Induction Motor Modeling Based on a Fuzzy Clustering Multi-Model—A Real-Time Validation ()
1. Introduction
Induction motors are the basis elements in industrial applications thanks to their economic cost, judicious size, and easy maintenance [1] [2] . However, these motors are complex and have a strongly nonlinear system. It is often hard to determine an adequate model that represents all the dynamic behavior of this machine.
Modeling is an essential initial step in the industrial process control. This fundamental step is necessary either for a control law development or for the development of a diagnosis procedure. Modeling a process consists in establishing relationships between its characteristics variables and in representing the dynamic behavior of this process in a particular field of operation.
Based on a priori knowledge of the studied process, many modeling types are used. The increasing complexity of industrial process pushes many researchers to develop modeling techniques that exploit linear systems tools. Hence, in this paper we will consider the modeling based on multimodel approach that recently, has been implemented in various science and engineering domains, concerning application to modeling, control and fault diagnosis [3] -[10] .
The multimodel approach consists in replacing the unique nonlinear model by a set of simpler linear models to create a model-base. Generally, each model of this base contributes to the whole description of the considered system through weighed functions or validities functions.
The modeling via this approach needs to follow up a scheme of four steps that are database acquisition, clustering, structural and parametric identification and fusion.
For clustering, many algorithms are adopted in literature [11] -[14] , in this paper we will focus on three fuzzy clustering algorithms that are subtractive, C-means and K-means clustering algorithms. The subtractive algorithm is used to determine the cluster number, whereas the C-means and the K-means will be exploited to generate the cluster centers then to construct the clusters. Thus, we will compare two modeling methods, the first is based on the association of subtractive-C-means algorithm and the second is based on the association of subtractive-K-means algorithm.
The two proposed modeling method are experimentally implemented to an induction motor.
The organization of this paper is as follows. The second part consists in describing the modeling with multi- model approach, the third part develops the application of the two modeling methods based on the two clustering algorithm to the induction motor. The part four is a comparative study of the two modeling method and finally the conclusion is in the fifth part.
2. Multi-Model Modeling
To obtain a multimodel, we have to follow a strategy of four stages that are database acquisition, data clustering, structural and parametric identification and local models fusion.
The system is considered as a black box. Thus, it is exited via a rich frequency input. The collected data is consisting of a set of input/output measurements. Then the collected data will be divided into N clusters through clustering algorithms. Later, three clustering algorithms will be developed: the subtractive, C-means and K-means algorithm. Next, structural and parametric identification follow the clustering to obtain the local models. The structural identification is achieved using the general procedure of order estimation and the Instrumental determinant ratio (IDR). For the parametric identification, the generalized recursive least square is implemented.
The obtained local models are combined through weighted functions that are calculated based on residue approach [5] -[8] .
Two strategies are adopted. The first is based on the C-means clustering algorithm and the second is based on K-means clustering method as shown in Figure 1 and Figure 2.
3. The Clustering Algorithms
Clustering data consists of organizing and collecting similar data points into group or cluster. The similarity is estimated by a function that computes the distance between the data points, usually, the Euclidean distance.
In literature, various clustering algorithm was proposed to deal with clustering problem [11] -[14] . Subtractive, C-means and K-means are among the most commonly-used clustering algorithm
3.1. Subtractive Clustering
The subtractive clustering algorithm was suggested by Chiu as an extension of the mountain function. It is able to determine the number and the value of cluster centers.
The process is provided with the following steps.
![]()
Figure 1. Modeling strategy based on C-means clustering algorithm.
![]()
Figure 2. Modeling strategy based on K-means clustering algorithm.
1) Each data point is considered as a cluster center that has the calculated potential pi given in (1).
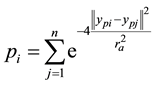 (1)
(1)
where ra defines the neighborhood radius.
The data with the high potential is the first cluster center.
2) The data potentials are recalculated by (2).
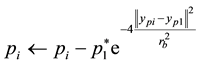 (2)
(2)
where rb > 0 is the new neighborhood radius that must be rather greater then ra to not having cluster centers that are closely spaced. Usually rb = 1.5ra.
3) The process is repeated until the obtaining of the k-th center and the potentials are recalculated by (3).
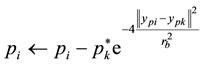 (3)
(3)
4) The process is repeated until the following condition (4).
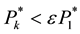 (4)
(4)
3.2. C-Means Clustering
The C-means known as FCM is a data clustering algorithm that considers that each data point belongs to a cluster through a membership function. It consists in producing an optimal partition by minimizing the objective function J on the basis of the following process.
1) Initialize arbitrarily the Fuzzy membership matrix µik
2) Calculate the cost function J by (5).
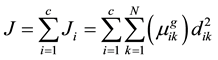 (5)
(5)
3) Estimate the clusters centers ci by the Equation (6).
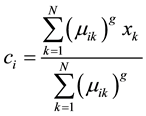 (6)
(6)
4) Updates the membership functions as the relation (7).
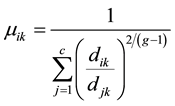 (7)
(7)
5) Recalculate the cost function J. If J is less than a threshold, the process will be ended. If not, return to step 3.
3.3. K-Means Clustering
The K-means clustering algorithm is known as an efficient and rapid one. It is able to construct a fixed finite number of clusters by minimizing the Euclidean distance between the data and the equivalent cluster center.
The K-means clustering algorithm is detailed by the following process.
1) Select arbitrarily cluster centers ci from the training data set.
2) Calculate the membership matrix uij using the Equation (8).
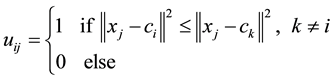 (8)
(8)
3) Calculate the cost function J by the Equation (9). Stop the process if it is less than a certain threshold.
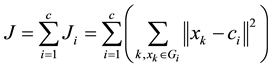 (9)
(9)
4) Update the cluster center ci according to the relation (10).
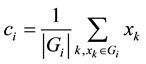 (10)
(10)
Next, return to step 2.
4. Application of the Two Modeling Strategy on the IM
We propose in this section to modeling the IM by the two multimodel modeling strategies previously described.
Firstly, we have to collect a rich data base from the measurement of input/output of the IM. The electric motor is 1 kw squirrel cage Induction motor.
The training data set is generated through an experimental set-up that is described by Figure 3. It is used with the help of Matlab/Simulink and DSpace system with DS1104 controller board to collect the database.
The data collection requires the use of speed and current sensors. For that, Hall type sensors are exploited to measure stator currents and an incremental encoder position sensor delivering 1024 pulses per revolution is mounted on the shaft to measure the IM speed.
To test the robustness of the modeling approach we propose to vary the IM parameter and to apply a wide range of loads.
The load is a resistive bank fed by a DC generator that is connected to the IM.
To vary the stator resistances, three variable resistors are linked in series to the motor phases.
A large data set is selected out after input/output measurements at an operating point of 600 rpm.
4.1. Modeling of IM via the Method Based on C-Means Clustering Algorithm
The subtractive clustering algorithm helps to determine the clusters number that is N = 8. So, the objective of the C-means clustering is to generate these eight clusters.
The obtained clusters will be identified to obtain the local models that are defined by these recurrent equations.
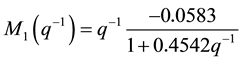 (11)
(11)
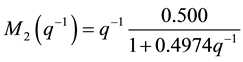 (12)
(12)
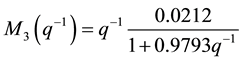 (13)
(13)
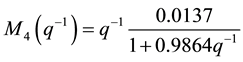 (14)
(14)
![]() (15)
(15)
![]() (16)
(16)
![]() (17)
(17)
![]() (18)
(18)
The combination of the local models through the validities shown in Figure 4 helps to construct the final multimodel as shown in Figure 5.
4.2. Modeling of IM via the Method Based on K-Means Clustering Algorithm
The same modeling process is respected. In fact, the K-means clustering is applied in order to generate the eight clusters that will be identified and combined to create the multimodel.
The local models are described by the following discrete transfer functions (19)-(26).
![]() (19)
(19)
![]() (20)
(20)
![]() (21)
(21)
![]()
Figure 5. Multimodel modeling of IM based on C-means.
![]() (22)
(22)
![]() (23)
(23)
![]() (24)
(24)
![]() (25)
(25)
![]() (26)
(26)
The obtained results are illustrated by Figure 6 that illustrates the evolution of the real speed and the modeled speed.
The different validities functions are illustrated by Figure 7.
![]()
Figure 6. Multimodel modeling of IM based on K-means.
![]()
Table 1. Comparative study of the two modeling strategies.
We propose to compare the two modeling strategies. Therefore, we calculate for each strategy the normalized roots mean square modeling error NRMSE. Then, a comparative table (Table 1) is dressed.
We can notice that the method based on K-means clustering algorithm is the most convergent as the NRMSE calculated is the lowest.
5. Conclusion
In this paper, the multimodel modeling strategy is described. Two strategies are developed. The first is on the basis of C-means clustering algorithm and the second is based on K-means clustering algorithm. The two methods are applied in real time to an induction motor at an operating point of 600 rpm submissive to load insertion and parameter variation. A comparative study helps to confirm that the method based on K-means is the most convergent. In future work, to improve the modeling performance the modeling should take into account the total behavior of the induction motor.