Simulation Program to Determine Sample Size and Power for a Multiple Logistic Regression Model with Unspecified Covariate Distributions ()
1. Introduction
Logistic regression models have been used to determine the association between risk factors and outcomes in various fields, including medical and epidemiological research [1] [2] . However, they sometimes produce contradictory conclusions for the same hypothesis. For example, some studies have indicated that cigarette smoking enhances the risk of Barrett’s Esophagus, whereas other studies have concluded that there is no association between the two because of a lack of power [3] . The robustness of such inferences is dependent on the relationship between sample size and power [4] . It is clearly important to calculate the sample size and estimate the power of observational studies, as well as randomized control studies, while accounting for the effects of other covariates.
Theoretical formulas, criteria, and software applications have been developed to enable the accurate determination of sample size and statistical power in a binary logistic regression model [5] - [11] . However, these tend to consider only specific, well-known probability distributions, even though it is clear that the power differs according to the shape of the covariate distribution. In practice, many covariates are inherently continuous, and their distributions take a variety of shapes (e.g., being heavily skewed to the left or right). Another problem is that the size of the effect can sometimes differ between outcomes and covariate. For example, J-shaped relationships are sometimes found in medical and epidemiological studies and an inverse relationship between diastolic pressure and adverse cardiac ischemic events (i.e., the lower the diastolic pressure the greater the risk of coronary heart disease and adverse outcomes) has been observed in numerous studies [12] . The distribution shape and effect size of covariates must be carefully considered. Therefore we have developed a software program that uses Monte Carlo simulations to estimate the exact power of a logistic regression model corresponding to the actual data structure. This program has numerous advantages. It can handle any distribution shape and effect size and enables the application of various statistical methods, logistic regression, and other simulations such as Bayesian inference with some modifications. In this paper, we report the application of our simulation program to real data obtained from a study on the influence of smoking on 90-day outcomes after acute atherothrombotic stroke in 292 Japanese men [13] .
2. Theoretical Background
2.1. Standard Binary Linear Logistic Regression Model
We consider a case-control study in which the binary response variable y denotes each patient’s disease status (y = 1 for cases and y = 0 for controls). For each subject, we have a set of p covariates X1, X2 , 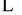 , Xp. Let the conditional probability that an outcome is present be denoted by. The logit of the multiple logistic regression model is
, Xp. Let the conditional probability that an outcome is present be denoted by. The logit of the multiple logistic regression model is
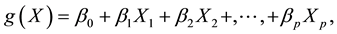
in which case the logistic regression model is
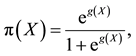
where β is an unknown parameter.
2.2. Two-Segment Logistic Regression Model for Nonlinear Association between a Logit Outcome and a Covariate
We replace the linear term associated with the covariate X1 in the standard binary logistic regression model with a two-segment function containing a change-point. The relationship between the logit outcome and X1 is different either side of this change-point. The two-segment logistic regression model shown in Figure 1 can be expressed as follows
![]()
Figure 1. Two-segment logistic regression model for non-linear association between logit outcomes and covariates.
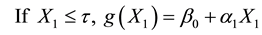
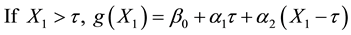
where represents the value of the change-point and; α1, α2 are the unknown regression coefficients of X1.
3. Methods
3.1. Outline of Simulation Program
Our Monte Carlo simulation program is written in the SAS/STAT/IML language; the source code is given in the appendix. The program consists of three parts: data generation, parameter estimations, and statistical power calculation. Users should modify and add to these conditions according to their specific purposes and interests. Table 1 describes the input parameters required to run the program. Users should assign suitable values, as determined by the relevant test problem. Table 2 describes some macro modules for modifying this program.
Continuous distributions are generated by specifying the mean, standard deviation, skewness, kurtosis, and correlation, or by assigning frequencies in each designated interval of a continuous variable (see Figure 2). The nonlinear relationship between the continuous covariates and the logit outcome can be specified by varying the regression coefficients on either side of a change point, as shown in Figure 1.
In the proposed program, users assign values for the proportion of events, sample size, Type I error, regression coefficients, distribution type (dichotomous, polytomous, or continuous), and distribution shape, as well as the quantile number for the categorization approach. The output of this program shows the average and standard error of each coefficient, as well as the power. A flowchart describing this program is shown in Figure 3.
The validity of the program is confirmed by comparing its results with those given by Hsieh’s program. The output of our program is almost the same as that from Hsieh’s program. For example, when the event proportion, sample size, and regression coefficient were set to 0.01, 12,580, and −0.223, respectively, our program estimated a power of 0.81, whereas Hsieh’s gave a result of 0.8. When the event proportion, sample size, and regression
![]()
Table 1. Description of input parameters.
![]()
Table 2. Description of the macro module for modifications.
![]()
Figure 2. Algorism of generating a continuous covariate which has a unique distribution.
![]()
Figure 3. Flow chart of simulation program.
coefficient were set to 0.5, 225, and 0.405, respectively, our program estimated a power of 0.89, which compares well with Hsieh’s result of 0.9 [14] .
3.2. Construction of Raw Simulation Data
3.2.1. Continuous Covariates
Non-normal or normal multivariate continuous variables are generated by specifying the mean, standard deviation, kurtosis, skewness, and correlation through a procedure in the %COEFF and %CONTINOUS SAS modules. A detailed explanation can be found in a book on SAS® for Monte Carlo Studies [15] .
3.2.2. Continuous Covariates That Are Uniquely Distributed (Figure 2)
A continuous variable is divided into l subgroups of equal intervals as shown in Figure 2. The minimum value of the original covariate is assumed to be Min and the maximum value is assumed to be Max.
The length of the interval of each subgroup is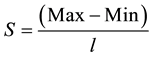 .
.
The kth subgroup ranges from ak to bk (k = 1,  , l), where k = 1 indicates the lowest subgroup and l indicates the highest. ak and bk can be expressed as
, l), where k = 1 indicates the lowest subgroup and l indicates the highest. ak and bk can be expressed as
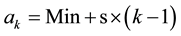
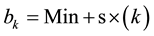
Random numbers from a uniform distribution on the interval (0, 1) are converted to a uniform distribution on the interval (ak, bk) with the equation ak + (bk ? ak) × (generated number). The kth subgroup, consisting of nk observations in the interval (ak, bk), is denoted by the variable H1.
3.2.3. Statistical Probability Distribution
If the covariate is assumed to follow a probability distribution, the RAND function can be inserted into a macro PDF module. In the example given for this program, nominal variables are generated using the SAS TABLE function.
3.2.4. Determination of Binary Outcome
The individual probability of event occurrences is calculated from the assigned parameters and generated covariates using a logistic regression model. The initial intercept value is set to zero, and then the average is calculated. The intercept is determined from 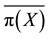 and p by the following equation:
and p by the following equation:
Intercept = 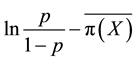
After determining the intercept, the individual probability π(Xi) (for i = 1, ![]() , n observations) is calculated by a logistic regression model. The binary outcome Y is generated from the individual π(xi) and random numbers from a uniform distribution on the interval (0, 1). If π(xi) is less than the corresponding random number, Yi = 1 (denoting that the event occurred); otherwise, Yi = 0. Finally, we have a dataset consisting of a covariate and response variable (Y). For skewed distributions, the event proportion of the generated dataset might not be the same as the input value. However, our program outputs the event proportion of this dataset. This difference can be adjusted by changing the input parameters of the event proportion.
, n observations) is calculated by a logistic regression model. The binary outcome Y is generated from the individual π(xi) and random numbers from a uniform distribution on the interval (0, 1). If π(xi) is less than the corresponding random number, Yi = 1 (denoting that the event occurred); otherwise, Yi = 0. Finally, we have a dataset consisting of a covariate and response variable (Y). For skewed distributions, the event proportion of the generated dataset might not be the same as the input value. However, our program outputs the event proportion of this dataset. This difference can be adjusted by changing the input parameters of the event proportion.
3.2.5. Estimation of Regression Coefficients and Standard Errors
We conducted a logistic regression analysis in a model including continuous and/or design variables to obtain maximum likelihood estimates of and the significance level, or p-value, for the null hypothesis with population regression coefficient β = 0.
There is a possibility of non-convergence if the data are completely or partially separated. This is because one or more parameters in the model become theoretically infinite, and it may not be possible to obtain reliable maximum likelihood estimates [16] . These instances of non-convergence must be appropriately handled. Our simulation program overcomes this problem by neglecting samples that lead to non-convergence.
3.2.6. Test Module
The test module outputs the mean of the asymptotic standard error, and the statistical power. The proportion of tests in which the p-value is less than the Type I error level is defined as the power.
4. Sample Runs
4.1. Sample Run 1
Variable H1 was set to be the National Institute of Health Stroke Scale (NIHSS, a tool used by healthcare providers to objectively quantify the impairment caused by a stroke). The minimum, maximum, and the number of subgroups were set as 1, 21, and 5, respectively. Therefore, the subgroups ranged from (1, 5), (5, 9), (9, 13), (13, 17), and (17, 21). The frequency of each subgroup was assumed to be 0.55, 0.05, 0.2, 0.15, and 0.05, respectively. The generated numbers were rounded off, and the event proportion was set to 0.2. Regression coefficient parameters (,) were taken as (0.00, 0.00), (0.06, 0.06), and (0.06, 0.15), and the change point was set to 4. H1 was set to be either continuous, divided at median or tertile points, or categorized into three groups: 1 - 4, 5 - 15, and ≥16. We executed the logistic model for these values of H1, and present the results in Table 3. When and were set to 0.06 and 0.06, the average coefficient value was correctly estimated to be 0.062. When these parameters were set to 0.06 and 0.15, the categorization using the change point produced higher coefficient values than that using the tertile points. Moreover, when and were set to 0.0 and 0.0, the power was approximately 0.05, the same as the Type I error.
4.2. Sample Run 2
We used age and systolic arterial pressure as continuous variables X1 and X2, respectively. The mean and standard deviation of X1 were 70 and 8, and the skewness and kurtosis were set to combinations of 0 and 0, −0.5 and 0.5, and −1.0 and 1.0. The regression coefficient of X1 was 0.05 under a linear relationship. The mean and standard deviation of X2 were 160 and 25, and the skewness and kurtosis were set to combinations of 0 and 0, 0.4 and 0.3, and 0.8 and 0.6. The regression coefficient of X2 was set to 0.02 as a linear relationship. The correlation between the variables was set to 0, 0.3, and 0.6. The binary variable D1 denotes smoking or non-smoking. The proportion of non-smokers and smokers was 0.5 and 0.5, and the regression coefficient was 0.83. The sample size was set to 300 and 500. We executed the logistic model for X1, X2, and D1. The results are shown in Table 4.
![]()
Table 3. Sample run 1: estimated power of the Wald test in two-segment logistic regression model with an event proportion of 0.2.
![]() (a)S, skewness; K, kurtosis.
(a)S, skewness; K, kurtosis. ![]() (b)S, skewness; K, kurtosis.
(b)S, skewness; K, kurtosis.
Table 4. (a) Sample run 2: estimated power of the Wald test for left- and right-skewed distributions with an event proportion of 0.2 and N = 300; (b) Sample run 2: estimated power of the Wald test for left- and right-skewed distributions with an event proportion of 0.2 and N = 500.
The mean, standard deviation, skewness, and kurtosis in the generated variables were almost equal to those of their input parameters. An increase in sample size leads to higher power, whereas a higher correlation produces a lower power. Our results clearly illustrate that the power will differ depending on the shape of the distribution. Negatively skewed distributions exhibit low power, whereas a positive skew results in high power. There is an inverse relationship between the logit outcome and the covariates. For example, when the skewness of X1 was changed from −0.5 to −1.0, the power decreased from 0.75 to 0.73. When the skewness of X2 was changed from 0.4 to 0.8, the power increased from 0.81 to 0.84 or 0.88 for a sample size of 300 and correlation of 0.0.
4.3. Sample Run 3: Epidemiological Studies
It is important to establish that the results observed in the above simulations hold for real data. For this purpose, we used data from a study of the influence of smoking on 90-day outcomes after acute atherothrombotic stroke in 292 Japanese men [14] . In this study, body temperature, age, NIHSS score at admission, systolic blood pressure, and smoking status were included in the logistic model. Detailed input parameter information is given in Table 5(a), and the estimated results are listed in Table 5(b). The event proportion of this real study was 0.2. We obtained an event proportion of 0.206 in the generated dataset by setting an input value of 0.15 for the event proportion. The estimated coefficients were similar to the results of the epidemiological study. Real data analysis showed that all factors, i.e. body temperature, age, NIHSS score at admission, systolic blood pressure, and smoking status, were significantly associated with the outcome (p < 0.05), and our results also exhibited high power (minimum to maximum of 0.686 to 1.000).
(a) ![]() (b)
(b) ![]()
Table 5. (a) Assigned input parameters for sample run 3; (b) Sample run 3: estimated power of the Wald test for an epidemiological study with a sample size of 292.
Event proportion = 0.206.
5. Conclusions and Discussion
Estimating the sample size or inference of statistical power is critical. If the sample size is too low, the experiment will lack the precision needed to provide reliable answers to the questions it is investigating. If the sample size is too large, time and resources will be wasted, often for minimal gain [17] . In this study, we developed a Monte-Carlo simulation program that estimates the powers of covariates in the binary logistic regression model. Users can evaluate the relationship between sample size and covariates, in observational and power randomized studies. In this situation, our simulation results clearly indicated the relationship between statistical power and covariate distribution shape, as shown by the data in Table 4. Right- and left-skewed distributions exhibit different powers. This phenomenon has clarified that the shape of a distribution affects its statistical power [18] [19] . The advantage of using a theoretical equation to estimate the power is that it is quick and easy to implement using existing software. For this reason, power equations are used to inform most studies. However, in practical analysis, we must often compute the power with a relatively complex distribution.
Our program is flexible enough to accommodate any number or type (continuous or discrete) of covariate and categorization, continuous distribution shapes and correlations, and the association level between logit outcome and covariates, although some modifications may be necessary. This program can also be applied to other statistical methods, logistic regression and Bayesian inference. The SAS/STAT/IML program written for the simulations and a user manual are available upon request [20] [21] .
Acknowledgements
The authors wish to thank Dr. Motonori Hatta for helpful advice on the study.
Contribution
K.A. and N.K. were responsible for the study conception. N.K. wrote the program and drafted this manuscript. N.K., K.A., Y.O., H.K., and Y.H. made revisions to the manuscript. All authors approved the final version of the manuscript.
Appendix: Simulation Program for Estimating the Statistical Power of Logistic Regression Model
%LET SEED=;
%LET ALEVEL=;
%LET PATH=;
%LET TABLE=;
%LET NITER=;
%LET SKW_KRT=%NRSTR({});
%LET LIST_VARNAME=%NRSTR();
%LET MODEL_1=%NRSTR();
%LET MODEL_2=%NRSTR();
%LET CATEGORIZATION=%NRSTR();
%LET CATEGORIZATION_R=%NRSTR();
%LET CONTI_MODEL=%NRSTR();
%LET CHANGE_POINT=;
%LET MAX=;
%LET MIN=;
%LET SUB_GROUP=;
%LET P=;
/*EXAMPLE*/
DATA A (TYPE=CORR);
LENGTH _TYPE_ $40;
INPUT _NAME_ $ _TYPE_$ X1 X2 ;
IF TRIM(LEFT(_TYPE_))='N'THENCALL SYMPUT('NSP', X1);
CARDS;
. MEAN 70 160
. STD 8 25
. N 300 300
X1 CORR 1 0
X2 CORR 0 1
;
RUN;
%DATASET(N_REPEAT=);
%LR(R=);
/************************%COEFF and %CONTINUOUS **************/
/*%COEFF and %CONTINUOUS generate random variables following a Multivariate /*Normal distribution with given means, standard deviations, and correlation matrix, /*and then transform each variable to the desired distributional shape with specified /*population univariate skewness and kurtosis
/*%COEFF
/*Macro COEFF calculates coefficients of the Fleishman’s power transformation
/*Equation X= A + B*C1 + C*C2^2 +D*C3^3 where A=-C
/*Parameters
/*SKW_KRT; %NRSTR({skewness1 kurtosis1, skewness2 kurtosis2,…, });
/*LIST_VARNAME; list of variable names that define the skewness and kurtosis.
/*OUT the name of the output file (name of COEFF) that has thecoefficient values (A B C) of each variable.
/********************************************************************/
%MACROCOEFF;
PROC IML;
/* COEFFICIENTS OF B, C, D FOR FLEISHMAN'S POWER TRANSFORMATION*/
SKEWKURT=&SKW_KRT;
MAXITER=25;
CONVERGE=.000001;
START FUN;
C1=COEF [1];
C2=COEF [2];
C3=COEF [3];
F= (C1**2+6*C1*C3+2*C2**2+15*C3**2-1)//
(2*C2*(C1**2+24*C1*C3 +105*C3**2+2)-SKEWNESS)//
(24*(C1*C3+C2**2*(1+C1**2+28*C1*C3)+C3**2*
(12+48*C1*C3+141*C2**2+225*C3**2))-KURTOSIS);
FINISH FUN;
START DERIV;
J= ((2*C1+6*C3) || (4*C2) || (6*C1+30*C3))//
((4*C2*(C1+12*C3)) || (2*(C1**2+24*C1*C3+105*C3**2+2))||
(4*C2*(12*C1+05*C3)))//((24*(C3+C2**2*(2*C1+28*C3)+48*C3**3))||
(48*C2*(1+C1**2+28*C1*C3+141*C3**2))||
(24*(C1+28*C1*C2**2+2*C3*(12+48*C1*C3+141*C2**2+225*C3**2)
+C3**2*(48*C1+450*C3))));
FINISH DERIV;
START NEWTON;
RUN FUN;
DO ITER = 1 TO MAXITER
WHILE (MAX(ABS(F))> CONVERGE);
RUN DERIV;
DELTA=-SOLVE(J,F);
COEF=COEF+DELTA;
RUN FUN;
END;
FINISH NEWTON;
DO;
NUM=NROW (SKEWKURT);
DO VAR = 1 TO NUM;
SKEWNESS = SKEWKURT [VAR,1];
KURTOSIS = SKEWKURT [VAR, 2];
COEF = {1.0, 0.0, 0.0};
RUN NEWTON;
COEF = COEF`;
SK_KUR= SKEWKURT [VAR,];
COMBINE=SK_KUR||COEF;
IF VAR = 1 THEN RESULT=COMBINE;
IF VAR >1 THEN RESULT=RESULT//COMBINE;
END;
END;
RESULT=RESULT`;
CREATE _COEF_ FROM RESULT [COLNAME={&LIST_VARNAME}];
APPEND FROM RESULT;
DATA _COEF;
SET _COEF_;
LENGTH _TYPE_ $40;
MARK = _N_; _TYPE_="COEFF";
FORMAT MARK;
RUN;
DATA COEFF (DROP= MARK);
SET _COEF;
IF MARK >2 THEN OUTPUT COEFF;
RUN;
%MEND COEFF;
/***********************%CONTINUOUS********************************/
/*This program generates random variables following a Multivariate Normal /*distribution with given name, standard deviation, and correlation matrix, and then /*transforms each variable to the desired distributional shape with Fleishman’s /*coefficient.
/*Parameter
/*N_Repeat; the number of iterations
/*SEED; seed of the random number generator
/*DATA the name, A, of the input file that determines the characteristics of the random /*numbers to be generated. The file specifies the mean, standard deviation, number of /*observations of each random number, and the correlation coefficients between the /*variables. It must be a TYPE=CORR file, and its structure must comply with that of /*such files. The file has _Type_=MEAN, STD, N, CORR. Its variables are _TYPE_, /*_NAME_ and the variables to be generated. The number of observations should be /*the same value. In this file, the sample size 'NSP' should be specified as a parameter, /*using IF TRIM(LEFT(_TYPE_))='N' THEN CALL SYMPUT('NSP', X1 (one of the /*variable names)).
/*
/*Example
/*DATA A (TYPE=CORR);
/*LENGTH _TYPE_ $40;
/* INPUT _NAME_ $ _TYPE_$ X1 X2 ;
/* IF TRIM(LEFT(_TYPE_))='N' THEN CALL SYMPUT('NSP', X1);
/* CARDS;
/* . MEAN 70 160
/* . STD 8 25
/* . N 300 300
/* X1 CORR 1 0
/* X2 CORR 0 1
/* ;
/* RUN;
/*OUT random variables generated according to the file given in parameter DATA and observation identification number (ID)
/***************************************************************/
%MACROCONTINUOUS;
PROC CONTENTS DATA=A (DROP=_TYPE_ _NAME_)
OUT=_DATA_ (KEEP=NAME) NOPRINT;
RUN;
/*SUPPOSE WE HAVE X1,......, XP VARIABLE IN DATASET A WHICH IS AN INPUT DATASET.
WE ASSIGN THESE VARIABLES AS NAME OF V1,..., VP MACRO REFERENCE OF &NV IS ASSIGNED THE NUMBER OF TOTAL VARIABLES*/
DATA _DATA_;
SET _LAST_ END=END;
RETAIN N 0;
N=N+1;
V=COMPRESS('V' || COMPRESS(PUT (N, 6.0)));
CALL SYMPUT(V, NAME);
IF END THEN CALL SYMPUT('NV', LEFT(PUT (N, 6.0)));
RUN;
%LET VNAMES=&V1;
%DO I=2%TO&NV.;
%LET VNAMES=&VNAMES &&V&I;
%END;
/*OBTAIN THE MATRIX OF FACTOR PATTERNS AND OTHER STATISTICS.*/
PROC FACTOR DATA=A NFACT=&NV NOPRINT
OUTSTAT=PATTERN_(WHERE=(_TYPE_ IN('MEAN','STD','N','PATTERN')));
RUN;
DATA _PATTERN_;
SET COEFF PATTERN_;
RUN;
/*GENERATE THE RANDOM NUMBERS.*/
%LET NV2=%EVAL(&NV.*&NV.);
%LET NV3=%EVAL(3*&NV.);
DATA B&REPEAT. (KEEP=&VNAMES);
SET _PATTERN_ (KEEP=&VNAMES _TYPE_ RENAME=(
%DO I=1%TO&NV;
&&V&I = V&I
%END;
)) END=LASTFACT;
RETAIN;
/*SET UP ARRAYS TO STORE THE NESSESARRY STATISTICS.*/
ARRAY VCOEFF(3,&NV) C1-C&NV3;
ARRAY FPATTERN(&NV,&NV) F1-F&NV2;
ARRAY VSTD(&NV) S1-S&NV;
ARRAY VMEAN(&NV) M1-M&NV;
ARRAY V(&NV)V1-V&NV;
ARRAY VTEMP(&NV)VT1-VT&NV;
LENGTH LBL $40;
/* READ AND STORE THE MATORIX OF FACTOR PATTERNS. */
IF _TYPE_='PATTERN' THEN DO;
DO I=1 TO &NV;
FPATTERN(_N_ -6, I)=V(I);
END;
END;
IF _TYPE_='COEFF' THEN DO;
DO I=1 TO &NV;
VCOEFF(_N_,I) =V(I);
END;
END;
/* READ AND STORE THE MEANS */
IF _TYPE_ = 'MEAN' THEN DO;
DO I=1 TO &NV;
VMEAN(I)=V(I); END;
END;
/* READ AND STORE THE STD. */
IF _TYPE_ = 'STD' THEN DO;
DO I=1 TO &NV;
VSTD(I) =V(I); END;
END;
/* READ AND STORE THE NUMBER OF OBSERVATIONS.*/
IF _TYPE_ = 'N' THEN NNUMBERS=V(1);
IF LASTFACT THEN DO;
/* SET UP LABELS FOR THE RANDOM VARIABLES. THE LABELSARE STORED IN MACRO VARIABLES LBL1, LBL2,.... AND USED IN THE SUBSEQUENT PROC DATASETS.*/
%DO I=1%TO&NV;
LBL="ST.NORMAL VAR. ,M-"||COMPRESS(PUT(VMEAN(&I), BEST8.))||",STD="||COMPRESS(PUT(VSTD(&I),BEST8.));
CALL SYMPUT("LBL&I",LBL);
%END;
DO K=1 TO NNUMBERS;
DO I =1 TO &NV;
SEED=(&SEED.+&REPEAT.+1);
VTEMP(I)=RANNOR(SEED);
END;
/* IMPOSE THE INTERCORRELATION ON EACH VARIABLE. THE
TRANSFORMED VARIABLES ARE STORED ARRAY 'V'.*/
DO I=1 TO &NV;
V(I)=0;
DO J=1 TO &NV;
V(I) = V(I) + VTEMP(J)*FPATTERN(J, I);
END;
END;
/* TRANSFORM THE RANDOM VARIABLES SO THEY HAVE
MEANS AND STANDARD DEVIATIONS AS REQUESTED. */
DO I=1 TO &NV;
V(I)= VCOEFF(2, I)*(-1)+V(I)*VCOEFF(1, I) +VCOEFF(2,I)*V(I)*V(I)+VCOEFF(3, I)*V(I)*V(I)*V(I);
V(I) = VSTD(I) *V(I) + VMEAN(I);
END;
OUTPUT;
END;
END;
RENAME
%DO I=1%TO&NV;
V&I = &&V&I
%END;
;
RUN;
DATA BB&REPEAT.;
SET B&REPEAT.;
ID=_N_;
FORMAT ID;
RUN;
%MEND CONTINUOUS;
/***************** HISTGRAM and RATIO *************************/
/* This program generate random variables as in Figure 1 based on a Uniform /*distribution. % macro RATIO is executed in % macro HISTGRAM.
/*%Macro HISTGRAM
/*Parameters
/*SEED= seed of the random number
/*N_REPEAT= the number of iterations
/*NSP= total sample size, which is already defined as an input parameter of the DATA /*file used to execute %macro CONTINUOUS.
/*MAX=Maximum value of an original variable
/*MIN=Minimum value of an original variable
/*SUB_GROUP= the number of subgroups
/*OUT
/*The name of the output file (name of HH&REPEAT) containing the random variable, /*H1 and ID number.
/*
/*%RATIO assigns the frequencies of each subgroup, using an IF function.
/*&NSP.*0.55 = (sample size × accumulated percentage)=frequencies of subgroup.
/*Example IF 1=< ID <&NSP.*0.55 THEN _H1=U1;
/*U1 indicates random number for the lowest subgroup.
/**************************************************************/
%MACROHISTGRAM;
DATA HH&REPEAT.;
DO ID=1 TO &NSP.;
CALL STREAMINIT(&REPEAT. + &NSP. + &SEED. + 2.);
SCALE=%EVAL((&MAX.-&MIN.)/&SUB_GROUP.);
%DO I=1%TO&SUB_GROUP.;
_U&I.=RAND("UNIFORM");
U&I.=&MIN.+(&I.-1)*SCALE+SCALE*_U&I.;
%END;
%RATIO;
OUTPUT;
END;
RUN;
%MEND HISTGRAM;
%MACRORATIO;
IF 1=
ELSE IF &NSP.*0.55 =
ELSE IF &NSP.*0.6 =
ELSE IF &NSP.*0.8=
ELSE _H1=U5;
H1=INT(_H1);
IF H1=<4 THEN C1=0;
ELSE IF 4< H1 =<15 THEN C1=1;
ELSE IF H1 >15 THEN C1=2;
%MEND RATIO;
/************************** PDF ***********************************/
/*This macro generates random variables from the RAND function.
/*RAND function generates random numbers with certain probability distributions.
/*Parameter
/*SEED= seed of the random number
/*N_REPEAT= the number of iterations
/*NSP= total sample size, which is already defined as an input parameter of the DATA file used to execute %macro CONTINUOUS.
/*RAND function.
/*OUT
/*The name of the output file (name of CC&REPEAT) containing the random variable /*defined by the probability distributions given by the RAND function and ID number.
/**************************************************************/
%MACROPDF;
DATA CC&REPEAT.;
DO ID=1 TO &NSP.;
CALL STREAMINIT( &REPEAT. + &NSP. + &SEED. + 3);
STRATA=&REPEAT.;
UN=RAND("UNIFORM");
/*INSERT RAND FUNCTION TO GENERATE RANDOM NUMBER USING RAND FUNCTION*/
X=RAND("NORMAL", 0,1);
_D1=RAND("TABLE", 0.5 , 0.5);
IF _D1=1 THEN D1=0;
ELSE IF _D1=2 THEN D1=1;
OUTPUT;
END;
%MEND PDF;
/********************** Merge ***************************/
/*This program merges all datasets including randomly generated variables specified /*in %macro CONTINUOUS (BB&REPEAT), %HISTGRAM (HH&REPEAT) /*and %macro PDF(CC&REPEAT) by ID number.
/*OUT file name of _D&REPEAT.
/**************************************************************/
%MACRO MERGE;
PROC SORT DATA=BB&REPEAT.; BY ID; RUN;
PROC SORT DATA=HH&REPEAT.; BY ID; RUN;
PROC SORT DATA=CC&REPEAT.; BY ID; RUN;
DATA _D&REPEAT.;
MERGE BB&REPEAT. CC&REPEAT. HH&REPEAT.;
BY ID;
RUN;
DATA DATASET0;
SET DATASET0;
DATA DATASET&REPEAT.;
SET DATASET%EVAL(&REPEAT. -1) _D&REPEAT.;
RUN;
%MEND MERGE;
/*************************** OUTCOME ***************/
/*This program generates outcome variable, y, from the individual probability of event /*occurrence. Individual probability is calculated using two segment logistic regression /*model.
/*Parameter
/*CHANGE_POINT= flexion point of two segment logistic regression model
/*MODEL_1 = logistic regression model when values of covariates ?values of /*CHANGE_POINT
/*MODEL_2 = logistic regression model when values of covariates > values of /*CHANGE_POINT
/*NITER= number of final datasets
/*P = event proportion
/*OUT DATASET For logistic regression model
/********************************************************************/
%MACROOUTCOME;
DATA _D_&NITER.;
SET DATASET&NITER.;
%IF H1 =<&CHANGE_POINT.%THEN%DO;
G=&MODEL_1;
%END;
%IF H1 >&CHANGE_POINT.%THEN%DO;
G=&MODEL_2;
%END;
RUN;
PROC SUMMARY DATA=_D_&NITER.;
VAR G;
OUTPUT OUT= PROCMEAN&NITER. MEAN=;
RUN;
DATA M&NITER. (KEEP=INT ID NITER);
SET PROCMEAN&NITER.;
DO ID=1 TO &NSP;
MEAN=%SCAN(G, 1);
INT=LOG(&P/(1-&P))-MEAN;
NITER=&NITER.;
OUTPUT;
END;
RUN;
PROC SORT DATA=M&NITER.;BY ID;RUN;
PROC SORT DATA=_D_&NITER.;BY ID;RUN;
DATA D_&NITER.;
MERGE M&NITER. _D_&NITER.;
BY ID;
RUN;
DATA D&NITER. ;
SET D_&NITER.;
PRO=EXP(INT+ G)/(1 +EXP(INT+ G));
IF 0=
ELSE Y=0;
RUN;
PROC SORT DATA=D&NITER. ;BY STRATA;RUN;
%MEND OUTCOME;
/********************************************************************/
/*This program performs a stratified continuous logistic regression model and produces a repeated number of parameters (coefficient, its standard error, and p value), then calculates the average coefficient value, average standard error, and power.
/*Parameter
/*NITER=number of final datasets
/*CONTI_MODEL=a continuous logistic regression model
/*ALEVEL=significance level of the statistical test (Type I error)
/*NITER=specify final dataset
/*PATH=directory in which results are saved
/*TABLE=table name for saved results
/*OUT=Result (excel format)
/*Results include event proportion, mean, standard deviation, skewness, and kurtosis of a variable average coefficient and average standard error of logistic regression model and power
/********************************************************************/
%MACROCONTINUOUSLR;
/****MODEL**********************************************************/
ODS OUTPUT PARAMETERESTIMATES=PARAM CONVERGENCESTATUS=STATUS;
PROC LOGISTIC DATA=D&NITER. ;
MODEL Y (EVENT='1')=&CONTI_MODEL
/TECH=NR MAXITER=8 XCONV=0.01 ;
BY STRATA;
RUN;
/******************************************************************/
PROC SORT DATA=PARAM
OUT=PARAM2
(RENAME=(ESTIMATE=ESTIMATION STDERR=STANDARDERRORS));
BY STRATA;
RUN;
PROC SORT DATA=STATUS;
BY STRATA;
RUN;
DATA RESULT;
MERGE PARAM2 STATUS ;
BY STRATA;
RUN;
DATA RESULT_CONTINUOUS E;
SET RESULT;
IF 0=< PROBCHISQ<&ALEVEL. THEN POWER=1;
ELSE POWER=0;
IF STATUS=0 THEN OUTPUT RESULT_CONTINUOUS;
ELSE OUTPUT E;
RUN;
ODS HTML PATH="&PATH" BODY="&TABLE..XLS";
PROC TABULATE DATA=D&NITER. OUT=J;
VAR Y &CONTI_MODEL;
TABLE (&CONTI_MODEL)*(MEAN STD SKEWNESS KURTOSIS)/MISSTEXT = 'NO DATA';
RUN;
PROC FREQ DATA=D&NITER;
TITLE 'PROPORTION';
TABLE Y/NOCOL NOROW;
RUN;
PROC FREQ DATA=RESULT_CONTINUOUS;
TITLE 'POWER';
TABLE VARIABLE*(POWER)/NOCOL NOPERCENT;
RUN;
PROC TABULATE DATA=RESULT_CONTINUOUS;
TITLE 'MEAN OF COEFFICIENT AND THEIR MEAN OF STANDARD ERROR';
CLASS VARIABLE ;
VAR ESTIMATION STANDARDERRORS;
TABLE VARIABLE,(ESTIMATION STANDARDERRORS)*(N MEAN*F=8.4)/MISSTEXT = 'NO DATA';
RUN;
ODS HTML CLOSE;
%MEND CONTINUOUSLR;
/************************* CONTINUOUSLR ***************************/
/*Continuous variables are divided into categorical groups by quantile, and then a stratified logistic regression model is executed. Users specify the model in %MACRO CATEGORICAL_MODEL. Then, parameters (coefficient, standard error, and p value) and average coefficient values, average standard error of each group of a variable are calculated, and the power is calculated.
/*Parameter
/*R=Number of categorized groups
/*Example: Continuous=1, median=2, tertile=3, quantile=4,
/*CATEGORIZATION=%NRSTR(List of covariates to be categorized)
/*CATEGORIZATION_R=%NRSTR(List of new covariate names after /*categorization)
/*NITER=number of final datasets
/*CONTI_MODEL=a continuous logistic regression model
/*ALEVEL=significance level of the statistical test (Type I error)
/*NITER= specify final dataset
/*PATH=directory in which results are saved
/*TABLE=table name for saved results
/*OUT= Result (excel format)
/*Results include average coefficient and average standard error of logistic regression model and power for each categorized group and overall power of a variable.
/********************************************************************/
%MACROCATEGORICAL_MODEL;
ODS OUTPUT PARAMETERESTIMATES=PARAM_&R CONVERGENCESTATUS=STATUS_&R TYPE3=TYPE3_&R.;
PROC LOGISTIC DATA=G&R.;
CLASS C1(PARAM=REF REF="0") X1_R(PARAM=REF REF="0") ;
MODEL Y(EVENT='1')= C1 X1_R X2 /TECH=NR MAXITER=8 XCONV=0.01;
BY STRATA;
RUN;
%MEND CATEGORICAL_MODEL;
%MACROCATEGORICALLR;
PROC RANK DATA= D&NITER. GROUPS=&R. OUT=G&R.;
VAR &CATEGORIZATION;
RANKS &CATEGORIZATION_R ;
BY STRATA ;
RUN;
%CATEGORICAL_MODEL;
PROC SORT DATA=PARAM_&R
OUT=P_&R (RENAME=( ESTIMATE=ESTIMATION STDERR=STANDARDERRORS));
BY STRATA;
RUN;
PROC SORT DATA=STATUS_&R OUT =S_&R(KEEP = STRATA STATUS) ;
BY STRATA;
RUN;
PROC SORT DATA=TYPE3_&R OUT =_TYPE3_&R;
BY STRATA;
RUN;
DATA _POWER_&R;
MERGE _TYPE3_&R S_&R;
BY STRATA;
RUN;
DATA POWER_&R E_&R;
SET _POWER_&R;
RENAME;
TYPE3_WALDCHISQ=WALDCHISQ;
TYPE3_PROBCHISQ=PROBCHISQ;
LABEL TYPE3_PROBCHISQ="P VALUE OF TYPE3";
TYPE3_WALDCHISQ="CHISQ OF TYPE 3";
IF 0 =< TYPE3_PROBCHISQ <&ALEVEL. THEN POWER=1;
ELSE IF TYPE3_PROBCHISQ >= &ALEVEL. THEN POWER=0;
IF STATUS=0 THEN OUTPUT POWER_&R;
ELSE OUTPUT E_&R;
KEEP POWER STATUS TYPE3_WALDCHISQ TYPE3_PROBCHISQ EFFECT;
RUN;
DATA _RESULT_CATEGORICAL_&R;
MERGE P_&R S_&R;
BY STRATA;
RUN;
DATA RESULT_CATEGORICAL_&R E_&R;
SET _RESULT_CATEGORICAL_&R;
IF CLASSVAL0=. THEN CLASSLEVEL=0;
ELSE CLASSLEVEL=CLASSVAL0;
IF 0=< PROBCHISQ<&ALEVEL. THEN GROUP_POWER=1;
ELSE IF PROBCHISQ>= &ALEVEL. THEN GROUP_POWER=0;
DROP CLASSVAL0;
IF STATUS=0 THEN OUTPUT RESULT_CATEGORICAL_&R;
ELSE OUTPUT E_&R;
RUN;
ODS HTML PATH="&PATH" BODY="GROUP_&R._&TABLE..XLS";
PROC FREQ DATA=POWER_&R;
TITLE 'POWER OF Β';
TABLE EFFECT*(POWER)/NOCOL NOPERCENT;
RUN;
PROC TABULATE DATA= RESULT_CATEGORICAL_&R;
CLASS VARIABLE CLASSLEVEL;
VAR ESTIMATION STANDARDERRORS;
TABLE VARIABLE*CLASSLEVEL,(ESTIMATION STANDARDERRORS ) *(N MEAN*F=8.4) /RTS=20 MISSTEXT = 'NO DATA';
RUN;
PROC TABULATE DATA= RESULT_CATEGORICAL_&R;
CLASS VARIABLE CLASSLEVEL GROUP_POWER;
TABLE VARIABLE*CLASSLEVEL,( GROUP_POWER )*(N ROWPCTN) /RTS=20 MISSTEXT = 'NO DATA';
RUN;
ODS HTML CLOSE;
%MEND CATEGORICALLR;
/********************************************************************/
Dataset generation
One dataset is created from each iteration of %COEFF, %CONTINUOUS, %HISTGRAM, %PDF, and %MERGE.
This dataset is accumulated until the iterations are complete and the iteration time is identified as strata.
/********************************************************************/
%MACRO DATASET(N_REPEAT=);
%COEFF;
%DO REPEAT=1%TO&N_REPEAT.;
%CONTINUOUS;
%HISTGRAM
%PDF;
%MERGE;
%END;
%OUTCOME;
%MEND DATASET;
/********************************************************************/
The parameter estimations and statistical power calculation.
/********************************************************************/
%MACRO LR(R=);
%DO R=1%TO&R;
%IF&R=1%THEN%DO;
%CONTINUOUSLR;
%END;
%ELSE%DO;
%CATEGORICALLR;
%END;
%END;QUIT;
%MEND LR;
NOTES
*Corresponding author.