Detection of Stego-Images in Communication among the Terrorist Boko-Haram Sect in Nigeria ()
1. Introduction
The awareness of insecurity in Nigeria has placed an increasing focus on the need for security of life and properties. According to [1] , terrorists are now communicating using steganographic means via the Internet. In Nigeria, the Boko Haram Sect also uses similar methods as a means of communicating and sending messages to one another, and they are working with different cyber security expert who are developing a secure steganography system for them [2] . The group proposes to use the means to communicate to each other on the next place of attack which can be in a form of images, video and audio. The term of “steganography” emanated from the Greek, meaning “covered or hidden”. Steganography itself is the art of hiding and transmitting data through apparently innocuous carriers in an effort to conceal the existence of the data. Steganography is the technology of embedding hidden messages. This technique involves sending information to the recipient in a hidden way. The message hiding process can be done to any type of images, such as BMP, GIF and JPEG images. The messages are concealed in such a way that they are hardly noticed. The purpose of steganography is to covert communication to hide messages from a third party [3] .
The art of discovering the existence of steganographic data or secret message in an object is called steganalysis. It also refers to as the body of techniques that is designed to distinguish between cover-objects and stego- objects [4] . According to [4] , none of the steganographic systems that are known today achieves perfect security, and by this means they all leave hints of embedding in the stegogramme. This gives the steganalyst a useful way to identify whether a secret message exists or not. The major objective of steganalysis is to detect steganography method irrespective of its embedding mechanism. Therefore, universal blind steganalysis is not restricted to a particular algorithm or a class of algorithm [5] .
This paper presents an efficient method in detecting steganographic data by employing Image Quality Metrics (IQM) as a means of feature extraction and Logistic Regression analysis for classification. One advantage of this project is that it is able to provide solution to some of steganalysis problems in terms of testing algorithm against payload stego-images and various categories of images such as animals, fruits and natural scenes. Also, the system is able to detect presence of hidden message in cover signal. Another advantage is that the system is able to predict accurately any suspected images irrespective of the algorithm used in embedding process due to the fact that the system is trained with different embedding algorithms, for example, LSB, F5 etc.
2. Related Work
The research on steganalysis started in the late 90’s. The idea to use a trained classifier to detect data hiding was first introduced in a paper by [6] . In the paper, image quality metrics were proposed as features and the method was tested on several robust watermarking algorithms as well as Least Significant Bit (LSB) embedding. The work done in [7] described a different set of features based on binary similarity measures between the LSB plane and the second LSB plane capitalizing on the fact that most steganographic schemes use the LSB of image elements as the information-carrying entity. A feature-based steganalysis method for JPEG an image was des- cribed and used as a benchmark for comparing JPEG steganographic algorithms and evaluating their embedding mechanisms. The detection method was a linear classifier trained on feature vector corresponding to cover and stego images [8] . The research work in [9] indicated that in general no single feature is capable of differentiating stego and plain images effectively and a combination of features extracted in different domain will be generally more promising.
In [10] features from higher-order moments of distribution of wavelet coefficients and their linear prediction errors from several high-frequency sub-bands were constructed. The same authors also showed that SVMs generally provide better performance as classifiers compared to linear classifiers. Other authors have investigated the problem of blind steganalysis using trained classifiers [11] . Many steganalysis researchers attempt to categorize steganalysis attacks to recover modify or remove the message, based on information available [12] .
Dual statistics steganalytic method for detection of LSB embedding in uncompressed formats was introduced in [13] . For high quality images taken with a digital camera or a scanner, the dual statistics steganalysis indicated that the safe bit-rate is less than 0.005 bits per sample, providing a surprisingly stringent upper bound on steganographic capacity of simple LSB embedding.
A universal blind detection scheme that can be applied to any steganographic scheme after proper training on databases of original and cover-images was introduced in [14] . The author used an optimal linear predictor for wavelet coefficients and calculates the first four moments of the distribution of the prediction error. Fisher linear discriminant statistical clustering was used to find a threshold that separates stego-images from cover-images. The work demonstrated the performance on J-Steg, both versions of Outguess, EZ Stego, and LSB embedding. It appeared that the selected statistics was rich enough to cover a very wide range of steganographic methods. However, the results were reported for a very limited image database of large, high-quality images, and it is not clear how the results will scale to more diverse databases.
A blind steganalysis method was presented in [15] , which was based on statistical moments of wavelet histogram characteristic functions and Bayes classifier. Experimental results indicated that the method worked better for LSB, spread spectrum like steganography, F5 and Outguss steganography methods. A universal digital approach to steganalysis for detecting the presence of hidden message embedded within digital images was described in [16] . It was shown that within multiscale, multiorientation image decompositions (e.g. Wavelets), first- and higher-order magnitude and phase statistics were relatively consistent across a broad range of images, but are disturbed by the presence of embedded hidden messages.
Another blind steganalysis method with high detection ratio was proposed based on best wavelet packet decomposition. However, the methods based on wavelet high order statistics could not perform very well on spatial domain steganography such as LSB steganography [17] .
Contourlet Based Steganalysis (CBS) was presented in [18] , which used statistical moments as well as the log errors between the actual coefficients and predicted coefficients of the contourlet transform as features for analysis. After feature extraction, a nonlinear SVM classifier was applied to classify cover and stego-images. This method converts the image into gray-scale and then processes it. CBS detection rate is very low when message is embedded in medium frequency sub-bands and this idea was used in [19] to develop a new contourlet based steganography algorithm. So if the algorithm in [19] is used to embed the message, then CBS [18] cannot detect successfully. Authors in [20] used steganalytic software Steg Detect in order to test a large sample of images that were downloaded using a web crawler from Usenet and eBay. He used a distributed dictionary attack on suspected stego-images, which were a very small percentages of the images tested, and wasn’t able to find any secret messages.
The modern steganography techniques places embedding changes in those regions of images that are hard to model and hence increasingly more complex statistical descriptors of covers that are required to capture a large number of dependencies among cover elements that might be disturbed by embedding.
Much works have been done in the literature but need for better and efficient method in term of high prediction rate for further development of steganalysis necessary. Therefore, this paper adopted IQM as a method for feature extraction technique.
3. Theoretical Framework
319 images were tested and analyzed. Messages were embedded to 169 gray scale images using four known steganography software which are VLS (Virtual Laboratory Steganography), with different embedding algorithms which enable our system to learn and predict accurately any suspected images irrespective of the algorithms used in their embedding process. Thereafter, feature extraction process took place and logistic regression is trained as the classifier to predict the stego-images. The table in the appendix showed the data analysis with IQM functions used for the images.
3.1. Training Process
The training process block diagram is as represented in Figure 1 below.
![]()
Figure 1. Block diagram of the training process.
From the block diagram, the training set is the features extracted using the image quality measures (IQM). X is the input features to the hypothesis that is, to the predicting equation while the output Y is the result generated from the predicting equation based on the input features. The result in this case is either 1 repre- senting stego-image or 0 representing cover image.
Let x(i) denote input variable i.e. extracted features;
Let y(i) denote output variable or the targeted variable;
y can only take on two values 0 and 1, that is; y! {0,1};
(x(i), y(i)) denote the training examples.
3.2. Steganalytic Classifier
Logistic regression analysis is used on the selected features generated through Image Quality Measures (IQM) to build an optimal classifier using a set of test images and an original image. The idea is that the distance between a two cover images is less than the distance between a cover image and a stego-image. That is
 (1)
(1)
where,
C represents Cover image;
Cd represents distortion of the cover image;
S represents a stego-image;
Sd represents distortion of the stego-image.
3.3. Logistic Regression
The focus here is on the binary classification problem in which y can take on only two values, 0 (cover-image) and 1 (stego-image). 0 is also called the negative class, and 1 the positive class, and they are sometimes also denoted by the symbols “−” and “+”.
Let the predicting equation, that is, the hypothesis be denoted as hiQxV, which is written as
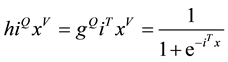 (2)
(2)
where  is called the logistic function or the sigmoid function. i denotes the learning parameters.
is called the logistic function or the sigmoid function. i denotes the learning parameters.
T is the intercept from the linear regression equation added to the regression coefficient multiplied by some value of the predictor x.
4. Case Processing Summary
The features extracted from 150 cover images and 169 stego-images were trained on Logistic Regression classifier using SPSS. Table 1 below shows the result of the training process.
Table 2 shows the variable(s) entered in Step 1 (Table 3): MSR, PSNR, MNC, AD, SC, MD, NAE, SD.
Structural Content (SC) defines the closeness between two images can be quantified in terms of correlation function. These measures measure the similarity between two images; hence in this sense they are complemen- tary to the difference-based measures.
 (3)
(3)
where M and N are the dimension of the image,  is the original image and
is the original image and  is the distorted image
is the distorted image
MSE is the Mean Square Error. It is defined as
 (4)
(4)
where M and N are the dimension of the image,  is the original image and
is the original image and 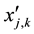 is the distorted image.
is the distorted image.
AD is the Average Difference, given by
![]()
Table 1. Result of the training process.
![]()
Table 2. Variables in the equation.
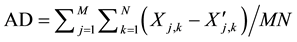 (5)
(5)
where M and N are the dimension of the image,  is the original image and
is the original image and ![]() is the distorted image.
is the distorted image.
PSNR is Peak Signal to Noise Ratio. It is used to find the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. PSNR is commonly used to measure the quality of reconstruction of lossy compression codecs especially for image compression. PSNR is given by
![]() (6)
(6)
MD is the Maximum Difference, given by
![]() (7)
(7)
SD is the Spectral Distance, while NAE is the Normalized Absolute Error, given by
![]() (8)
(8)
Estimation terminated at iteration number 20 because maximum iterations have been reached. Final solution cannot be found.
Hypothesis
General hypothesis (predicting equation)
![]() (9)
(9)
The hypothesis generated from the trained data is
![]() (10)
(10)
The above equation is the predictive equation.
5. Result
The result after testing the system with 319 images is shown in Table 4 below.
The result of the testing in Table 4 show that the system achieved 58.9% detection rate, despite training the system with a low images (319) compare to [3] that was trained with 12,200 images. This means if the system was trained with more images, it will achieve very high prediction rate.
The result of this research work is compared with work done in [16] and [8] and the results are presented below in Table 5.
The result of the table above show that the system implemented in this project has a high prediction rate compare with WBS [16] and FBS [8] .
6. Summary and Conclusion
The approach in this method has provided an easy method for steganalysis and robustness in terms of testing the system against different payload stego-images. We are able to show the effectiveness of the method by conducting test and analysis with 319 images varying in size and style. Messages are embedded to 169 gray scale images using four known steganography softwares which are VLS (Virtual Laboratory Steganography), SecretLayer, QuickStego and OpenStego with different embedding algorithms which enable our system to learn and predict accurately any suspected images irrespective of the algorithms used in their embedding process. Thereafter, feature extraction process takes place and logistic regression is trained as the classifier to predict the stego-images. Finally, our method is able to achieve 58.9% detection rate, despite training the system with a low images (319) compare to existing methods with that were trained with 12,200 images. This means that our method is more efficient.
The output of this paper is recommended to Ministry of Defense to serve as part of reference effort necessary
![]()
Table 4. Testing result-classification table.
in curbing the Boko-Haram insurgency menace in the country.