Estimation of Regression Function for Nonequispaced Samples Based on Warped Wavelets ()
Received 21 December 2015; accepted 20 February 2016; published 23 February 2016

1. Introduction
In nonparametric regression, it is often of interest to estimate some functionals of a regression function, such as its derivatives. For example, in the study of growth curves, the first (speed) and second (spurt) derivatives of the height as a function of age are important parameters for study (Muller [1] ). Other needs for derivative estimation often arise in nonparametric regressions themselves. For example, in constructing interval estimates for a re- gression function and kernel bandwidth selection (Ruppert and Wand [2] ), estimators of higher order derivatives are employed in estimating the leading bias terms. Suppose n independent variables 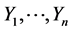 with
with
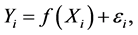
where 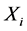 and
and 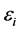 are independent random variables,
are independent random variables, 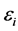 assumed to have normal distribution with mean zero and variance
assumed to have normal distribution with mean zero and variance 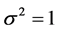 for simplicity. The
for simplicity. The 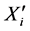 s have a density g which may be known or unknown, but assumed to be compactly supported on the interval
s have a density g which may be known or unknown, but assumed to be compactly supported on the interval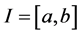 , as well as f. We aim to estimate
, as well as f. We aim to estimate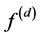 , that is, the dth derivative of f, for any integer d.
, that is, the dth derivative of f, for any integer d.
Considerable research has been devoted to the subject of estimation, mainly the kernel methods, see, e.g., [3] - [8] , the smoothing splines, and local polynomial methods, see, e.g., [9] -[11] . One may also be interested in more traditional approaches to nonparametric regression, mainly fixed-bandwidth kernel methods, orthogonal series methods and linear spline smoothers. These methods are not adaptive. The estimators based on these methods may achieve substantially slower rate of convergence if the smoothness of the underlying regression functions is misspecified. The recent development of wavelet bases based on multiresolution analyses suggests new techniques for nonparametric function estimation.Wavelet analysis plays important roles in both pure and applied mathematics such as signal processing, image compressing, and numerical solutions. The application of wavelet theory to the field of statistical function estimation is pioneered by Donoho and Johnstone. In a series of important papers (see, e.g., [12] - [15] ), Donoho and Johnstone and coauthors present a coherent set of procedures that are spatially adaptive and near optimal over a range of function spaces of inhomogeneous smoothness. They enjoy excellent mean squared error properties when are used to estimate functions that are only piecewise smooth and have near optimal convergence rates over large function classes.
Recently a quite different algorithm is developed by Kerkyacharian and Picard [16] . The procedure stays very close to the equispaced Donoho and Johnstone’s Visushrink procedure, and thus is very simple in its form and in its implementation. Simply, the projection is done on an unusual non-orthonormal basis, called warped wavelet basis. Assuming that g is known but with no boundedness assumptions on it, two new estimators have been introduced based on a warped wavelet basis. The features of this basis consist of a standard wavelet basis and of the definition of G related to the model. Of course, the properties of this basis truely depend on the warping factor G. Such a technique has been already used with success in the framework of nonparametric regression with random design by Kerkyacharian and Picard [16] . Recent works on warped wavelet basis in nonparametric statistics can be found in [17] -[20] . To the best of our knowledge, only Cai [21] and Petsa and Sapatinas [22] have proposed wavelet estimators for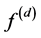 , but defined with a deterministic equidistant design; that is,
, but defined with a deterministic equidistant design; that is,
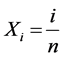 .
.
The consideration of a random design with warped wavelet complicates significantly the problem and no wavelet estimators for derivative of regression function exist in this case. This motivates us to study the case under different dependence structures: the strong mixing case and the r-mixing case. Asymptotic mean inte- grated squared error properties for derivatives of regression function has been explored. In each case, we prove that warped wavelet estimator attains a fast rate of convergence. Another important advantage of the warped basis estimators is that they are near optimal in the minimax sense over a large class of function spaces for a wide variety of design densities, not necessarily bounded above and below as generally required by other wavelet estimators. Basically, the condition on the design refers to the Muckenhoupt weights theory introduced in Muckenhoupt [23] .
The rest of the paper is organized as follows. Section 2 describes the warped wavelet basis and nonquispaced procedure. Optimality of the estimators will be presented in Section 3, while Section 4 contains proofs of the main results.
2. Assumptions
We aim to estimate derivative of regression function when 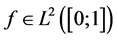 via n random variables (or vectors)
via n random variables (or vectors) 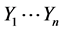 from a strictly stationary stochastic process
from a strictly stationary stochastic process 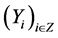 defined on a probability space
defined on a probability space![]() .
.
Condition 1. We define the m-th strong mixing coefficient of ![]() by
by
![]()
We define ![]() as the s-algebra generated by the random variables (or vectors)
as the s-algebra generated by the random variables (or vectors) ![]() and
and ![]() as the s-algebra generated by the random variables (or vectors)
as the s-algebra generated by the random variables (or vectors) ![]() We say that
We say that ![]() is strong mixing if and only if
is strong mixing if and only if![]() . Furthermore, there exict two constants
. Furthermore, there exict two constants ![]() such that, for any integer
such that, for any integer![]() ,
,
![]()
Applications on strong mixing can be found in [24] - [26] . Among various mixing conditions used in the literature, a-mixing has many practical applications. Many stochastic processes and time series are known to be a-mixing. Under certain weak assumptions autoregressive and more generally bilinear time series models are strongly mixing with exponential mixing coefficients. The a-mixing dependence is reasonably weak; it is satis- fied by a wide variety of models including Markov chains, GARCH-type models and discretely observed dis- cussions.
Condition 2. Let ![]() be a strictly stationary random sequence. For any
be a strictly stationary random sequence. For any![]() , we define the m-the maximal correlation coefficient of
, we define the m-the maximal correlation coefficient of ![]() by r-mixing:
by r-mixing:
![]()
3. Warped Basis and Estimation Framework
Let N be a positive integer. We consider an orthonormal wavelet basis generated by dilations and translations of a father Daubechies-type wavelet and a mother Daubechies type wavelet of the family db2N (see [27] ). Further details on wavelet theory can be found in Daubechies [27] and Meyer [28] . In particular, mention that 𝜙 and 𝝍 have compact supports. For any![]() , we set
, we set ![]() and for
and for![]() , we define
, we define ![]() and
and ![]() as father and mother wavelet:
as father and mother wavelet:
![]()
With appropriated treatments at the boundaries, there exists an integer ![]() such that, for any integer
such that, for any integer![]() ,
,
![]()
forms an orthonormal basis of![]() . For any integer
. For any integer ![]() and
and![]() , we have the following wave- let expansion:
, we have the following wave- let expansion:
![]()
where ![]() and
and![]() . Furthermore we consider the following wavelet sequential definition of
. Furthermore we consider the following wavelet sequential definition of
the Besov balls. We say![]() , with
, with![]() , and
, and ![]() if there exists a constant
if there exists a constant![]() , such that
, such that
![]()
with the usual modifications if ![]() or
or![]() . Note that, for particular choices of
. Note that, for particular choices of ![]() and
and ![]() con- tains the classical Holder and Sobolev balls. See, e.g., Meyer [28] and Hardle et al. [29] . Now we consider the wavelet basis
con- tains the classical Holder and Sobolev balls. See, e.g., Meyer [28] and Hardle et al. [29] . Now we consider the wavelet basis ![]() with
with ![]() and
and ![]() and
and ![]() have d derivatives, then the generalized expansion of deri- vative of f is
have d derivatives, then the generalized expansion of deri- vative of f is
![]() (3.1)
(3.1)
where the coefficients are
![]() (3.2)
(3.2)
and
![]() (3.3)
(3.3)
We define the linear wavelet estimator ![]() by
by
![]() (3.4)
(3.4)
where
![]() (3.5)
(3.5)
where ![]() is an integer a posteriori. For more on estimating of derivatives of density function see [30] and [31] . Kerkyacharian and Picard [16] propose a construction where the unknown function is expanded on a warped basis instead of a regular wavelet basis. Proceeding in such a way, the estimates of the coefficients become more natural. Let us briefly describe the construction of this procedure. Suppose
is an integer a posteriori. For more on estimating of derivatives of density function see [30] and [31] . Kerkyacharian and Picard [16] propose a construction where the unknown function is expanded on a warped basis instead of a regular wavelet basis. Proceeding in such a way, the estimates of the coefficients become more natural. Let us briefly describe the construction of this procedure. Suppose
![]()
is a known function, continuous and strictly monotone from ![]() to 0,1], then
to 0,1], then
![]() (3.6)
(3.6)
It is clear that the above estimator is unbiased and we perform the following warped estimator:
![]() (3.7)
(3.7)
In the case where g is unknown, we replace G wherever it appears in the construction by the empirical distribution of the Xi’s:
![]()
Let us define the new empirical wavelet coefficients:
![]() (3.8)
(3.8)
Consequently we have the estimator:
![]() (3.9)
(3.9)
This approach was initially introduced by Rao [32] for the estimation of the derivatives of a density. Note that, for m = 0 the standard case, this estimator has been considered and studied in Kerkyachariyan and Picard [16] .
4. Optimality Results
The main results of the paper are upper bounds for the mean inegrated square error of the wavelet estimator![]() , which is defined as usual by
, which is defined as usual by
![]()
Moreover, C denotes any constant that does not depend on l, k and n.
Proposition 4.1. Suppose that ![]() are independent. For any integer
are independent. For any integer ![]() and
and ![]() is unbiased estimator of
is unbiased estimator of ![]() and there exists a constant
and there exists a constant ![]() such that
such that
![]()
Proof of Proposition 4.1. We have
![]()
So ![]() is unbiased estimator of
is unbiased estimator of![]() . Therefore
. Therefore
![]() (4.1)
(4.1)
where
![]()
and
![]()
For upper bound of![]() , we have
, we have
![]()
Using the same technic as [19] and change of variables![]() , we obtain
, we obtain
![]() (4.2)
(4.2)
Considering almost the same integral as in![]() , and the fact
, and the fact![]() , we have
, we have
![]() (4.3)
(4.3)
It follows from (4.2), (4.3) and (4.1), that
![]()
Proposition 4.2. Suppose that the assumptions of Condition 1 hold. Let ![]() be (3.4). Then there exists C > 0 such that
be (3.4). Then there exists C > 0 such that
![]()
Proof of Proposition 4.2. Observe that
![]() (4.4)
(4.4)
where
![]()
and
![]()
It follows from the fact that![]() ,
,
![]() (4.5)
(4.5)
where
![]()
![]()
Using Proposition 6.1 in [33] , and the fact that![]() , we have
, we have
![]()
Therefore
![]() (4.6)
(4.6)
Applying the Davydov inequality for strongly mixing processes (see [34] ), for any![]() , we have
, we have
![]() (4.7)
(4.7)
Now we have ![]() and by (4.3),
and by (4.3),
![]() (4.8)
(4.8)
Hence by applying (4.7) and (4.8), we get
![]() (4.9)
(4.9)
It follows from (4.5), (4.6) and (4.9) that
![]() (4.10)
(4.10)
Now (4.10) with proposition 4.1 completes the proof.
Proposition 4.3. Suppose that the assumptions of Condition 2 hold. Let ![]() be (3.4). Then there exists a constant
be (3.4). Then there exists a constant ![]() such that
such that
![]()
Proof of Proposition 4.3. Having the same technique as in Proposition 4.2, we have
![]() (4.11)
(4.11)
Applying the covariance inequality for r-mixing processes (see Doukahn [25] ), i.e.,
![]()
We obtain from (4.2),
![]() (4.12)
(4.12)
Hence by
![]() (4.13)
(4.13)
So Proposition 4.3 is complete from (4.12) and (4.13).
Now based on the above Proposition, we have the following main result:
Theorem 4.1. Suppose that the assumptions of Section 2 hold. Let ![]() be (3.4). Suppose that
be (3.4). Suppose that ![]() and
and ![]() Then there exists a constant
Then there exists a constant ![]() such that
such that
![]()
where ![]() The rate of convergence corresponds to the one obtained in the derivatives density estimation framework. See, for example, Rao [32] and Chaubey et al. [30] [31] .
The rate of convergence corresponds to the one obtained in the derivatives density estimation framework. See, for example, Rao [32] and Chaubey et al. [30] [31] .
Proof of Theorem 4.1. Since we set ![]() an arthonirmal set in L[0,1], we have
an arthonirmal set in L[0,1], we have
![]()
As we define![]() , there exists a constant
, there exists a constant![]() , such that
, such that
![]() (4.14)
(4.14)
First consider the i.i.d case. Using (4.2) and (4.3) and the fact that![]() , one can easily have
, one can easily have
![]() (4.15)
(4.15)
Second, suppose the assumptions of Section 2 hold. Using Proposition 4.2 with![]() , we have
, we have
![]() (4.16)
(4.16)
Remark 4.1. Theorem 4.1 shows that, under mild assumptions on the dependence of observations, ![]() attains a rate of convergence close to the one for the i.i.d. case i.e.,
attains a rate of convergence close to the one for the i.i.d. case i.e.,![]() .
.
5. Conclusion
In this paper, we proposed a wavelet-based estimator for derivatives of regression function in the random design. The proposed estimator was formulated according to the warped basis which was simple and easy for applications. The results successfully revealed that without imposing too restrictive assumptions on the model, the wavelet-based estimator attained a sharp rate of convergence under strong mixing and ρ-mixing structures.
Acknowledgements
The author would like to express her gratitude to the referee and chief editor for their valuable suggestions which have improved the earlier version of the paper.