Equivalence between the Dependent Right Censorship Model and the Independent Right Censorship Model ()
Received 8 February 2016; accepted 9 April 2016; published 12 April 2016

1. Introduction
In this paper we study various dependent right censorship (RC) models and their relation to the independent RC model in the literature. The definitions of these RC models are given in Definition 1.
Right censored data occur quite often in industrial experiments and medical research. A typical example in medical research is a follow-up study; a patient is enrolled and has a certain treatment within the study period. If the patient dies within the study period, we observe the exact survival time T; otherwise, we only know that the patient survives beyond the censoring time R. Thus the observable random vector is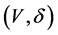 , where
, where
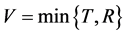 (
(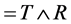 ) and
) and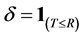 , the indicator function of the event
, the indicator function of the event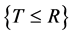 . Let
. Let 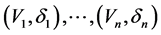
be i.i.d. copies of . Let
. Let 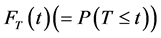 be the cumulative distribution function (cdf) of T and
be the cumulative distribution function (cdf) of T and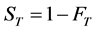 . Denote FR, FV and
. Denote FR, FV and 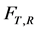 the cdf’s of R, V and
the cdf’s of R, V and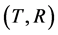 , respectively, and
, respectively, and 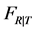 the conditional cdf of R given T and
the conditional cdf of R given T and . Let fT (fR or
. Let fT (fR or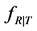 ) be the density function of T (R or
) be the density function of T (R or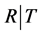 ) (with respect to (w.r.t.) some measure). The common right censorship model assumes T and R are independent (
) (with respect to (w.r.t.) some measure). The common right censorship model assumes T and R are independent (![]() ). Then the likelihood (function) for RC data is often defined as
). Then the likelihood (function) for RC data is often defined as
![]() (1)
(1)
(see [1] ), where ![]() is a collection of all cdf’s if under the non-parametric set-up, or a parametric cdf family with a parameter, say
is a collection of all cdf’s if under the non-parametric set-up, or a parametric cdf family with a parameter, say ![]() and
and ![]() is the parameter space,
is the parameter space, ![]() and f is the density of F. Recall that the formal definition of the likelihood (function) for a sample
and f is the density of F. Recall that the formal definition of the likelihood (function) for a sample ![]() is
is![]() ,
,![]() . More- over, if
. More- over, if ![]()
![]() , where
, where ![]() does not depend on θ, and Λ2 is also called a likelihood. We shall call Λ the full likelihood and Λ2 a simplified one. Since our sample
does not depend on θ, and Λ2 is also called a likelihood. We shall call Λ the full likelihood and Λ2 a simplified one. Since our sample![]() ,
,
![]() (2)
(2)
where
![]() (3)
(3)
and the integrals are Lebesgure integrals. We say that a function ![]() is non-informative about the function
is non-informative about the function ![]() with
with ![]() if it is not assumed that H is a function of
if it is not assumed that H is a function of ![]() or θ. We shall further clarify what “non- informative” means in the next example.
or θ. We shall further clarify what “non- informative” means in the next example.
Example 1.1. Consider 3 cases of right censoring:
Case (1). ![]() with the parameter space
with the parameter space ![]() (see Equation (1)).
(see Equation (1)).
Case (2). ![]() with
with![]() .
.
Case (3). ![]() with parameters
with parameters![]() ,
,![]()
![]() . FR is informative about
. FR is informative about
FT in cases (2) and (3), as it is a function of FT in case (2) and a function of ![]() in case (3). However, FR is non-informative (not informative) about FT in case (1), as FT and FR are both independent parameters.
in case (3). However, FR is non-informative (not informative) about FT in case (1), as FT and FR are both independent parameters.
If![]() , Λ in Equation (2) may be simplified as
, Λ in Equation (2) may be simplified as ![]() as in Equation (1) due to the non-informative property by the well-known result as follows.
as in Equation (1) due to the non-informative property by the well-known result as follows.
Proposition 1.1. The full likelihood ![]() can be simplified as
can be simplified as ![]() (see Equation (1)) iff
(see Equation (1)) iff
![]() (4)
(4)
Example 1.1 (continued). In case (1), ![]() is a likelihood function, as Equation (4) holds. In case (2),
is a likelihood function, as Equation (4) holds. In case (2), ![]() is informative about FT and condition Equation (4) fails.
is informative about FT and condition Equation (4) fails.
![]()
![]() is not a likelihood, but can be viewed as a partial likelihood. The generalized maximum likelihood (GMLE)
is not a likelihood, but can be viewed as a partial likelihood. The generalized maximum likelihood (GMLE)
![]() of ST based on
of ST based on ![]() is still the PLE, i.e.,
is still the PLE, i.e., ![]() , where
, where ![]() is the i-th order statistic of
is the i-th order statistic of![]() ’s and
’s and ![]() is the δj that is associated with
is the δj that is associated with![]() . The variance satisfies
. The variance satisfies ![]() (if ST is continuous), while the GMLE based on Λ is
(if ST is continuous), while the GMLE based on Λ is ![]() (as
(as ![]() and
and![]() ) and
) and ![]() by the delta method. Thus the PLE is not efficient. In case (3),
by the delta method. Thus the PLE is not efficient. In case (3), ![]() is not a likelihood function. The full likelihood is
is not a likelihood function. The full likelihood is ![]() (as
(as ![]() ). If one treats
). If one treats ![]() as a (partial) likelihood, then its GMLE of ST is the PLE
as a (partial) likelihood, then its GMLE of ST is the PLE![]() . Let
. Let![]() ,
,![]() . Then
. Then![]() , i.e., the PLE is not consistent at 2. The GMLE
, i.e., the PLE is not consistent at 2. The GMLE ![]() based on Λ is
based on Λ is![]() .
.
Remark 1.1. Example 1.1 indicates that if Equation (4) is not valid then the MLE based on so-called “likelihood” ![]() as in Equation (1) can be inconsistent, or can be less efficient than the MLE based on Λ due to loss of information on
as in Equation (1) can be inconsistent, or can be less efficient than the MLE based on Λ due to loss of information on![]() . However, it is difficult to verify Equation (4) in practical applications, thus people propose some sufficient conditions. A typical sufficient condition of Equation (4) is that
. However, it is difficult to verify Equation (4) in practical applications, thus people propose some sufficient conditions. A typical sufficient condition of Equation (4) is that ![]() and FR is non-informative about FT.
and FR is non-informative about FT.
Williams and Lagakos (W&L) [2] point out that ![]() is often un-realistic. They further propose a constant-sum model (which allows
is often un-realistic. They further propose a constant-sum model (which allows![]() ) as follows.
) as follows.
![]() (5)
(5)
where
![]() (6)
(6)
In the literature, there are many studies on the asymptotic properties of the PLE by weakening the assumptions in the independent RC model over the years (see, e.g., [3] - [10] ). It is conceivable that the asymptotic properties of the PLE is difficult under the continuous constant-sum model in Equation (5). However, the next theorem makes it trivial.
W&L Theorem (Theorem 3.1 in [2] ). W&L (1977)). Suppose that ![]() is a continuous random vector. Then Equation (5) holds iff
is a continuous random vector. Then Equation (5) holds iff ![]() a random vector
a random vector ![]() such that (1)
such that (1)![]() ,
, ![]() (see Equation (6)) and
(see Equation (6)) and![]() , where (2)
, where (2) ![]() if
if![]() , and (3)
, and (3) ![]() if
if![]() .
.
By the W&L Theorem, one can easily make use of the existing results about the PLE under the assumption ![]() to establish asymptotic properties of the PLE under the continuous constant-sum model. Indeed, by (2) and (3) of the W&L Theorem,
to establish asymptotic properties of the PLE under the continuous constant-sum model. Indeed, by (2) and (3) of the W&L Theorem,
![]() (7)
(7)
Since![]() , the PLE
, the PLE ![]() based on
based on ![]() from
from ![]() (see Equation (7)) satisfies
(see Equation (7)) satisfies
![]() a.s., where
a.s., where ![]() (see [10] ). By the W&L Theorem,
(see [10] ). By the W&L Theorem, ![]() and
and
Equation (7) holds, so ![]() under the continuous RC model given in Equation (5), even if
under the continuous RC model given in Equation (5), even if![]() .
.
On the other hand, case (3) in Example 1.1 shows that the PLE can be inconsistent for ![]() under a dependent RC model. Hence the W&L Theorem is quite significant. Yu et al. [11] show that the PLE is consistent under the dependent RC model considered in [12] - [15] , etc., which assumes A1 and A2 as follows.
under a dependent RC model. Hence the W&L Theorem is quite significant. Yu et al. [11] show that the PLE is consistent under the dependent RC model considered in [12] - [15] , etc., which assumes A1 and A2 as follows.
A1 ![]() for all r, or equivalently,
for all r, or equivalently, ![]() a.e. in t (w.r.t.
a.e. in t (w.r.t.![]() ) on the set
) on the set![]() .
.
Notice that ![]() is well defined if
is well defined if ![]() and undefined if
and undefined if![]() . We define
. We define ![]() if
if![]() . Notice that A1 says that
. Notice that A1 says that ![]() is constant in
is constant in![]() , thus
, thus ![]() is well defined if
is well defined if![]() .
.
A2 ![]() is non-informative about
is non-informative about![]() , with
, with![]() .
.
Definition 1. If ![]() and FR is non-informative about FT, then we call the RC model the independent RC model. The dependent RC model considered in this paper assumes that A1 and A2 hold.
and FR is non-informative about FT, then we call the RC model the independent RC model. The dependent RC model considered in this paper assumes that A1 and A2 hold.
Next example and Example 3.1 in Section 3 are examples that satisfies A1 but![]() .
.
Example 1.2.![]() ,
, ![]() and T has a binomial distribution (
and T has a binomial distribution (![]() ) with parameter
) with parameter![]() .
.
Yu et al. [11] show that A1 and A2 are the necessary and sufficient (N&S) condition of Equation (4) under the non-parametric set-up. Then we may ask the following questions:
1) Are A1 and A2 the N&S condition of Equation (4) under the parametric set-up?
2) What is the relation between the constant-sum model (5) and A1?
3) Can the W&L Theorem be extended by eliminating the continuity restriction?
We give answers to the 3 questions. In Section 2, we show that A1 and A2 are a sufficient condition for Equation (4) under both non-parametric set-up and non-parametric set-up (see Theorem 2.1). Our study suggests that the constant sum model (5) is a special case of A1. In Section 3, we extend the W&L Theorem to the case that A1 holds (rather than the case that Equation (5) holds), which allows ![]() being discontinuous. As a consequence, we establish the asymptotic normality of the PLE under the dependent RC model and under certain regularity conditions, making use of the existing results in the literature about the PLE under the independent RC model. In Section 4, we show that under the parametric set-up, A1 and A2 are not a necessary condition of Equation (4). Section 5 is a concluding remark. Some detailed proofs are relegated to Appendix.
being discontinuous. As a consequence, we establish the asymptotic normality of the PLE under the dependent RC model and under certain regularity conditions, making use of the existing results in the literature about the PLE under the independent RC model. In Section 4, we show that under the parametric set-up, A1 and A2 are not a necessary condition of Equation (4). Section 5 is a concluding remark. Some detailed proofs are relegated to Appendix.
2. The Relation between Equation (4), Equation (5) and A1
We shall first show that A1 and A2 are a sufficient condition of Equation (4), extending a result in [11] under the non-parametric set-up. Then we shall show that if ![]() is continuous, the constant sum model is the same as A1; otherwise, these two models are different.
is continuous, the constant sum model is the same as A1; otherwise, these two models are different.
Theorem 2.1. Equation (4) holds if A1 and A2 hold.
Proof. Since![]() , it is non-informative about FT by A2. Moreover, by A1
, it is non-informative about FT by A2. Moreover, by A1![]() . Thus
. Thus
![]() is non-informative about FT by A1 and A2, as
is non-informative about FT by A1 and A2, as ![]() and
and ![]() are equivalent. Then Equation (4) holds. ,
are equivalent. Then Equation (4) holds. ,
The next example and lemma help us to understand the constant-sum model (5).
Example 2.1. Suppose![]() ,
, ![]() and
and![]() . Then A1 holds, but not the constant-sum model assumption (5), as Equation (6) yields
. Then A1 holds, but not the constant-sum model assumption (5), as Equation (6) yields![]() , and
, and ![]() . Thus
. Thus![]() , violating Equation (5).
, violating Equation (5).
Lemma 2.1. ![]() and
and![]() , if
, if ![]() is continuous, where
is continuous, where
![]() .
.
Theorem 2.2. If ![]() is continuous, then A1 and Equation (5) are equivalent.
is continuous, then A1 and Equation (5) are equivalent.
The proofs of Lemma 2.1 and Theorem 2.2 are very technical but not difficult. For a better presentation, we relegate them to Appendix (see Section A.1 and Section A.2).
Remark 2.1. Example 2.1 shows that A1 is not a special case of Equation (5) (or the constant-sum model). However, if ![]() is continuous, A1 and the constant-sum model are equivalent. Thus the continuous constant-sum model is a special case of A1. Since Yu et al. [11] show that under the non-parametric set-up, A1 and A2 are the N&S condition that Equation (4) holds, it is desirable to extend W&L Theorem to the model that assumes A1 rather than the constant-sum model by eliminating the continuity assumption.
is continuous, A1 and the constant-sum model are equivalent. Thus the continuous constant-sum model is a special case of A1. Since Yu et al. [11] show that under the non-parametric set-up, A1 and A2 are the N&S condition that Equation (4) holds, it is desirable to extend W&L Theorem to the model that assumes A1 rather than the constant-sum model by eliminating the continuity assumption.
3. Extension of the W&L Theorem
In the next theorem, we extend the W&L Theorem from the continuous constant-sum model to A1.
Theorem 3.1. A1 holds iff there exist extended random variables Z and Y such that 1) ![]() and
and
![]() , where
, where![]() , 2)
, 2) ![]() if
if![]() , and 3)
, and 3) ![]() if
if![]() .
.
In our theorem, there are two modifications to the W&L Theorem.
1) Equation (5) with continuous ![]() is replaced by A1 without continuity assumptions.
is replaced by A1 without continuity assumptions.
2) The random vector is replaced by the extended random vector.
In fact, W&L Theorem is not accurate as stated, unless a random variable is allowed to take “values” ![]() (see Examples 3.1 and 3.2 below). However, by the common definition of a random variable, it does not take values
(see Examples 3.1 and 3.2 below). However, by the common definition of a random variable, it does not take values![]() . Thus the random variables in their theorem should be referred to the extended random variables.
. Thus the random variables in their theorem should be referred to the extended random variables.
Example 3.1. Suppose that ![]() and T has a uniform distribution
and T has a uniform distribution
![]() , then A1 holds and
, then A1 holds and ![]() is a continuous random vector, but
is a continuous random vector, but![]() . By Theorem 2.2, it satisfies the constant-sum model. Consequently, the assumptions in the W&L Theorem are satisfied. In particular, R does not take the value
. By Theorem 2.2, it satisfies the constant-sum model. Consequently, the assumptions in the W&L Theorem are satisfied. In particular, R does not take the value![]() . If the W&L Theorem were correct, according to their definition, there would be a random variable Y with a cdf
. If the W&L Theorem were correct, according to their definition, there would be a random variable Y with a cdf ![]() defined in Equation (6). However,
defined in Equation (6). However, ![]() for
for ![]() (the proof is given in Appendix (see Section A.3)).
(the proof is given in Appendix (see Section A.3)).
Thus ![]() is not a proper cdf as claimed in the W&L Theorem. Y should be modified to be an extended
is not a proper cdf as claimed in the W&L Theorem. Y should be modified to be an extended
random variable such that ![]()
Example 3.2. A random sample of complete data ![]() from T which has the exponential distribution
from T which has the exponential distribution ![]() can be viewed as a special case of the RC data. But
can be viewed as a special case of the RC data. But ![]() is not even defined for a random variable R. However, if we consider extended random variables in A1, that is, R may take values
is not even defined for a random variable R. However, if we consider extended random variables in A1, that is, R may take values![]() , then we can define
, then we can define![]() . Since
. Since![]() ,
,![]() . Thus Theorem 3.1 is trivially true in such case.
. Thus Theorem 3.1 is trivially true in such case.
Proof of Theorem 3.1. It suffice to show (Þ) part. Since ![]() is a conditional distribution,
is a conditional distribution, ![]() defines a “cdf” on
defines a “cdf” on![]() . Denote
. Denote ![]() and let
and let ![]() be the Borel s-field on Ω. Without loss of generality (WLOG), one can assume that
be the Borel s-field on Ω. Without loss of generality (WLOG), one can assume that ![]() is the probability space such that
is the probability space such that ![]()
![]() . Let W be the joint cdf defined by
. Let W be the joint cdf defined by ![]()
![]() . By the Kolmogorov consistency theorem,
. By the Kolmogorov consistency theorem, ![]() induces a random vector
induces a random vector ![]() on Ω by
on Ω by ![]()
![]() . Note that
. Note that ![]()
![]() and
and![]() . Verify that
. Verify that ![]() if
if![]() ;
; ![]() if
if![]() . Verify that
. Verify that ![]() as
as![]() . Thus con- ditions (1), (2) and (3) hold. ,
. Thus con- ditions (1), (2) and (3) hold. ,
Remark 3.1. In the previous proof, let ![]() be the support of
be the support of ![]() and
and![]() . Then
. Then ![]() may not be defined on A, but
may not be defined on A, but ![]() may be defined on A. Thus it is necessary to create a new random variable Z.
may be defined on A. Thus it is necessary to create a new random variable Z.
Corollary 3.1. If A1 holds then ![]() and
and![]() .
.
The asymptotic properties of the PLE under the continuous constant-sum model are obtained by making use of the W&L Theorem and the existing results in the literature on the PLE under the continuous independent RC
model. Denote ![]() The consistency of the PLE under assumption A1 is es-
The consistency of the PLE under assumption A1 is es-
tablished in the literature as follows.
Theorem 3.2 (Yu et al. [11] ). Under A1,![]() .
.
Now by Theorem 3.1 and Corollary 3.1, we can construct another proof of the consistency of the PLE as follows.
Corollary 3.2. Under A1, ![]() where
where
![]()
Proof. Yu and Li [10] show that if![]() , then
, then![]() , where
, where
![]() Under A1,
Under A1, ![]() may not be true, but by Theorem 3.1,
may not be true, but by Theorem 3.1,
![]() ,
, ![]() ,
,![]() . Thus the observation
. Thus the observation![]() ’s are i.i.d. from
’s are i.i.d. from![]() , which can be viewed as being generated from
, which can be viewed as being generated from![]() , as well as
, as well as![]() . Thus replacing
. Thus replacing ![]() and
and ![]()
by ![]() and
and![]() , respectively, in the previous equation yields
, respectively, in the previous equation yields![]() . Now
. Now
since![]() , the proof is done. ,
, the proof is done. ,
Remark 3.2. Notice that the statements in Theorem 3.2 is slightly different from the statements in Corollary 3.2. One is based on![]() , and the other is based on
, and the other is based on![]() .
.
The asymptotic normality of the PLE under A1 without continuity assumption has not been established in the literature. It can be done now by making use of Theorem 3.1 and the existing results in the literature on the PLE under the independent RC model. In particular, assuming T is continuous, Breslow and Crowley [3] and Gill [6] show that
![]() (8)
(8)
![]() (9)
(9)
Without continuity assumptions, Gu and Zhang [16] and Yu and Li [17] among others established asymptotic normality of the GMLE under the double censorship (DC) model. Since the independent RC model is a special
case of the DC model, their results imply that (8) and (9) also hold if ![]()
![]() , and if
, and if
either ![]() or
or![]() . The next result follows from Theorem 3.1 and Corollary 3.1, which partially solves the open problem in [11] about the asymptotic normality of the PLE under the dependent RC model.
. The next result follows from Theorem 3.1 and Corollary 3.1, which partially solves the open problem in [11] about the asymptotic normality of the PLE under the dependent RC model.
Theorem 3.3. Equations (8) and (9) are valid if A1 holds and if either T is continuous or (1)
![]()
![]() and (2) either
and (2) either ![]() or
or![]() , where the random variable Y is defined in Theorem 3.1.
, where the random variable Y is defined in Theorem 3.1.
4. Are A1 and A2 the N&S Condition of Equation (4) under the Parametric Set-Up?
The answer to the question is “No” in general. We shall explain through several examples.
Example 4.1. Suppose that![]() ,
, ![]() ,
, ![]() , and
, and
![]()
where ![]() and
and![]() . This defines a parametric family of dis- crete distribution functions FT. One can verify that possible observations Ii’s are
. This defines a parametric family of dis- crete distribution functions FT. One can verify that possible observations Ii’s are![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,![]() . Write
. Write![]() , then
, then ![]() is either Q or G in Equation (3). In particular,
is either Q or G in Equation (3). In particular, ![]() ,
, ![]() , which lead to
, which lead to
![]()
Thus the parametric model satisfies the N&S condition Equation (4). But in view of![]() , A1 fails. Note that the PLE maximizes
, A1 fails. Note that the PLE maximizes ![]() over
over![]() . It is important to notice that
. It is important to notice that ![]() with
with ![]() is not a likelihood. However,
is not a likelihood. However, ![]() with
with ![]() is a likelihood by Proposition 1.1. Ve-
is a likelihood by Proposition 1.1. Ve-
rify that the PLE of![]() , thus the PLE is not consistent,
, thus the PLE is not consistent,
but the MLE which maximizes ![]() over
over ![]() is consistent, as expected. In fact,
is consistent, as expected. In fact,
![]()
![]() yields
yields![]() .
.
![]() .
.
![]() .
.
![]() which is of the form
which is of the form![]() .
.
![]()
Then the MLE is the one that![]() . Verify that
. Verify that
![]() a.s.;
a.s.;
![]() a.s.;
a.s.;
![]() a.s.
a.s.
![]()
Since![]() , the MLE
, the MLE ![]() a.s. as expected. That is, the MLE of p based on
a.s. as expected. That is, the MLE of p based on ![]()
![]() is consistent.
is consistent.
Example 4.2. Suppose that ![]() and
and![]() . This specifies a parametric family of discrete distributions with parameter
. This specifies a parametric family of discrete distributions with parameter ![]() subject to the constraint
subject to the constraint ![]() and
and![]() . Then A1 and A2 are the N&S condition of Equation (4) (see Section A.4 in Appendix).
. Then A1 and A2 are the N&S condition of Equation (4) (see Section A.4 in Appendix).
Remark 4.1. In Example 4.1, since A1 fails, the W&L Theorem does not hold.
Both Examples 4.1 and 4.2 are parametric cases, but A1 and A2 are the N&S condition of Equation (4) only in one case. In both cases the MLE’s based on the simplified likelihood ![]() as in Equation (1) are consistent. They indicate that in general under the parametric set-up, A1 is not the necessary condition of Equation (4). Since the two examples are discrete case, we also discuss two continuous examples.
as in Equation (1) are consistent. They indicate that in general under the parametric set-up, A1 is not the necessary condition of Equation (4). Since the two examples are discrete case, we also discuss two continuous examples.
Example 4.3. Suppose that T is continuous,
![]() , and
, and![]() .
.
This defines a parametric family of a continuous random variable with parameter p. The possible observations Ii’s are ![]() and
and![]() . A1 is violated due to the table for
. A1 is violated due to the table for![]() . The
. The ![]() and
and ![]() in Equation (3). satisfy
in Equation (3). satisfy
![]()
![]()
Thus both Q and G in Equation (4) are not functions of p or FT and Equation (4) holds. Hence in this example, A1 is not a necessary condition of Equation (4).
Example 4.4. Suppose that ![]() and
and![]() . Define
. Define ![]() as in Exam-
as in Exam-
ple 4.3, then A1 fails and Equation (4) holds for the random vector![]() . Now define
. Now define
![]() ,
,![]() . Then
. Then ![]() does not satisfy A1 but Equation (4) holds.
does not satisfy A1 but Equation (4) holds.
It shows that if![]() , A1 is not a necessary condition of Equation (4) though Equation (4) can hold under proper assumptions on
, A1 is not a necessary condition of Equation (4) though Equation (4) can hold under proper assumptions on![]() . The idea can be extended to the other continuous parametric families e.g.,
. The idea can be extended to the other continuous parametric families e.g., ![]() , Weibull, Gamma etc.
, Weibull, Gamma etc.
5. Concluding Remark
We have established the equivalence between the standard RC model and the dependent RC model. The result simplifies the study on the properties of the estimators under the dependent RC model. The results in this paper may have applications in linear regression with right-censored data. For instance, the model assumption considered in [18] can be weekend. It is also of interest to study whether the result can be extended to the double censorship model [17] and the mixed interval censorship model [19] .
Acknowledgements
We thank the Editor and the referee for their valuable comments.
Appendix
We shall give the proofs of Lemma 2.1 and Theorem 2.2 and the proofs in some examples of the paper here.
A1. Proof of Lemma 2.1
WLOG, one can assume that u satisfies![]() . By Equation (6),
. By Equation (6),
![]() .
.
![]()
If T is a continuous random variable, then the previous equation and Equation (6) yield
![]() ,
,
A2. Proof of Theorem 2.2
Assume that ![]() is continuous. Then by Lemma 2.1, Equation (5) holds iff
is continuous. Then by Lemma 2.1, Equation (5) holds iff ![]() a.e. in u w.r.t.
a.e. in u w.r.t.![]() , iff
, iff ![]() a.e. in u w.r.t.
a.e. in u w.r.t.![]() .
.
Since ![]() is continuous,
is continuous,![]() . By Lemma 2.1,
. By Lemma 2.1,
![]() ,
,
where![]() . Thus, Equation (5) holds iff
. Thus, Equation (5) holds iff ![]() a.e. in u (w.r.t.
a.e. in u (w.r.t.![]() );
);
iff ![]() a.e. in u (w.r.t.
a.e. in u (w.r.t.![]() );
);
iff ![]() a.e. in u;
a.e. in u;
iff ![]() a.e. in u (w.r.t.
a.e. in u (w.r.t.![]() );
);
iff for almost all r (w.r.t.![]() ),
), ![]() is constant in t a.e. w.r.t.
is constant in t a.e. w.r.t. ![]() on
on![]() ;
;
iff![]() ,
, ![]() is constant in t a.e. w.r.t.
is constant in t a.e. w.r.t. ![]() on
on ![]() (which is A1). ,
(which is A1). ,
A3. Proof of the Equation ![]() for
for ![]() in Example 3.1
in Example 3.1
![]()
A4. Proof of Example 4.2
If ![]() is not constant a.e. (w.r.t.
is not constant a.e. (w.r.t.![]() ) in
) in![]() ,
, ![]() such that
such that
1)![]() ,
,
2) ![]() and
and![]() .
.
3) ![]() is fixed.
is fixed.
![]()
![]()
Thus![]() , contradicting
, contradicting ![]() by assumption (2). ,
by assumption (2). ,