. But using too few hidden layers impairs the neural network and prevents the correctly mapping of inputs and outputs. In the next section, we will test the performance of BP with different numbers of hidden layers.
4.3. Support Vector Machine (SVM)
Support vector machine (SVM) is a technique developed by Vapnik (1999) [7] , which is used to train the classifiers according to structural risk minimizations concept. SVM has been used in various classification problems and pattern recognition field since 90s.
Data can be classified into two classes (positive and negative) with SVM. Assuming a group of points that belong to these two classes, SVM description can be referred as follows: a SVM establishes the hyper plane which allocates the majority of points of the same class in the same side, which maximizes the distance between the two classes to the hyper plane. Define the optimal separating hyper plane as the distance between one class and a hyper plane which is the small distance between the hyper plane and the other points of the same class. The hyper plane created by SVM contains a subset of points of these two classes, which we call support vectors.
Assuming training set![]() , where
, where ![]() is an N-dimensional input data and
is an N-dimensional input data and ![]() is the required classification.
is the required classification.
The goal is to estimate a function with the training set that classifies the pairs ![]() which haven’t been correctly used yet. The optimal hyperplane is defined by:
which haven’t been correctly used yet. The optimal hyperplane is defined by:
![]() (7)
(7)
![]()
Figure 7. Deep belief network with three hidden layers h1, h2 and h3.
where ![]() is the weight vector and
is the weight vector and ![]() is the bias. A vector
is the bias. A vector ![]() that labeled as the same class
that labeled as the same class ![]() must satisfy the follow equation:
must satisfy the follow equation:
![]() (8)
(8)
where ![]() is normal to the hyperplane. The Euclidian distance between these points over the separating margin and the hyperplane is determined by Equation (9).
is normal to the hyperplane. The Euclidian distance between these points over the separating margin and the hyperplane is determined by Equation (9).
![]() (9)
(9)
Thus, for maximizing the separating hyperplane, we should minimize![]() . The following equation can be established with Lagrange multipliers theory.
. The following equation can be established with Lagrange multipliers theory.
![]() (10)
(10)
where ![]() is the Lagrange multiplier. The optimization problem solution is obtained through minimization of
is the Lagrange multiplier. The optimization problem solution is obtained through minimization of![]() .
.
For nonlinear decision surfaces, the input data generated by machines in a higher dimension space tends to decrease computational efforts of the support machines. By introducing variables that enlarge the margin by relaxing the linear SVM, to allow a few misclassification errors in the margin, and penalize these errors through penalty parameter ![]() in Equation (12), the not linearly separated problem can be solved. These changes allow that the Equation (8) can be violated, or:
in Equation (12), the not linearly separated problem can be solved. These changes allow that the Equation (8) can be violated, or:
![]() (11)
(11)
where ![]() is non-negative variables associated to each training vector. The cost function can be given by Equation (12).
is non-negative variables associated to each training vector. The cost function can be given by Equation (12).
![]() (12)
(12)
where ![]() is the training parameter that decides the balance between the training error and model complexity, which is known by regulating constant.
is the training parameter that decides the balance between the training error and model complexity, which is known by regulating constant.
A detailed discussion of the computational aspects of SVM can be found in [21] and [22] , with many examples also can be found in [23] -[26] .
5. Experiment
We will illustrate the effectiveness of the method by presenting experiments on three events data got by sensors 1 - 8. The database used in our experiment was constructed by 150 samples (with 50 samples per class). 90 samples (with 30 samples per class) are used to train DL, BP, SVM and 60 samples (with 20 samples per class) are used to test recognition rates.
5.1. Experimental Settings
In this paper, deep learning (DL), neural networks based on error back-propagation algorithms (BP), support vector machine (SVM), are used for learning the data respectively. Events of one person with a bag or without anything walking through the ticket gate, two consecutive passengers passing through the ticket gate without a big gap between them, a passenger walking through the ticket gate pulling a suitcase are defined as event 1, event 2, and event 3. The definition of all events refers to the assembly of event 1, event 2 and event 3. The running environment of experiments is Matlab 2013a.
5.2. Results for Events Classification
To aid comparison with previous work, Table 1 summarizes the average recognition rates of the recognition system and Quri’s recognition system at a false acceptance rate of 0.1%. Note that the method gives perfect recognition results for database build in this paper: DL gives 89.2%, BP gives 92.5%, and SVM gives 90.0%. While, limited by the fixed sensors’ position, method proposed in Quri’s paper gets a relatively low recognition rate with 85.0%.
Figure 8 illustrates the recognition performance of recognition manners (DL, BP, SVM) referred in this paper. BP gives better performance than DL, SVM overall. All recognition manners got a 100% recognition rate to event of one person walking through the ticket gate. While all recognition manners got a relatively low recognition rate to event of two consecutive passengers passing through the ticket gate without any gap between them. While, BP shows a higher recognition rates both in events 3 (100%) and all events referred in this paper (92%), with recognition rates of DL and SVM 90%, 89% and 90%, 90%.
![]()
Table 1. Average recognition rates obtained with using different recognition methods on database built in this paper. 90 samples (30 samples per class) are used for training and 60 samples (20 samples per class) are used for test. Note that recognition of Quri’s methods is got with his recognition scheme and database defined in his paper.
![]()
Figure 8. Recognition performance of methods proposed.
![]()
Figure 9. Recognition error rates of BP.
In order to have an estimate of the performance of BP with different numbers of hidden layers, we test the recognition rate of BP with 1, 3, 4, 5 hidden layers. The results shown in Figure 9 are average recognition error rate of BP with 1, 3, 4, 5 hidden layers respectively. The results show that the proposed BP models with 3 hidden layers reach a relatively satisfactory recognition rates. In this paper, the BP model contains three hidden layers by default. In theory, the more hidden layer neurons are often with more high recognition accuracy. But too much of the hidden layer neurons can greatly increase the training time, at the same time, the increase of the hidden layer neurons will cause the loss of the tolerance of the network. So the numbers of neurons in 3 hidden layers are empirically selected as 500, 400, and 100 respectively in this paper.
6. Conclusions
This paper refers to the event recognition technology on the ticket gate in the urban railway traffic. We put forward a recognition manner according to the different moving sequence of various events. The main contributions are as follows: 1) We integrate the moving sequence matrix to a one-dimensional vector as the feature descriptor. Several recognition algorithms (DL, BP, and SVM) are applied to recognize the events. It has been found that BP has a higher recognition rate compared to other methods with 3 hidden layers. 2) Several events that often happened in the scene of the ticket gate could be identified effectively in this paper. Experiments proved method proposed in this paper have a higher recognition rate.
Eight sensors are used in the senor-array; the hardware of the intelligent recognition system is very simple and inexpensive. Experiments show that the method gets a satisfactory result.
Moreover, we just provide a new insight into the role of machine learning played in dealing with events recognition of ticket gate in the urban railway station. More events should be defined in the follow-up study. Also, more high recognition accuracy is required in the reality need of engineering. Feature selection or recognition system remains an interesting and important research topic in events recognition.
Acknowledgements
This paper was partially supported by the National Natural Science Foundation (61374040), the Hujiang Foundation of China (C14002), Scientific Innovation Program (13ZZ115), and Graduate Innovation Program of Shanghai (54-13-302-102).
NOTES
*Corresponding author.